
Google翻译、百度翻译、有道翻译……我们使用过各种各样的在线翻译服务,但你清楚机器翻译背后的原理吗?在线翻译为什么要用深度学习?不同的神经网络模型在翻译过程中所起的作用有什么不同?
相比通用的模型,为什么支持103种语言的Google的翻译算法,可以实现任意两种语言之间的翻译转换?它独特的LSTM-RNN结构在其中所起的作用又是什么?让我们从头来学习一番。
作者|Daniil Korbut
译者|JeyZhang
图片来源:谷歌机器翻译算法
许多年前,想要对一种陌生的语言进行翻译是一件非常耗时的事情。采用简单的词匹配方法来进行翻译是很困难的,有两个原因:
读者不了解文本中用到的语法;
读者不可能为了翻译去学习所有的语言;
现在,翻译这件事情变得很简单了,只需要将待翻译的词组、句子甚至大篇幅的文本放进谷歌翻译的翻译框就能轻易得到翻译结果。然而,大多数人实际上并不关心机器翻译背后的原理。如果你想了解机器翻译的原理,这篇博文就是为你而准备的。
基于深度学习的机器翻译面临的问题
如果谷歌的翻译模型是针对非常短的文本进行翻译,那这个模型将很难起作用,因为短文本对应的翻译可能性太多了。最理想的情况是能够教会计算机各种的语法规则并基于这些语法规则来进行翻译,这听上去容易但实际很难。
如果你曾经尝试过学习一门外语,你就会知道其中有许多意想不到的语法规则。然而,当我们尝试在计算机程序中加入这些语法规则后,最终的翻译质量却会下降(翻译结果比较生硬)。
现代的机器翻译系统采用了一种新的方法:通过分析大量的语料数据,让系统从中自动地学习出相应的语法规则。
如果你能自己创建一个简单的机器翻译系统,这将成为你简历上的加分项目。
接下来我们一起来探索机器翻译系统这个“黑盒”的背后原理。深度学习模型能够在很多复杂的任务(例如语音识别/物体识别)上取得不错的结果,然而,许多深度学习模型存在一个限制条件,就是模型的输入和输出通常要求固定的维数(这对许多任务而言并不适合)。先来了解一下这些模型:
循环神经网络 (RNN)
下面讲讲LSTM (Long Short-Term Memory networks) 模型,这个模型能够处理变长的输入序列。
LSTM模型是一种特殊的循环神经网络 (RNN),能够捕捉和学习到长序列中的相关性。所有的RNN模型都是由相同的模型重复链式地组成的。

被展开的循环神经网络模型
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
因此,LSTM模型中数据是在模块和模块之间传输的。例如,为了生成最后的ht,我们不是只用到了Xt,而是用了X0,X1,X2,…,Xt等一系列作为输入。如果想要了解关于LSTM的模型结构和数学原理,可以去阅读《理解LSTM网络》这篇文章。
原文地址:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
双向RNN模型
接下来介绍双向循环神经网络模型 (BRNN)。BRNN模型由两个普通的RNN模型组成,只不过这两个RNN模型处理输入序列的方向是相反的,一个是处理正向的序列,一个是处理反向的序列。这两个序列的输出与相反方向的输入之间没有连接关系。
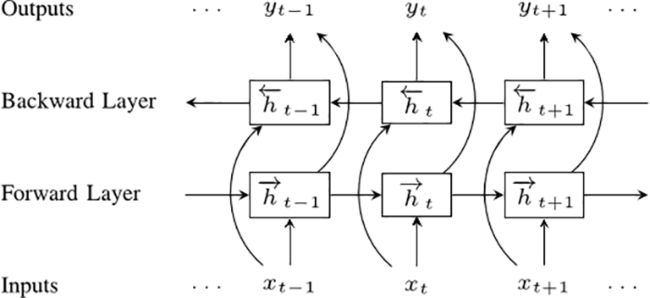
双向循环神经网络
https://www.semanticscholar.org/paper/Hybrid-speech-recognition-with-Deep-Bidirectional-Graves-Jaitly/5807664af8e63d5207f59fb263c9e7bd3673be79
为了理解BRNN模型为什么会优于单个RNN模型,这里举个例子,假设我们有一个包含了9个词的句子,我们希望预测句子中的第5个词是什么。一种情况是我们只知道了前4个词词,另一种情况既知道了前4个词也知道了后4个词,显然,后一种情况下能让我们的预测结果更加准确(因为我们得知了更多的信息)。
Seq2Seq (Sequence to Sequence) 模型
现在我们来看看seq2seq模型,基础的seq2seq模型由两个RNN模型组成:一个用于对输入序列进行编码,一个用于对输出序列进行解码。
Seq2Seq模型
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
这样我们也基于这个模型来实现一个翻译系统。
然而,我们还需要考虑一个小问题。谷歌翻译系统目前支持103种语言,因此我们应该有103×102种模型来处理其中任意两种语言之间的翻译,而这些模型的效果取决于翻译文本的热门与否和训练语料的数量。最理想的情况是只训练一种模型,这个模型能够将任意一种语言翻译成任意的另一种语言。
谷歌翻译算法
这个很棒的算法是谷歌的工程师在2016年底时提出的,采用了seq2seq模型框架(就是上面提及的那样)。
唯一的区别在于,模型的编码器和解码器之间有一个8层的LSTM-RNN结构,这种结构采用了部分连接(非全连接)的方式来改善模型的运行速度和效果。如果你想深入了解,可以阅读谷歌神经网络翻译系统这篇论文。
论文地址:
https://arxiv.org/abs/1609.08144
这个方法的核心在于,目前的谷歌翻译算法采用了一个统一的翻译系统,取代了数以万计的翻译子系统。
这个系统要求输入序列的开头是一个标志符,表示你希望翻译成的语言。
一种称为“Zero-Shot翻译”的方法既能够提升翻译质量,同时也能实现任意两种语言之间的翻译(可以是系统没有见过的语言)。
什么是更好的翻译?
当我们在谈及现在的谷歌翻译算法取得了更好的结果,我们是怎么评估新的算法取得的翻译效果更好的呢?
这件事情并不难做,因为对于一些比较常见的句子而言,我们已经有专业的翻译官给出的标准翻译答案。当然,对于同一个句子的翻译文本可能会有些差异。
有许多方法可以在一定程度上评估翻译质量的好坏,其中最常用和最有效的指标是BLEU(BilinguaL Evaluation Understudy)。假设我们有两个翻译器给出的候选结果,如下:
候选 1: Statsbot makes it easy for companies to closely monitor data from various analytical platforms via natural language.
候选 2: Statsbot uses natural language to accurately analyze businesses’ metrics from different analytical platforms.

上面的这两个候选结果的意思是一样的 ,但是所用到的语法结构和翻译质量存在不同。
让我们看看翻译人员给出的参照翻译结果:
参照结果1: Statsbot helps companies closely monitor their data from different analytical platforms via natural language.
参照结果2: Statsbot allows companies to carefully monitor data from various analytics platforms by using natural language.
很明显,以参照结果为标准,候选1的翻译质量更好,是因为相较于候选2,候选1从字面上和参照结果更为接近。BLEU指标的基本思想也是这样的,通过计算机器翻译的结果和参照结果的n-grams的匹配程度(忽略n-gram的相对位置信息)来衡量翻译质量(匹配的n-gram越多,翻译质量越好)。这里我们只考虑匹配的准确率,没有考虑召回率是因为参照结果比较多从而计算起来比较困难。
现在开始你也可以对复杂的机器翻译系统进行评估了。通过阅读了本文,等你下一次使用谷歌翻译时,你就能想象到在这个系统的背后,是分析了数以百万计的文档后才最终得到这样一个最佳的翻译结果。
原文链接:
https://blog.statsbot.co/machine-learning-translation-96f0ed8f19e4