这是一个有趣的项目,关于bra销售数据分析的。是网络爬虫和数据分析的综合应用项目。从淘宝抓取bra销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过SQL语句、Pandas和Matplotlib对数据进行数据可视化分析。我们从分析结果中可以得出很多有的结果,例如,中国女性胸部标准尺寸是多少;bra上胸围的销售比例;哪个颜色的bra最受女性欢迎。
1. 项目效果展示
本项目涉及到网络技术、网络爬虫技术、数据库技术、数据分析技术、数据可视化技术。首先应该运行tmallbra.py脚本文件从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中。接下来可以执行analyze目录中的相应Python脚本文件进行可视化数据分析。下面是一些分析结果展示。

图1:ABCD罩杯bra销售比例(Python视频资料免费领取 QQ群519970686)

图2:bra销售比例(罩杯和上胸围综合指标)

图3:bra销售比例(按颜色分析)

图4:罩杯和下胸围分布直方图
其实Google和天猫也给出了类似的分析结果。Google曾给出了一幅世界女性胸部尺寸分布地图 ,从地图中可以明显看出中国大部分地区呈现绿色(表示平均胸部尺寸为A罩杯),少部分地区呈现蓝色(表示平均胸部尺寸为B罩杯),这也基本验证了图2所示的统计结果:中国大部分女性胸部尺寸是75B和75A。
再看一下淘宝给出的bra(按罩杯和上胸围统计)销售比例柱状图。

图5:淘宝bra销售比例柱状图(按罩杯和上胸围统计)
从淘宝给出的数据可以看出,销售最好的bra尺寸是75B,这个统计结果虽然销售比例不同(取的样本不同而导致的),但按销售数据排行,这个分析结果与本项目的统计结果(图2)基本吻合。
2. 淘宝bra销售数据分析
这里的销售数据其实就是评论数据。用户购买一件商品并发了评论,就会记录销售数据。分析销售数据的第一步就是要搞明白数据是怎么跑到客户端浏览器上的。通常来讲,浏览器从服务端获取数据有两种方式:同步和异步。同步就是数据随HTML代码一同发送到客户端,不过现在的大型网站很少有用同步方式传输数据了。异步方式是HTML代码与数据分别发送到客户端,数据一般是JSON格式,通过AJAX技术获取,然后再使用JS将获取到的数据显示在HTML中的元素上。不过有时会加一些反爬虫技术,或处于其他目的,异步数据可能并不是纯的JSON格式,例如,有可能是一段JavaScript代码,或在JSON格式数据中加一些其他的内容。不过这些基本都没用,加的内容肯定是有规律的,否则自己的程序都无法读了。
现在进到淘宝网,在搜索框输入“bra”,点击“搜索”按钮进行搜索。随便找一个销售bra的店铺点进去。然后在页面的右键菜单中点击“检查”菜单项,打开调试窗口,切换到“Network”标签页。接下来查看商品的评论,会在“Network”标签页显示评论信息要访问的Url。在上方的搜索框输入“list_detail”,会列出所有已“list_detail”作为前缀的Url。这些Url就是用AJAX异步获取的评论数据。点击某个Url,会在右侧显示如图6所示的数据,很明显,这些数据与JSON非常像,不过加了一些前缀以及其他信息,估计是要满足一些特殊需要。

图6:淘宝评论数据
在返回的评论数据中,rateList就是我们需要的信息,rateList列表中一共是20个对象,包含了20条评论数据,也就是说,通过这个Url,每次返回了20条评论数据。
在Url中还有两个HTTP GET请求字段对我们有用。
• itemId:当前商品的ID,通过这个字段,可以获得指定商品的评论数
据(不光是bra)。
• currentPage:当前的页码,从1开始。通过这个字段,可以获得更多的评论数据。
3.抓取淘宝bra销售数据
既然对淘宝bra的评论数据的来源已经非常清楚了,本节就抓取这些数据。在tmallbra.py脚本文件中有一个核心函数,用于抓取指定商品的某一页评论数据。
defgetRateDetail(itemId,currentPage):
# Url最后的callback字段是用于淘宝网站内部回调的,和我们没关系,不过这个字段的值关系到
# 返回数据的前缀,我们可以利用这个值去截取返回数据
url ='https://rate.taobao.com/list_detail_rate.htm?itemId='+ str(itemId) +
'&spuId=837695373&sellerId=3075989694ℴ=3¤tPage='+ str(currentPage) +
'&append=0... ...&callback=jsonp1278'
r = http.request('GET',url,headers = headers)
# 返回数据时GB18030编码,所以要用这个编码格式进行解码
c = r.data.decode('GB18030')
# 下面的代码将返回的评论数据转换为JSON格式
c = c.replace('jsonp1278(','')
c = c.replace(')','')
c = c.replace('false','"false"')
c = c.replace('true','"true"')
# 将JSON格式的评论数据转换为字典对象
taobaojson = json.loads(c)
returntaobaojson
4. 抓取bra商品列表
应用让爬虫自动选取bra商品,而不是我们一个一个挑。所以可以利用如下的天猫商城的搜索页面Url进行搜索,按销量从大到小排列。
https://list.tmall.com/search_product.htm... ...
这个Url不需要传递任何参数,本项目只取第一个商品页的所有商品。在tmallbra.py脚本文件中有一个而核心函数getProductIdList,用于返回第一个商品页的所有商品ID(以列表形式返回)。
defgetProductIdList():
url ='https://list.tmall.com/search_product.htm... ...'
r = http.request('GET', url,headers = headers)
c = r.data.decode('GB18030')
soup = BeautifulSoup(c,'lxml')
linkList = []
idList = []
# 用Beautiful Soup提取商品页面中所有的商品ID
tags = soup.find_all(href=re.compile('detail.tmall.com/item.htm'))
fortagintags:
linkList.append(tag['href'])
linkList = list(set(linkList))
forlinkinlinkList:
aList = link.split('&')
# //detail.tmall.com/item.htm?id=562173686340
# 将商品ID添加到列表中
idList.append(aList[0].replace('//detail.tmall.com/item.htm?id=',''))
returnidList
4.将抓取的销售数据保存到SQLite数据库中
剩下的工作就很简单了,只需要对商品ID列表迭代,然后对每一个商品的评论数据进行抓取,天猫每个商品最多可以获得99页评论,最大评论页数可以通过getLastPage函数获得。
defgetLastPage(itemId):
tmalljson = getRateDetail(itemId,1)
returntmalljson['rateDetail']['paginator']['lastPage']
下面的代码会抓取商品搜索第一页的所有bra商品的评论数据,并将这些数据保存到SQLite数据库中。
# 对商品ID进行迭代
whileinitial < len(productIdList):
try:
itemId = productIdList[initial]
print('----------',itemId,'------------')
maxnum = getLastPage(itemId)
num =1
whilenum <= maxnum:
try:
# 抓取某个商品的某页评论数据
tmalljson = getRateDetail(itemId, num)
rateList = tmalljson['rateDetail']['rateList']
n =0
whilen < len(rateList):
# 颜色分类:H007浅蓝色加粉色;尺码:32/70A
colorSize = rateList[n]['auctionSku']
m = re.split('[:;]',colorSize)
rateContent = rateList[n]['rateContent']
color = m[1]
size = m[3]
dtime = rateList[n]['rateDate']
# 将抓取的数据保存到SQLite数据库中
cursor.execute('''insert into t_sales(color,size,source,discuss,time)
values('%s','%s','%s','%s','%s') '''% (color,size,'天猫',rateContent,dtime))
conn.commit()
n +=1
print(color)
print(num)
num +=1
exceptExceptionase:
continue
initial +=1
exceptExceptionase:
print(e)
5. 数据清洗
如果读者使用前面介绍的方法从天猫和京东抓取了bra销售数据,现在我们已经有了一个SQLite数据库,里面有一个t_sales表,保存了所有抓取的数据,如图31-8所示。

从销售数据可以看出,网络爬虫抓取了颜色(color)、尺寸(size)、来源(source)、评论(discuss)和时间(time)五类数据。当然还可以抓取更多的数据,这里只为了演示数据分析的方法,所以并没有抓取那么多的数据。
不过这五类数据有些不规范,本项目值考虑color和size,所以先要对这两类数据进行清洗。由于每个店铺,每个商品的颜色叫法可能不同,所以需要将这些颜色值统一一下。例如,所有包含“黑”的颜色值都可以认为是黑色。所以可以新建立一个color1字段(尽量不要修改原始数据),将清洗后的颜色值保存到color1字段中。然后可以使用下面的SQL语句对颜色值进行清洗。
updatet_salessetcolor1 ='黑色'wherecolorlike'%黑%';
updatet_salessetcolor1 ='绿色'wherecolorlike'%绿%';
updatet_salessetcolor1 ='红色'wherecolorlike'%红%';
updatet_salessetcolor1 ='白色'wherecolorlike'%白%';
updatet_salessetcolor1 ='蓝色'wherecolorlike'%蓝%';
updatet_salessetcolor1 ='粉色'wherecolorlike'%粉%'andcolor1isnull;
updatet_salessetcolor1 ='青色'wherecolorlike'%青%';
updatet_salessetcolor1 ='卡其色'wherecolorlike'%卡其%';
updatet_salessetcolor1 ='紫色'wherecolorlike'%紫%';
updatet_salessetcolor1 ='肤色'wherecolorlike'%肤%';
updatet_salessetcolor1 ='水晶虾'wherecolorlike'%水晶虾%';
updatet_salessetcolor1 ='玫瑰色'wherecolorlike'%玫瑰%';
updatet_salessetcolor1 ='银灰'wherecolorlike'%银灰%';
bra尺寸清洗的方式与bra颜色类似,大家可以自己通过SQL语句去完成。
清洗完的结果如图7所示。

图7:清洗后的数据
6. 用SQL语句分析bra(按罩杯尺寸)的销售比例
既然销售数据都保存在SQLite数据库中,那么我们不妨先用SQL语句做一下统计分析。本节将对bra按罩杯的销售量做一个销售比例统计分析。由于抓取的数据没有超过D罩杯的,所以做数据分析时就不考虑D以上罩杯的bra销售数据了。这里只考虑A、B、C和D罩杯bra的销售数据。
本节要统计的是某一个尺寸的bra销售数量占整个销售数量的百分比,这里需要统计和计算如下3类数据。
• 某一个尺寸的bra销售数量。
• bra销售总数量
• 第1类数据和第2类数据的差值(百分比)
这3类数据完全可以用一条SQL语句搞定,为了同时搞定A、B、C和D罩杯的销售比例,可以用4条类似的SQL语句,中间用union all连接。
select'A'as罩杯,printf("%.2f%%",(100.0*count(*)/ (selectcount(*)fromt_saleswheresize1isnotnull)))as比例,count(*)as销量fromt_saleswheresize1='A'
unionall
select'B',printf("%.2f%%",(100.0*count(*)/ (selectcount(*)fromt_saleswheresize1isnotnull))) ,count(*)ascfromt_saleswheresize1='B'
unionall
select'C',printf("%0.2f%%",(100.0*count(*)/ (selectcount(*)fromt_saleswheresize1isnotnull))) ,count(*)ascfromt_saleswheresize1='C'
unionall
select'D',printf("%.2f%%",(100.0*count(*)/ (selectcount(*)fromt_saleswheresize1isnotnull))) ,count(*)ascfromt_saleswheresize1='D'
orderby销量desc
上面的SQL语句不仅加入了销售比例,还加入了销售数量,并且按销量降序排列。这些SQL语句需要考虑size1字段空值的情况,因为抓取的少部分销售记录并没有罩杯尺寸数据。执行上面的SQL语句后,会输出如图8所示的查询结果。

图8:用SQL语句统计bra(按罩杯尺寸)销售比例
其他的销售数据的分析类似。
7. 用Pandas和Matplotlib分析对bra销售比例进行可视化分析
既然Python提供了这么好的Pandas和Matplotlib,那么就可以完全不使用SQL语句进行数据分析了。可以100%使用Python代码搞定一切。
本节将使用Pandas完成与上一节相同的数据分析,并使用Matplotlib将分析结果以图形化方式展现出来。
Pandas在前面的章节已经讲过了,这里不再深入介绍。本次分析主要使用了groupby方法按罩杯(size1)分组,然后使用count方法统计组内数量,最后使用insert方法添加了一个“比例”字段。
frompandasimport*
frommatplotlib.pyplotimport*
importsqlite3
importsqlalchemy
# 打开bra.sqlite数据库
engine = sqlalchemy.create_engine('sqlite:///bra.sqlite')
rcParams['font.sans-serif'] = ['SimHei']
# 查询t_sales表中所有的数据
sales = read_sql('select source,size1 from t_sales',engine)
# 对size1进行分组,并统计每一组的记录数
size1Count = sales.groupby('size1')['size1'].count()
print(size1Count)
# 计算总销售数量
size1Total = size1Count.sum()
print(size1Total)
print(type(size1Count))
# 将Series转换为DataFrame
size1 = size1Count.to_frame(name='销量')
print(size1)
# 格式化浮点数
options.display.float_format ='{:,.2f}%'.format
# 插入新的“比例”列
size1.insert(0,'比例',100* size1Count / size1Total)
print(size1)
# 将索引名改为“罩杯”
size1.index.names=['罩杯']
print(size1)
# 数据可视化
print(size1['销量'])
# 饼图要显示的文本
labels = ['A罩杯','B罩杯','C罩杯','D罩杯']
# 用饼图绘制销售比例
size1['销量'].plot(kind='pie',labels = labels, autopct='%.2f%%')
# 设置长宽相同
axis('equal')
legend()
show()
运行程序,会看到在窗口上绘制了如图9所示的bra销售比例。用Pandas分析得到的数据与使用SQL分析得到的数据完全相同。
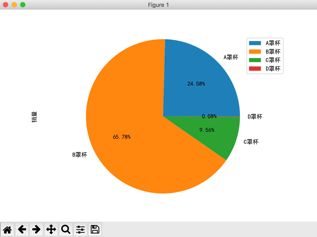
图9:bra销售比例(按罩杯尺寸)
其他分析也可以使用Pandas,可视化使用Matplotlib。这两个工具真是个强大的东西。祝大家学习愉快