CDH5.12震撼发布,强势集成Hue 4,打包了很多激动人心的新功能,你能想象现在可以在Hue中直接使用Cloudera Navigator和Navigator Optimizer吗?!
Apache Hive/Hive-on-Spark
1.Hive on MapReduce2/Spark同时支持Microsoft Azure Data Lake Store (ADLS)。你现在可以用Hive on MapReduce2 and Hive-on-Spark读写存储在ADLS上的数据。具体请参考:Configuring ADLS Connectivity
2.Cloudera Manager现在集成了Hive的schematool,你可以使用它来更新或验证Hive metastore里的schema信息。具体请参考:Using the Hive Schema Tool
3.HIVE-1575:通过get_json_object函数支持root level的JSON arrays,比如:
SELECT get_json_object('[1,2,3]', '$[0]')...
Hue
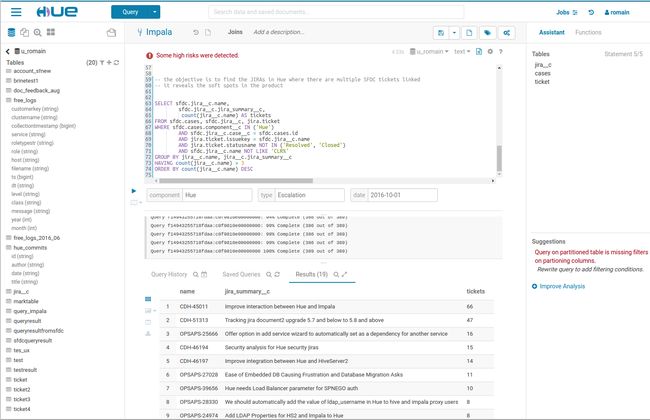
Hue 4终于发布了,并且打包了很多激动人心的功能。
Hue 4新的布局:

1.Apps被整合到蓝色按钮下 - 将您喜爱的设置为默认首选项(见上图的蓝色按钮“Query”)
2.顶部的搜索栏可以让你搜索已保存的查询和其他数据(Cloudera Manager顶端也有一个类似搜索栏,全局搜索框)
3.左右的辅助面板可以让你搜索和过滤schema objects
4.光标所在的位置决定要运行多个查询中的哪一个
5.新的Pig editor, Job Designer, 和Job Browser
6.从用户下拉菜单列表中访问旧的Hue3,或者中URL中删除“Hue”
默认添加Load Balancer
如果安装新的CDH/Hue,会自动安装一个Load Balancer来保证最优性能 - 它可以降低Hue服务器的负载高达90%!在旧版本中,用户需要添加一个Load Balancer角色,并且手动启用它。参考Cloudera的博文:Automatic HA
测试LDAP配置
在安装过程中验证你的LDAP配置,这个新功能你可以在Cloudera Manager的Hue > Actions > Test LDAP Configuration中使用。参考:Authenticate Hue with LDAP
集成Navigator Optimizer(第一阶段)
通过Hue集成Navigator Optimizer,经常使用的表,字段,关联条件,过滤条件都可以被自动填充。有风险的语句,比如在分区表上缺少过滤条件,将会触发告警。
默认启用Navigator Search & Tag
通过Hue集成Navigator,你可以搜索元数据或者给元数据打标签。只要你安装了Cloudera Navigator,这个功能默认将会开启。参考: How to Enable and Use Navigator in Hue
其他酷炫的特性:
1.你可以从文件创建分区表。
2.Impala的metadata将会被自动refresh。
3.提升SQL语句自动填充的功能。
4.SSL的远程 Load balancer。
5.查询历史记录分页。
Apache Impala
以下是本次更新的Impala主要的新特性:
1.Impala现在可以读写存储在Microsoft Azure Data Lake Store (ADLS)中的数据。
注意:目前Impala的ADLS支持还在初级阶段,测试不够充分。并不建议用户直接将Impala on ADLS上生产。
2.新的内置函数
1)一个新的字符串函数,replace(),在简单字符串替换场景比以前的regexp_replace()更高效。访问 Impala String Functions查看细节。
2)一个新的条件函数,nvl2(),它比nvl()更灵活。它允许NOT NULL参数会返回一个值,NULL参数则返回另外一个值。访问Impala Conditional Functions查看细节。
3.新的语法,REFRESH FUNCTIONS db_name,让Impala识别新的自定义函数,比如通过Hive创建的UDFs。Impala扫描指定数据库的元数据以查找新的自定义函数,这比执行全局的INVALIDATE METADATA更高效也更方便。
4.Impala Daemon的启动标志,is_executor和is_coordinator,你可以将少量节点用作查询的coordinators,然后将其他大量的节点作为查询executors,这样你可以更好的为大型,高负载的集群做节点分工。旧版本中,每个节点可以同时扮演这两个角色(既是executor,又是coordinator,coordinators会随机从Impala Daemon中挑选),这往往是大量并发的工作负载的瓶颈。详情请参考: Controlling which Hosts are Coordinators and Executors
5.新的查询模式选择,DEFAULT_JOIN_DISTRIBUTION_MODE,对于一些没有统计信息的表,可以更改默认的关联方式。这可以避免join查询的内存不足,而不用手动的在缺少统计信息的大表语句中添加/* +SHUFFLE */提示。
6.SORT BY语法可以在你创建Parquet文件时,使用更高效的压缩方式以及为一些特定字段的值指定更小的范围,从而允许Impala以更优化的方式跳过从Parquet文件中读取一些数据,这些数据不在WHERE的条件范围内。访问CREATE TABLE Statement查看细节。
8.Kudu提升
1)ALTER TABLE语句可以使用ADD COLUMNS子语句为Kudu表指定更多的属性。包括[NOT] NULL, ENCODING COMPRESSION, DEFAULT, 和BLOCK_SIZE。访问ALTER TABLE Statement查看细节。
2)Kudu现在支持TIMESTAMP类型。
注意:在使用这种数据类型时可以参考 Handling Date, Time, or Timestamp Data with Kudu了解关于性能和使用方便的折衷/妥协。为了高性能,你可能仍然需要继续使用BIGINT,对于date/time的值。
3)优化通过INSERT和CREATE TABLE AS SELECT语句写数据到Kudu的表。旧版本在单个操作写入大量数据时,写操作的开销可能会导致超时。
Apache HBase
1.Apache HBase现在支持ADLS存储。
2.如果不是云部署,通过更新token,HBase现在支持长期运行的Spark应用。
Apache Spark
Spark现在可以读写存储在Microsoft Azure Data Lake Store (ADLS)中的数据。访问 Accessing Data Stored in Azure Data Lake Store (ADLS) through Spark查看细节。