△本章及之后的几章(天气预测、地震预测、传染病预测)都是讲涉及到大规模公共安全时的预测。对于此类预测,预测的结果如何远不如对预测的执行重要,而预测的执行需要正确的预测来指导。但是如果预测者参杂了个人偏见(或者“动机不纯”),那么是无法做出正确预测的。关于这一点的讨论,在之后相关的那几章会一再地出现。另外,下文中的“预测”和“预报”是同一个意思。
△像素化分割
1961年,物理学家理查德森第一个将大气进行像素化(类似于棋盘格)分割后进行近似分析。
和计算机运算能力的迅速提高相比,天气预报的精度只在缓慢增长。原因在于:
1、要提高精度需要将原先的网格分得更小,这样计算量将成倍增长;而且不但要对大气平面进行网格化,对于大气高度也要分割,相当于对整个大气层进行三维上取“块”,这样对计算机运算能力的需求就是指数级的增长。
2、天气预测受混沌理论的影响。
△混沌理论
1972年,洛伦兹提出了混沌理论。用混沌理论描述的系统有两个特点:
1、动态系统,随时间不断变化;
2、非线性系统,初始的微小波动都会引起之后系统中的剧烈震荡。
这两种特性的组合,会将系统中本来无足轻重的错误迅速放大。
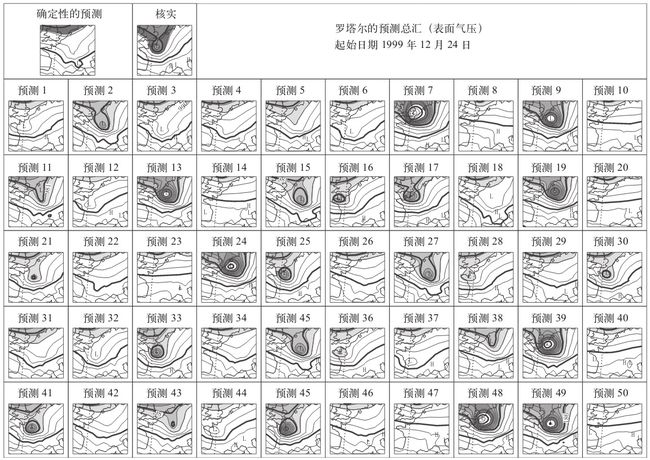
从上图可以看到,在预测系统中数据质量的重要性,数据质量的微小差别都能带来结果之间数量级的不同,甚至,“微小差别”可能仅仅在于保留的精度差了一位而已。
△天气预测中人的优势
与高速计算机相比,人的优势是什么?视觉。
对两个相互作用变量的图标进行视觉检查,能比统计测试更快捷、更可靠地发现数据中的一场,这一点是计算机目前不如人类的地方。(因为计算机就是“线性”思维的)
美国国家气象局的数据显示:单独由计算机指导完成对降雨量和温度的预测后,人类还能将精度分别提高25%和10%。
△衡量气象预报的标准
目前的气象预报依然无法做到完全准确,那么该如何去衡量“好的气象预报”呢?
1993年,气象学家墨菲发表了一篇文章,提出关于预测质量的3种标准:
1、通过质量衡量;(预报与实际相比准确与否,即准确性)
2、通过一致性衡量;(预报的结果是否经过了修饰,即诚实)
3、通过经济价值衡量。(预报的结果能否帮助人们作出更好的决定)
将准确性和诚实分开,这在我们做出了错误的预测时尤为有用。比如,假如你当时所能做出的最完美的预测是个错误的预测,那么该如何去评价它呢?
△气象预报系统的两项标准测试
好的气象预报系统应当满足以下两点:
1、持续性。(能预测明天的天气和今天的一样好)
2、突破性。(能预测明天的天气和历史上的任何一个明天都不一样)
<有点熟悉对吧,因为这两点也适用于棒球预测系统,大联盟球员的重点是持续性分析,小联盟球员的重点是突破性分析>
△对气象预报历史记录的分析和预测中的伦理
ForecastWatch.com对气象预报的历史记录(不是气象历史记录)进行了收集和比较。结果是:

商业机构的天气数据是由政府提供的,它们在此基础上进行了再加工,你也能发现,它们发挥了各自技术上的优势,在不同领域中做得更好。一个特别的例子是,当政府部门预测气温将接近0度时,他们并不关心天气是会下雨、下雪还是下冰雹,而这三种天气显然对民众有着不同的影响,精确地预测这一点,就是商业机构创造自身价值的地方。
但是,问题也有:提前8天的预测没有任何技术含量(你可以参照气候学规律等同于历史上的同一天);提前9天的预测比气候学规律还要糟糕。
原因是:时间跨度越长时,混沌理论的影响就更大。天气模型若是以一定的初始条件开始演变,经过足够长的时间之后,演变的结果和现实中的天气就毫无相同之处了。就目前的研究水平下,对天气预测需要采用最近的天气资料,使用更久远的资料是没有多大意义的——由那时开始演进到现在,噪声会足以强到掩盖掉信号。
那么,为何商业网站还会再进一步,推出提前10~15天的天气预报呢?
气象频道(这是个商业机构)的科学家兼副总裁罗斯认为:因为这样做也不会有任何伤害。
注意,这时候预测中的伦理问题就开始凸显了:是为了作出准确的预测,还是为了作出帮你更好地做决定的预测?
商业机构认为,用户体验比实际的准确性更重要。比如,用户看到50%的降水概率就不知道该怎么做,于是这时候商业机构就宁愿四舍五入为40%或60%,有时甚至干脆改数字。
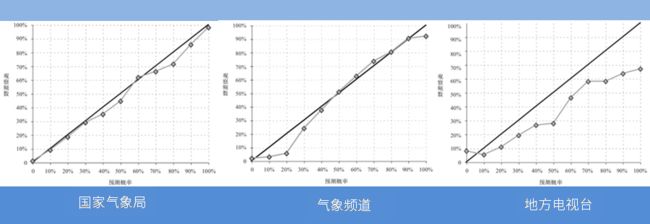
这就涉及到作者所谓的“动机不纯”的问题。和政治预测类似,假如预测的结果正确与否并不重要,预测者更在意预测的过程,如果该过程能给他带来经济利益和影响力,那么他可能就会故意做出错误的预测。
本章的商业机构因为利益和预测的准确性部分相关,因此“动机不纯”的出发点只是为了用户体验,在以后的几章我们会看到,当预测的结果如何并不重要(当然也很难检验)的情况下,预测者和预测之间也没有密切的利益相关,那么他很可能仅仅为了预测过程中的利益最大化(比如为了发一篇论文)而做出不负责任的预测。
△预测的标定
对预测进行标定,是指假如预报为40%的降水概率,那么在长期而言,同样预报40%概率的所有日期的总和里,真正下雨的天气也应该体现为40%才对。但实际上很多预测都做不到这点。
对标定进行检验,对我们想评估某个预测时极为有用,同时对预测者本身也大有好处——特别是在纠正“过度自信”上。
△人与机器
本章中的预测,因为涉及到巨量的运算,因此以机器为主(当然理论是人设计的),人占辅助地位。
但是,这仅仅针对作出正确预测时的情况。作出预测之后如何去宣布,这时候人——人性——就占据主导地位了。
也就是说,讨论预测系统中,人与机器的地位也是个伪命题,因为人掌控着理论设计和提交预测这一“入口”和“出口”,那么在预测的过程中无论是机器辅助人还是人辅助机器就全局而言是不重要的。在接下来的章节中,我们能看到作者不再花大量篇幅去描述预测中机器(或者数据)的影响,主要探讨的就是人、人的动机对预测所产生的影响。
△思考
一、“拉普拉斯的恶魔”和机器能否统治世界
“拉普拉斯的恶魔”的简要表述是,如果我们能知道地球上每一个粒子的属性,也能知道它们之间相互作用的规律,那么我们就能模拟任何事物的演变。
天气预测的理论基础就是基于对影响天气的最小单位的研究(目前是三维像素块,也许迟早会演进到分子层面吧),来模拟天气的变化。
而科学主义指导下的世界观,比如人定胜天、机器将统治世界等等,究其本质都可归入“拉普拉斯的恶魔”这类科学决定论中。这一观念的产生是如此的自然——我们能预测分子的运动,我们也能预测原子的运动,看起来我们在理论上确实能预测一切了——以致 于直到量子力学出现后我们才看到了我们当时不知道自己不知道的:其实我们做不到准确地预测每一个粒子的位置。
那么是不是我们就再也不用担心天网的威胁了?也不尽然。我们现在不能测量更小的粒子不代表未来也无法测量——毕竟理论和技术都还有突破的可能。
所以只要我们理论上还有预测一切的可能,理论上机器也就能通过模拟每一个粒子从而统治世界。
但这样思考的局限性很明显:为什么机器一定要用人类的方式——通过建立模型来战胜人类进而在现实中战胜人类——来统治世界呢?它完全可以用更简单的方式:比如病毒式传播和繁殖,挤压人类的生存空间从而消灭人类。
也许是那样做一点都不帅吧。
二、预测的伦理
作者认为,即便有商业利益的诱惑,也应该坚持预测的准确性。否则在平时就丧失了公信力,那么真正到了关键时刻的预报就没人采信了。
他举的例子是卡特里娜飓风对新奥尔良的破坏,说明涉及大规模公共安全时的预测与预测的应用之间的矛盾。这并不是靠预测机构在平时加强道德修养就能改变的。
为了避免政治压力,美国国家飓风中心将具体疏散的任务交由美国国家气象局的122个地方办公室,让他们去和当地政府协调疏散事宜。虽然这样做能保证预测结果的准确与独立,但它放弃这一权力后,就把地方政府推到了前台。
假若根据国家飓风中心的预测结果发布了强制疏散的命令,而飓风又没有来的话,地方政府会被问责;另一方面,商业台的气象预报虽然能覆盖更大范围,但因为商业 台并不需要对气象预报的结果负责——所以平时的预报质量就很差,导致了——在关键时刻民众根本不相信它们。那么当政府首脑做决策时掷错了硬币,这样的事件似乎是无可避免的了。
那么不如教育民众去多关注国家飓风中心的网站?民选政府的一部分责任就是降低社会成本,若事事让民众亲力亲为,政府的效用就降低了一半,而且对飓风中心预测结果的解读也要依靠专业人员。所以——这应该是民选政府绕不开的结吧。