| 这个作业属于哪个课程 | 2019学年02学期单红老师软件工程实践 |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2)链接 |
| 这个作业的目标 | 开发一个简易的疫情统计程序 |
| 作业正文 | 本博文 |
| 其他参考文献 | CSDN相关博客、构建之法 |
GitHub仓库地址
Benjamin_Gnep疫情统计
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 1890 | 2250 |
| Development | 开发 | 960 | 1170 |
| Analysis | 需求分析 (包括学习新技术) | 390 | 410 |
| Design Spec | 生成设计文档 | 90 | 120 |
| Design Review | 设计复审 | 30 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 120 | 150 |
| Design | 具体设计 | 90 | 150 |
| Coding | 具体编码 | 480 | 540 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 330 | 460 |
| Reporting | 报告 | 150 | 150 |
| Test Repor | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1890 | 2250 |
需求分析
- 分析外部传递的参数并进行不同的数据处理
- 文件的读取和写入
- 具有可拓展性和较强的可读性、封装性等
- 文件的编码确认
- 字符串的格式处理以及正则表达式的使用
- 文件的合法性确认
设计思路
- 命令分析使用正则表达式判断参数和值并且使用map储存
- 先读入文件列表,然后通过date参数进行日志筛选
- 将每个文件的每行连接在一起,然后组成一个待处理文本集进行处理
- 使用责任链模式对每行文本进行处理
- province和type可以返回链表,若不存在与表中的元素不予输出
- 构建一个TxtTool保存文件读入等一系列操作
- 构建一个CmdArgs对读入的参数与值进行处理
- 省份、类型以及参数使用枚举类存储,方便拓展
- 针对上述知识点到相关博客进行学习和查找
设计实现过程
代码说明
核心方法-excute
execute代码存在两个变量,分别是分析province返回的省份字符串以及分析type返回的typeList,主要执行十分简单,因为ListKey存在编号,所以for循环执行的时候会以log->date->province->type->out的顺序执行,方便确认list参数个数以及拓展添加。
@Override
public void execute(Map>map) {
String proString = null;
List typeString = new LinkedList();
for(int i = 0; i < ListKey.values().length ;i++) {
listKey = ListKey.valueOf(i);
switch(listKey) {
case DATE:
dateKey(map);
result = DataManager.solveData(logLine);
DataManager.mergeData(result);
break;
case LOG:
logKey(map);
break;
case OUT:
outKey(map,proString,typeString);
break;
case TYPE:
typeString = typeKey(map);
break;
case PROVINCE:
proString = provinceKey(map);
break;
}
}
}
枚举类举例-ProvinceValue
枚举类可以很方便的进行数据的存储编号,在province枚举类中还可以通过编号的方式事先确定好排序,枚举类不仅可以在switch中使用,还可以非常方便地进行复用。通过map进行索引还可以由键找值,由值寻键。
enum ProvinceValue{
China(0,"全国"), Anhui(1,"安徽"),Aomen(2,"澳门"), Beijing(3,"北京")
,Chongqin(4,"重庆"), Fujian(5,"福建"),Gansu(6,"甘肃"), Guangdong(7,"广东")
,Guangxi(8,"广西"), Guizhou(9,"贵州"), Hainan(10,"海南"), Hebei(11,"河北")
,Henan(12,"河南"), Heilongjiang(13,"黑龙江"),Hubei(14,"湖北"), Hunan(15,"湖南")
,Jiangsu(16,"江苏"), Jiangxi(17,"江西"), Jilin(18,"吉林"), Liaoning(19,"辽宁")
,Neimenggu(20,"内蒙古"), Ningxia(21,"宁夏"),Qinghai(22,"青海")
,Shandong(23,"山东"),Shanxi(24,"山西"),ShanXi(25,"陕西"),Shanghai(26,"上海")
,Sichuan(27,"四川"),Taiwan(28,"台湾"),Tianjin(29,"天津"),Xizang(30,"西藏")
,Xinjiang(31,"新疆"),Xianggang(32,"香港"), Yunnan(33,"云南"),Zhejiang(34,"浙江");
private int key;
private String text;
private ProvinceValue(int key,String text){
this.key = key;
this.text = text;
}
private static HashMap map = new HashMap();
static {
for(ProvinceValue d : ProvinceValue.values()){
map.put(d.key,d.text);
}
}
public static int keyOfProvince(String string) {
for (Entry entry : map.entrySet()) {
if (string.contains(entry.getValue())) {
return entry.getKey();
}
}
return -1;
}
public static ProvinceValue valueOf(int ordinal) {
if (ordinal < 0 || ordinal >= values().length) {
throw new IndexOutOfBoundsException("Invalid ordinal");
}
return values()[ordinal];
}
String getText() {
return text;
}
int getKey() {
return key;
}
}
数据存储-Map(String,List )
在类与类之间需要由数据结构进行数据传递,使用hashmap可以保证安全性的同时,将多种数据结构集合在一起,并且可以一一对应,不会造成一值多键的情况。分析命令行时,以‘-’作为识别参数的方式,再将参数后到另一参数前的值全部存取到list中,这样可以解决多值参数的问题,同时也确保每一个单词都被获取。
public Map> fillMap(Map> map) {
String key;
List value;
while(index < args.length) {
key = argKey();
key = key.toLowerCase().trim();
value = argVals();
map.put(key, value);
}
return map;
}
String argKey() {
if(index argVals() {
List values = new LinkedList();
while(index it = values.iterator();
if(!it.hasNext()) {
values.add(Constant.DEFAULT);
}
return values;
} 责任链模式-MyHandler
责任链模式可以很方便地拓展需求,一个类的修改不会影响另外一个类,利用Handler虚拟类,衍生出所有处理各类情况的类,确保可以处理每一种情况的文本,同时也减少了程序的耦合性,方便阅读。
class DataManager{
public static List solveData(Listdata){
List result = new LinkedList();
ListInit(result);
System.out.println("建立责任链");
AddipHandler addip = new AddipHandler(result);
AddSpHandler addSp = new AddSpHandler(result);
ChangeHandler change = new ChangeHandler(result);
CureHandler cure = new CureHandler(result);
DeathHandler death = new DeathHandler(result);
ExcludeHandler exclude = new ExcludeHandler(result);
SwapIpHandler swapIp = new SwapIpHandler(result);
SwapSpHandler swapSp = new SwapSpHandler(result);
addip.nextHandler = addSp;
addSp.nextHandler = change;
change.nextHandler = cure;
cure.nextHandler = death;
death.nextHandler = exclude;
exclude.nextHandler = swapIp;
swapIp.nextHandler = swapSp;
swapSp.nextHandler = null;
System.out.println("建立责任链完成,开始处理文本");
Iterator it = data.iterator();
while(it.hasNext()) {
String s = it.next();
addip.handleRequest(s);
}
System.out.println("---文本处理完成");
return result;
}
//......
}
单元测试
测试字符串为下列字符串数组,输入输出目录为了方便放在了学号下

dateScreen方法作为文件列表的筛选,可以看出,筛选掉了01-23后的日期文件
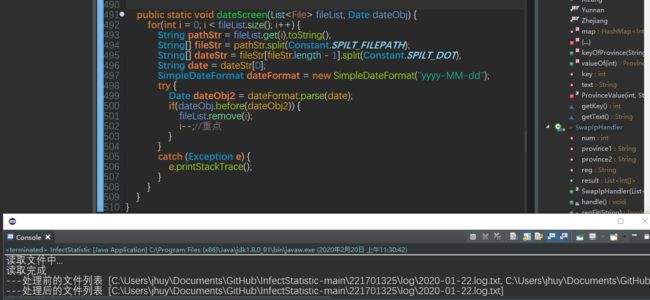
dateKey方法作为筛选文件、整合文件的方法,可以看出把所有待处理文件(去掉注释后)完整的连接在一起
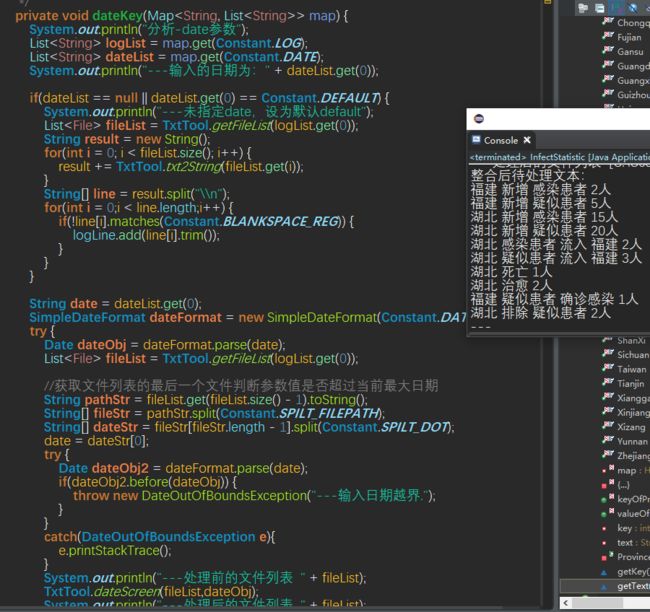
输出到文件的内容经过验证无误
![]()
覆盖率以及性能
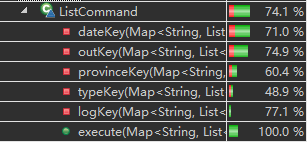
作为主要方法的ListCommand,除了各个方法内必要的空值判定外,其他代码均已覆盖,核心方法execute覆盖率为百分百
责任链的代码覆盖率也达到了百分之百
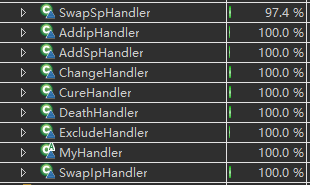
部分工具类的使用情况:覆盖率也基本达到了90%以上

以下为性能测试图
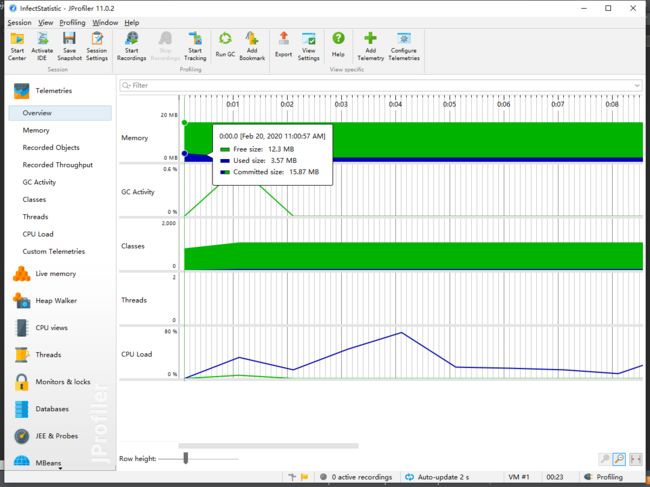
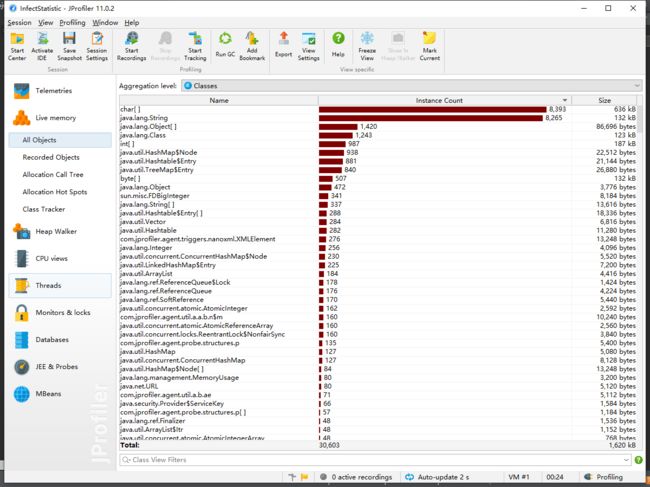
代码规范
Benjamin_Gnep代码规范
心路历程
初看到这个需求,满脑子没有一点思路。
的确要感谢很多同学的帮助,让我明白了如何理解一些复杂难懂的概念,然后慢慢开始梳理怎么开始进行编码。
B站真不愧是学习网站,我在上面找到了相关的入门教程,对于Git和Github都有了初步的了解,视频教程相对于博文来讲更加容易理解。
之后通过相关博文,我就开始对设计模式的命令模式和责任链模式进行学习,脑袋里有了初步的想法,包括枚举类和一些工作类的编写,然后整理了我的文本处理思路,便开始了初步的编写,基本上都是边写边查,遇到知识盲区就看看别人的代码,查查别人的只是总结,还是有很多收获的。
我在构建方法的时候尽量把功能细化,所以可能会导致代码量特别多,但是对于一些简单的方法复用率就高一些。
"软件=程序+软件工程"
构建之法的阅读我明白了很多代码规范,团队协作的关键在于如何让别人读懂你的程序,你可能可以把这个功能实现的很完美,但是没有规范没有注释的代码就是一坨狗屎。别人不可能花大量的时间收拾你的烂摊子。
Github前端相关仓库
Front-end-Developer-Interview-Questions 面试题集合
bootstrap 框架
Front-end-Collect 优秀网站、博客、活跃开发者
Vue 框架
Javascript 须知
希望以后的生活一日三餐,一年四季。