- 斤斤计较的婚姻到底有多难?
白心之岂必有为
很多人私聊我会问到在哪个人群当中斤斤计较的人最多?我都会回答他,一般婚姻出现问题的斤斤计较的人士会非常多,以我多年经验,在婚姻落的一塌糊涂的人当中,斤斤计较的人数占比在20~30%以上,也就是说10个婚姻出现问题的斤斤计较的人有2-3个有多不减。在婚姻出问题当中,有大量的心理不平衡的、尖酸刻薄的怨妇。在婚姻中仅斤斤计较有两种类型:第一种是物质上的,另一种是精神上的。在物质与精神上抠门已经严重的影响
- 情绪觉察日记第37天
露露_e800
今天是家庭关系规划师的第二阶最后一天,慧萍老师帮我做了个案,帮我处理了埋在心底好多年的一份恐惧,并给了我深深的力量!这几天出来学习,爸妈过来婆家帮我带小孩,妈妈出于爱帮我收拾东西,并跟我先生和婆婆产生矛盾,妈妈觉得他们没有照顾好我…。今晚回家见到妈妈,我很欣赏她并赞扬她,妈妈说今晚要跟我睡我说好,当我们俩躺在床上准备睡觉的时候,我握着妈妈的手对她说:妈妈这几天辛苦你了,你看你多利害把我们的家收拾得
- QQ群采集助手,精准引流必备神器
2401_87347160
其他经验分享
功能概述微信群查找与筛选工具是一款专为微信用户设计的辅助工具,它通过关键词搜索功能,帮助用户快速找到相关的微信群,并提供筛选是否需要验证的群组的功能。主要功能关键词搜索:用户可以输入关键词,工具将自动查找包含该关键词的微信群。筛选功能:工具提供筛选机制,用户可以选择是否只显示需要验证或不需要验证的群组。精准引流:通过上述功能,用户可以更精准地找到目标群组,进行有效的引流操作。3.设备需求该工具可以
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 铭刻于星(四十二)
随风至
69夜晚,绍敏同学做完功课后,看了眼房外,没听到动静才敢从书包的夹层里拿出那个心形纸团。折痕压得很深,都有些旧了,想来是已经写好很久了。绍敏同学慢慢地、轻轻地捏开折叠处,待到全部拆开后,又反复抚平纸张,然后仔细地一字字默看。只是开头的三个字是第一次看到,让她心漏跳了几拍。“亲爱的绍敏:从四年级的时候,我就喜欢你了,但是我一直不敢说,怕影响你学习。六年级的时候听说有人跟你表白,你接受了,我很难过,但
- 随笔 | 仙一般的灵气
海思沧海
仙岛今天,我看了你全部,似乎已经进入你的世界我不知道,这是否是梦幻,还是你仙一般的灵气吸引了我也许每一个人都要有一份属于自己的追求,这样才能够符合人生的梦想,生活才能够充满着阳光与快乐我不知道,我为什么会这样的感叹,是在感叹自己的人生,还是感叹自己一直没有孜孜不倦的追求只感觉虚度了光阴,每天活在自己的梦中,活在一个不真实的世界是在逃避自己,还是在逃避周围的一切有时候我嘲笑自己,嘲笑自己如此的虚无,
- 一百九十四章. 自相矛盾
巨木擎天
唉!就这么一夜,林子感觉就像过了很多天似的,先是回了阳间家里,遇到了那么多不可思议的事情儿。特别是小伙伴们,第二次与自己见面时,僵硬的表情和恐怖的气氛,让自己如坐针毡,打从心眼里难受!还有东子,他现在还好吗?有没有被人欺负?护城河里的小鱼小虾们,还都在吗?水不会真的干枯了吧?那对相亲相爱漂亮的太平鸟儿,还好吧!春天了,到了做窝、下蛋、喂养小鸟宝宝的时候了,希望它们都能够平安啊!虽然没有看见家人,也
- UI学习——cell的复用和自定义cell
Magnetic_h
ui学习
目录cell的复用手动(非注册)自动(注册)自定义cellcell的复用在iOS开发中,单元格复用是一种提高表格(UITableView)和集合视图(UICollectionView)滚动性能的技术。当一个UITableViewCell或UICollectionViewCell首次需要显示时,如果没有可复用的单元格,则视图会创建一个新的单元格。一旦这个单元格滚动出屏幕,它就不会被销毁。相反,它被添
- 微服务下功能权限与数据权限的设计与实现
nbsaas-boot
微服务java架构
在微服务架构下,系统的功能权限和数据权限控制显得尤为重要。随着系统规模的扩大和微服务数量的增加,如何保证不同用户和服务之间的访问权限准确、细粒度地控制,成为设计安全策略的关键。本文将讨论如何在微服务体系中设计和实现功能权限与数据权限控制。1.功能权限与数据权限的定义功能权限:指用户或系统角色对特定功能的访问权限。通常是某个用户角色能否执行某个操作,比如查看订单、创建订单、修改用户资料等。数据权限:
- 学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
- 《投行人生》读书笔记
小蘑菇的树洞
《投行人生》----作者詹姆斯-A-朗德摩根斯坦利副主席40年的职业洞见-很短小精悍的篇幅,比较适合初入职场的新人。第一部分成功的职业生涯需要规划1.情商归为适应能力分享与协作同理心适应能力,更多的是自我意识,你有能力识别自己的情并分辨这些情绪如何影响你的思想和行为。2.对于初入职场的人的建议,细节,截止日期和数据很重要截止日期,一种有效的方法是请老板为你所有的任务进行优先级排序。和老板喝咖啡的好
- Long类型前后端数据不一致
igotyback
前端
响应给前端的数据浏览器控制台中response中看到的Long类型的数据是正常的到前端数据不一致前后端数据类型不匹配是一个常见问题,尤其是当后端使用Java的Long类型(64位)与前端JavaScript的Number类型(最大安全整数为2^53-1,即16位)进行数据交互时,很容易出现精度丢失的问题。这是因为JavaScript中的Number类型无法安全地表示超过16位的整数。为了解决这个问
- 店群合一模式下的社区团购新发展——结合链动 2+1 模式、AI 智能名片与 S2B2C 商城小程序源码
说私域
人工智能小程序
摘要:本文探讨了店群合一的社区团购平台在当今商业环境中的重要性和优势。通过分析店群合一模式如何将互联网社群与线下终端紧密结合,阐述了链动2+1模式、AI智能名片和S2B2C商城小程序源码在这一模式中的应用价值。这些创新元素的结合为社区团购带来了新的机遇,提升了用户信任感、拓展了营销渠道,并实现了线上线下的完美融合。一、引言随着互联网技术的不断发展,社区团购作为一种新兴的商业模式,在满足消费者日常需
- 2021-08-26
影幽
在生活中,女人与男人的感悟往往有所不同。人生最大的舞台就是生活,大幕随时都可能拉开,关键是你愿不愿意表演都无法躲避。在生活中,遇事不要急躁,不要急于下结论,尤其生气时不要做决断,要学会换位思考,大事化小小事化了,把复杂的事情尽量简单处理,千万不要把简单的事情复杂化。永远不要扭曲,别人善意,无药可救。昨天是张过期的支票,明天是张信用卡,只有今天才是现金,要善加利用!执着的攀登者不必去与别人比较自己的
- ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)
研学随笔
arcgis经验分享
我们在使用ArcGIS时通常经常用到栅格计算器,今天主要给大家介绍我日常中经常用到的几个公式,供大家参考学习。将特定值(-9999)赋值为0,例如-9999.Con("raster"==-9999,0,"raster")2.给空值赋予特定的值(如0)Con(IsNull("raster"),0,"raster")3.将特定的栅格值(如1)赋值为空值,其他保留原值SetNull("raster"==
- 高级编程--XML+socket练习题
masa010
java开发语言
1.北京华北2114.8万人上海华东2,500万人广州华南1292.68万人成都华西1417万人(1)使用dom4j将信息存入xml中(2)读取信息,并打印控制台(3)添加一个city节点与子节点(4)使用socketTCP协议编写服务端与客户端,客户端输入城市ID,服务器响应相应城市信息(5)使用socketTCP协议编写服务端与客户端,客户端要求用户输入city对象,服务端接收并使用dom4j
- 2018-07-23-催眠日作业-#不一样的31天#-66小鹿
小鹿_33
预言日:人总是在逃避命运的路上,与之不期而遇。心理学上有个著名的名词,叫做自证预言;经济学上也有一个很著名的定律叫做,墨菲定律;在灵修派上,还有一个很著名的法则,叫做吸引力法则。这3个领域的词,虽然看起来不太一样,但是他们都在告诉人们一个现象:你越担心什么,就越有可能会发生什么。同样的道理,你越想得到什么,就应该要积极地去创造什么。无论是自证预言,墨菲定律还是吸引力法则,对人都有正反2个维度的影响
- 【一起学Rust | 设计模式】习惯语法——使用借用类型作为参数、格式化拼接字符串、构造函数
广龙宇
一起学Rust#Rust设计模式rust设计模式开发语言
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、使用借用类型作为参数二、格式化拼接字符串三、使用构造函数总结前言Rust不是传统的面向对象编程语言,它的所有特性,使其独一无二。因此,学习特定于Rust的设计模式是必要的。本系列文章为作者学习《Rust设计模式》的学习笔记以及自己的见解。因此,本系列文章的结构也与此书的结构相同(后续可能会调成结构),基本上分为三个部分
- 回溯 Leetcode 332 重新安排行程
mmaerd
Leetcode刷题学习记录leetcode算法职场和发展
重新安排行程Leetcode332学习记录自代码随想录给你一份航线列表tickets,其中tickets[i]=[fromi,toi]表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从JFK开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。例如,行程[“JFK”,“LGA”]与[“JFK”,“LGB
- 每日一题——第九十题
互联网打工人no1
C语言程序设计每日一练c语言
题目:判断子串是否与主串匹配#include#include#include//////判断子串是否在主串中匹配//////主串///子串///boolisSubstring(constchar*str,constchar*substr){intlenstr=strlen(str);//计算主串的长度intlenSub=strlen(substr);//计算子串的长度//遍历主字符串,对每个可能得
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- 《庄子.达生9》
钱江潮369
【原文】孔子观于吕梁,县水三十仞,流沫四十里,鼋鼍鱼鳖之所不能游也。见一丈夫游之,以为有苦而欲死也,使弟子并流而拯之。数百步而出,被发行歌而游于塘下。孔子从而问焉,曰:“吾以子为鬼,察子则人也。请问,‘蹈水有道乎’”曰:“亡,吾无道。吾始乎故,长乎性,成乎命。与齐俱入,与汩偕出,从水之道而不为私焉。此吾所以蹈之也。”孔子曰:“何谓始乎故,长乎性,成乎命?”曰:“吾生于陵而安于陵,故也;长于水而安于
- 水泥质量纠纷案代理词
徐宝峰律师
贵州领航建设有限公司诉贵州纳雍隆庆乌江水泥有限公司产品质量纠纷案代理词尊敬的审判长、审判员:贵州千里律师事务所接受被告贵州纳雍隆庆乌江水泥有限公司的委托,指派我担任其诉讼代理人,参加本案的诉讼活动。下面,我结合本案事实和相关法律规定发表如下代理意见,供合议庭评议案件时参考:原告应当举证证明其遭受的损失与被告生产的水泥质量的因果关系。首先水泥是一种粉状水硬性无机胶凝材料。加水搅拌后成浆体,能在空气中
- 2019-12-22-22:30
涓涓1016
今天是冬至,写下我的日更,是因为这两天的学习真的是能量的满满,让我看到了自己,未来另外一种可能性,也让我看到了这两年这几年的过程中我所接受那些痛苦的来源。一切的根源和痛苦都来自于人生,家庭,而你的原生家庭,你的爸爸和妈妈,是因为你这个灵魂在那一刻选择他们作为你的爸爸和妈妈来的,所以你得接受他,你得接纳他,他就是因为他的存在而给你的学习和成长带来这些痛苦,那其实是你必然要经历的这个过程,当你去接纳的
- Goolge earth studio 进阶4——路径修改与平滑
陟彼高冈yu
Googleearthstudio进阶教程旅游
如果我们希望在大约中途时获得更多的城市鸟瞰视角。可以将相机拖动到这里并创建一个新的关键帧。camera_target_clip_7EarthStudio会自动平滑我们的路径,所以当我们通过这个关键帧时,不是一个生硬的角度,而是一个平滑的曲线。camera_target_clip_8路径上有贝塞尔控制手柄,允许我们调整路径的形状。右键单击,我们可以选择“平滑路径”,这是默认的自动平滑算法,或者我们可
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 18-115 一切思考不能有效转化为行动,都TM是扯淡!
成长时间线
7月25号写了一篇关于为什么会断更如此严重的反思,然而,之后日更仅仅维持了一周,又出现了这次更严重的现象。从8月2号到昨天8月6号,5天!又是5天没有更文!虽然这次断更时间和上次一样,那为什么说这次更严重?因为上次之后就分析了问题的原因,以及应该如何解决,按理说应该会好转,然而,没过几天严重断更的现象再次出现,想想,经过反思,问题依然没有解决与改变,这让我有些担忧。到底是哪里出了问题,难道我就真的
- 山东大学小树林支教调研团青青仓木队——翟晓楠
山东大学青青仓木队
过了半年,又一次启程,又一次回到支教的初心之地。比起上一次的试探与不安,我更多了一丝稳重与熟练。心境、处境也都随着半个学期的过去而变得不同,半个学期中,身体上的,心理上的,太多的逆境让我变得步履维艰,曲曲折折,弯弯绕绕,我仿佛打不起精神,没有胃口,没有动力。感觉走的不顺畅的时候,支教这个旅程,给了我力量。自告奋勇承担起队长这一职务的我,从组织时的复杂和困难的经历,协调各种问题,从无到有,和校长和队
- 直返最高等级与直返APP:无需邀请码的返利新体验
古楼
随着互联网的普及和电商的兴起,直返模式逐渐成为一种流行的商业模式。在这种模式下,消费者通过购买产品或服务,获得一定的返利,并可以分享给更多的人。其中,直返最高等级和直返APP是直返模式中的重要概念和工具。本文将详细介绍直返最高等级的概念、直返APP的使用以及与邀请码的关系。【高省】APP(高佣金领导者)是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,运行三年,稳定可靠。高省APP,
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- mysql主从数据同步
林鹤霄
mysql主从数据同步
配置mysql5.5主从服务器(转)
教程开始:一、安装MySQL
说明:在两台MySQL服务器192.168.21.169和192.168.21.168上分别进行如下操作,安装MySQL 5.5.22
二、配置MySQL主服务器(192.168.21.169)mysql -uroot -p &nb
- oracle学习笔记
caoyong
oracle
1、ORACLE的安装
a>、ORACLE的版本
8i,9i : i是internet
10g,11g : grid (网格)
12c : cloud (云计算)
b>、10g不支持win7
&
- 数据库,SQL零基础入门
天子之骄
sql数据库入门基本术语
数据库,SQL零基础入门
做网站肯定离不开数据库,本人之前没怎么具体接触SQL,这几天起早贪黑得各种入门,恶补脑洞。一些具体的知识点,可以让小白不再迷茫的术语,拿来与大家分享。
数据库,永久数据的一个或多个大型结构化集合,通常与更新和查询数据的软件相关
- pom.xml
一炮送你回车库
pom.xml
1、一级元素dependencies是可以被子项目继承的
2、一级元素dependencyManagement是定义该项目群里jar包版本号的,通常和一级元素properties一起使用,既然有继承,也肯定有一级元素modules来定义子元素
3、父项目里的一级元素<modules>
<module>lcas-admin-war</module>
<
- sql查地区省市县
3213213333332132
sqlmysql
-- db_yhm_city
SELECT * FROM db_yhm_city WHERE class_parent_id = 1 -- 海南 class_id = 9 港、奥、台 class_id = 33、34、35
SELECT * FROM db_yhm_city WHERE class_parent_id =169
SELECT d1.cla
- 关于监听器那些让人头疼的事
宝剑锋梅花香
画图板监听器鼠标监听器
本人初学JAVA,对于界面开发我只能说有点蛋疼,用JAVA来做界面的话确实需要一定的耐心(不使用插件,就算使用插件的话也没好多少)既然Java提供了界面开发,老师又要求做,只能硬着头皮上啦。但是监听器还真是个难懂的地方,我是上了几次课才略微搞懂了些。
- JAVA的遍历MAP
darkranger
map
Java Map遍历方式的选择
1. 阐述
对于Java中Map的遍历方式,很多文章都推荐使用entrySet,认为其比keySet的效率高很多。理由是:entrySet方法一次拿到所有key和value的集合;而keySet拿到的只是key的集合,针对每个key,都要去Map中额外查找一次value,从而降低了总体效率。那么实际情况如何呢?
为了解遍历性能的真实差距,包括在遍历ke
- POJ 2312 Battle City 优先多列+bfs
aijuans
搜索
来源:http://poj.org/problem?id=2312
题意:题目背景就是小时候玩的坦克大战,求从起点到终点最少需要多少步。已知S和R是不能走得,E是空的,可以走,B是砖,只有打掉后才可以通过。
思路:很容易看出来这是一道广搜的题目,但是因为走E和走B所需要的时间不一样,因此不能用普通的队列存点。因为对于走B来说,要先打掉砖才能通过,所以我们可以理解为走B需要两步,而走E是指需要1
- Hibernate与Jpa的关系,终于弄懂
avords
javaHibernate数据库jpa
我知道Jpa是一种规范,而Hibernate是它的一种实现。除了Hibernate,还有EclipseLink(曾经的toplink),OpenJPA等可供选择,所以使用Jpa的一个好处是,可以更换实现而不必改动太多代码。
在play中定义Model时,使用的是jpa的annotations,比如javax.persistence.Entity, Table, Column, OneToMany
- 酸爽的console.log
bee1314
console
在前端的开发中,console.log那是开发必备啊,简直直观。通过写小函数,组合大功能。更容易测试。但是在打版本时,就要删除console.log,打完版本进入开发状态又要添加,真不够爽。重复劳动太多。所以可以做些简单地封装,方便开发和上线。
/**
* log.js hufeng
* The safe wrapper for `console.xxx` functions
*
- 哈佛教授:穷人和过于忙碌的人有一个共同思维特质
bijian1013
时间管理励志人生穷人过于忙碌
一个跨学科团队今年完成了一项对资源稀缺状况下人的思维方式的研究,结论是:穷人和过于忙碌的人有一个共同思维特质,即注意力被稀缺资源过分占据,引起认知和判断力的全面下降。这项研究是心理学、行为经济学和政策研究学者协作的典范。
这个研究源于穆来纳森对自己拖延症的憎恨。他7岁从印度移民美国,很快就如鱼得水,哈佛毕业
- other operate
征客丶
OSosx
一、Mac Finder 设置排序方式,预览栏 在显示-》查看显示选项中
二、有时预览显示时,卡死在那,有可能是一些临时文件夹被删除了,如:/private/tmp[有待验证]
--------------------------------------------------------------------
若有其他凝问或文中有错误,请及时向我指出,
我好及时改正,同时也让我们一
- 【Scala五】分析Spark源代码总结的Scala语法三
bit1129
scala
1. If语句作为表达式
val properties = if (jobIdToActiveJob.contains(jobId)) {
jobIdToActiveJob(stage.jobId).properties
} else {
// this stage will be assigned to "default" po
- ZooKeeper 入门
BlueSkator
中间件zk
ZooKeeper是一个高可用的分布式数据管理与系统协调框架。基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题。网上对ZK的应用场景也有不少介绍,本文将结合作者身边的项目例子,系统地对ZK的应用场景进行一个分门归类的介绍。
值得注意的是,ZK并非天生就是为这些应用场景设计的,都是后来众多开发者根据其框架的特性,利
- MySQL取得当前时间的函数是什么 格式化日期的函数是什么
BreakingBad
mysqlDate
取得当前时间用 now() 就行。
在数据库中格式化时间 用DATE_FORMA T(date, format) .
根据格式串format 格式化日期或日期和时间值date,返回结果串。
可用DATE_FORMAT( ) 来格式化DATE 或DATETIME 值,以便得到所希望的格式。根据format字符串格式化date值:
%S, %s 两位数字形式的秒( 00,01,
- 读《研磨设计模式》-代码笔记-组合模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
abstract class Component {
public abstract void printStruct(Str
- 4_JAVA+Oracle面试题(有答案)
chenke
oracle
基础测试题
卷面上不能出现任何的涂写文字,所有的答案要求写在答题纸上,考卷不得带走。
选择题
1、 What will happen when you attempt to compile and run the following code? (3)
public class Static {
static {
int x = 5; // 在static内有效
}
st
- 新一代工作流系统设计目标
comsci
工作算法脚本
用户只需要给工作流系统制定若干个需求,流程系统根据需求,并结合事先输入的组织机构和权限结构,调用若干算法,在流程展示版面上面显示出系统自动生成的流程图,然后由用户根据实际情况对该流程图进行微调,直到满意为止,流程在运行过程中,系统和用户可以根据情况对流程进行实时的调整,包括拓扑结构的调整,权限的调整,内置脚本的调整。。。。。
在这个设计中,最难的地方是系统根据什么来生成流
- oracle 行链接与行迁移
daizj
oracle行迁移
表里的一行对于一个数据块太大的情况有二种(一行在一个数据块里放不下)
第一种情况:
INSERT的时候,INSERT时候行的大小就超一个块的大小。Oracle把这行的数据存储在一连串的数据块里(Oracle Stores the data for the row in a chain of data blocks),这种情况称为行链接(Row Chain),一般不可避免(除非使用更大的数据
- [JShop]开源电子商务系统jshop的系统缓存实现
dinguangx
jshop电子商务
前言
jeeshop中通过SystemManager管理了大量的缓存数据,来提升系统的性能,但这些缓存数据全部都是存放于内存中的,无法满足特定场景的数据更新(如集群环境)。JShop对jeeshop的缓存机制进行了扩展,提供CacheProvider来辅助SystemManager管理这些缓存数据,通过CacheProvider,可以把缓存存放在内存,ehcache,redis,memcache
- 初三全学年难记忆单词
dcj3sjt126com
englishword
several 儿子;若干
shelf 架子
knowledge 知识;学问
librarian 图书管理员
abroad 到国外,在国外
surf 冲浪
wave 浪;波浪
twice 两次;两倍
describe 描写;叙述
especially 特别;尤其
attract 吸引
prize 奖品;奖赏
competition 比赛;竞争
event 大事;事件
O
- sphinx实践
dcj3sjt126com
sphinx
安装参考地址:http://briansnelson.com/How_to_install_Sphinx_on_Centos_Server
yum install sphinx
如果失败的话使用下面的方式安装
wget http://sphinxsearch.com/files/sphinx-2.2.9-1.rhel6.x86_64.rpm
yum loca
- JPA之JPQL(三)
frank1234
ormjpaJPQL
1 什么是JPQL
JPQL是Java Persistence Query Language的简称,可以看成是JPA中的HQL, JPQL支持各种复杂查询。
2 检索单个对象
@Test
public void querySingleObject1() {
Query query = em.createQuery("sele
- Remove Duplicates from Sorted Array II
hcx2013
remove
Follow up for "Remove Duplicates":What if duplicates are allowed at most twice?
For example,Given sorted array nums = [1,1,1,2,2,3],
Your function should return length
- Spring4新特性——Groovy Bean定义DSL
jinnianshilongnian
spring 4
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装Mysql5.5
liuxingguome
centos
CentOS下以RPM方式安装MySQL5.5
首先卸载系统自带Mysql:
yum remove mysql mysql-server mysql-libs compat-mysql51
rm -rf /var/lib/mysql
rm /etc/my.cnf
查看是否还有mysql软件:
rpm -qa|grep mysql
去http://dev.mysql.c
- 第14章 工具函数(下)
onestopweb
函数
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- POJ 1050
SaraWon
二维数组子矩阵最大和
POJ ACM第1050题的详细描述,请参照
http://acm.pku.edu.cn/JudgeOnline/problem?id=1050
题目意思:
给定包含有正负整型的二维数组,找出所有子矩阵的和的最大值。
如二维数组
0 -2 -7 0
9 2 -6 2
-4 1 -4 1
-1 8 0 -2
中和最大的子矩阵是
9 2
-4 1
-1 8
且最大和是15
- [5]设计模式——单例模式
tsface
java单例设计模式虚拟机
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点
安全的单例模式:
/*
* @(#)Singleton.java 2014-8-1
*
* Copyright 2014 XXXX, Inc. All rights reserved.
*/
package com.fiberhome.singleton;
- Java8全新打造,英语学习supertool
yangshangchuan
javasuperword闭包java8函数式编程
superword是一个Java实现的英文单词分析软件,主要研究英语单词音近形似转化规律、前缀后缀规律、词之间的相似性规律等等。Clean code、Fluent style、Java8 feature: Lambdas, Streams and Functional-style Programming。
升学考试、工作求职、充电提高,都少不了英语的身影,英语对我们来说实在太重要
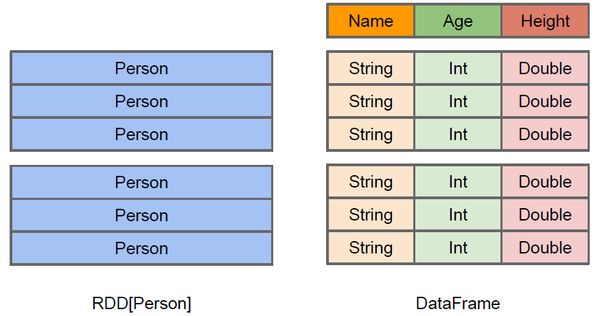 spark RDD与Dataframe区别.png
spark RDD与Dataframe区别.png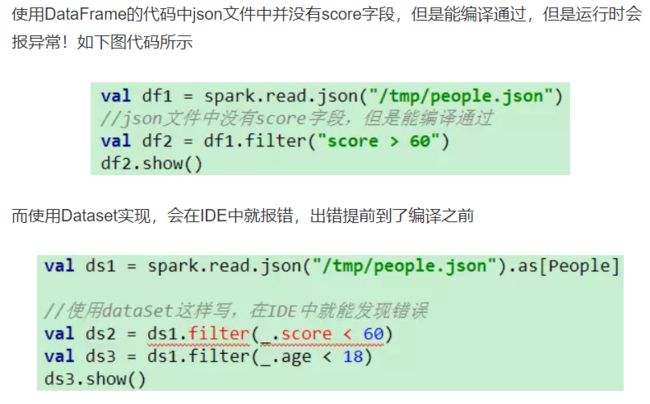 spark df和ds在编译方面的区别.PNG
spark df和ds在编译方面的区别.PNG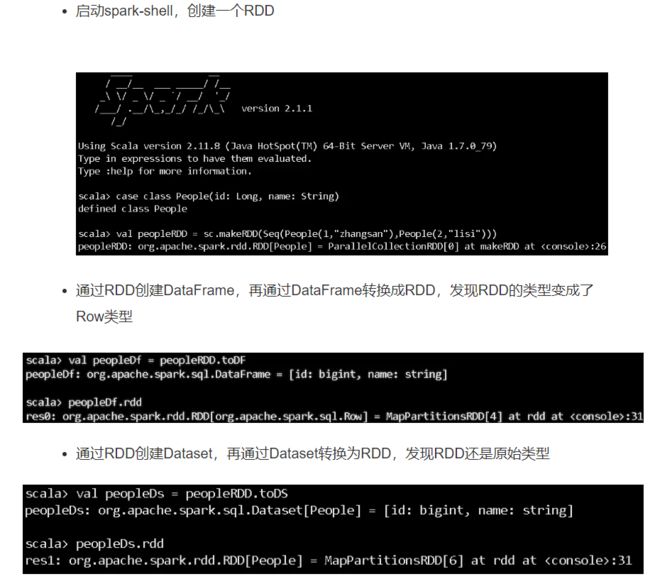 spark RDD与ds相互转换.PNG
spark RDD与ds相互转换.PNG