线性回归、机器学习、感知机到神经网络
线性回归和机器学习
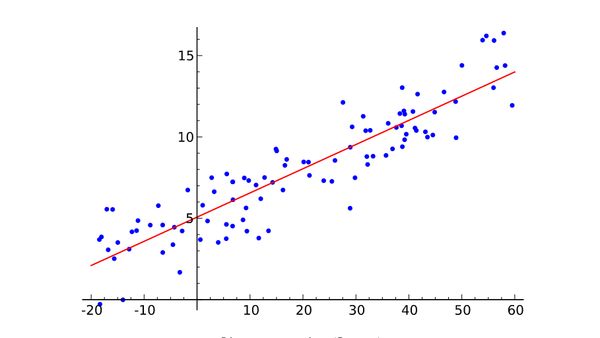
首先简单介绍一下机器学习是什么。从二维图像上取一些点,尽可能绘出一条拟合这些点的直线。你刚才做的就是从几对输入值(x)和输出值(y)的实例中概括出一个一般函数,任何输入值都会有一个对应的输出值。这叫做线性回归,一个有着两百年历史从一些输入输出对组中推断出一般函数的技巧。这就是它很棒的原因:很多函数难以给出明确的方程表达,但是,却很容易在现实世界搜集到输入和输出值实例——比如,将说出来的词的音频作为输入,词本身作为输出的映射函数。
线性回归对于解决语音识别这个问题来说有点太无用,但是,它所做的基本上就是监督式机器学习:给定训练样本,「学习」一个函数,每一个样本数据就是需要学习的函数的输入输出数据。尤其是,机器学习应该推导出一个函数,它能够很好地泛化到不在训练集中的输入值上,既然我们真的能将它运用到尚未有输出的输入中。例如,谷歌的语音识别技术由拥有大量训练集的机器学习驱动,但是,它的训练集也不可能大到包含你手机所有语音输入。
泛化能力机制如此重要,以至于总会有一套测试数据组(更多的输入值与输出值样本)这套数据组并不包括在训练组当中。通过观察有多少个正确计算出输入值所对应的输出值的样本,这套单独数据组可以用来估测机器学习技术有效性。概括化的克星是过度拟合——学习一个对于训练集有效但是却在测试数据组中表现很差的函数。既然机器学习研究者们需要用来比较方法有效性的手段,随着时间的推移,标准训练数据组以及测试组可被用来评估机器学习算法。
感知机
事实上线性回归和机器学习一开始的方法构想,弗兰克· 罗森布拉特(Frank Rosenblatt)的感知机, 有些许相似性。
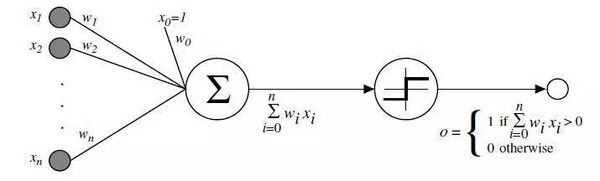
心理学家Rosenblatt构想了感知机,它作为简化的数学模型解释大脑神经元如何工作:它取一组二进制输入值(附近的神经元),将每个输入值乘以一个连续值权重(每个附近神经元的突触强度),并设立一个阈值,如果这些加权输入值的和超过这个阈值,就输出1,否则输出0(同理于神经元是否放电)。对于感知机,绝大多数输入值不是一些数据,就是别的感知机的输出值。
这一关于神经元的模型是建立在沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮兹(Walter Pitts)工作上的。他们曾表明,把二进制输入值加起来,并在和大于一个阈值时输出1,否则输出0的神经元模型,可以模拟基本的或/与/非逻辑函数。这在人工智能的早期时代可不得了——当时的主流思想是,计算机能够做正式的逻辑推理将本质上解决人工智能问题。
麦卡洛克-皮兹模型缺乏一个对AI而言至关重要的学习机制。这就是感知机更出色的地方所在——罗森布拉特受到唐纳德·赫布(Donald Hebb) 基础性工作的启发,想出一个让这种人工神经元学习的办法。赫布提出了一个出人意料并影响深远的想法,称知识和学习发生在大脑主要是通过神经元间突触的形成与变化,简要表述为赫布法则:
当细胞A的轴突足以接近以激发细胞B,并反复持续地对细胞B放电,一些生长过程或代谢变化将发生在某一个或这两个细胞内,以致A作为对B放电的细胞中的一个,效率增加。
感知机并没有完全遵循这个想法,但通过调输入值的权重,可以有一个非常简单直观的学习方案:给定一个有输入输出实例的训练集,感知机应该「学习」一个函数:对每个例子,若感知机的输出值比实例低太多,则增加它的权重,否则若设比实例高太多,则减少它的权重。
罗森布拉特用定制硬件的方法实现了感知机的想法(在花哨的编程语言被广泛使用之前),展示出它可以用来学习对20×20像素输入中的简单形状进行正确分类。自此,机器学习问世了——建造了一台可以从已知的输入输出对中得出近似函数的计算机。
很重要的是,这种方法还可以用在多个输出值的函数中,或具有多个类别的分类任务。这对一台感知机来说是不可能完成的,因为它只有一个输出,但是,多输出函数能用位于同一层的多个感知机来学习,每个感知机接收到同一个输入,但分别负责函数的不同输出。实际上,神经网络(准确的说应该是「人工神经网络(ANN,Artificial Neural Networks)」)就是多层感知机(今天感知机通常被称为神经元)而已,只不过在这个阶段,只有一层——输出层。所以,神经网络的典型应用例子就是分辨手写数字。输入是图像的像素,有10个输出神经元,每一个分别对应着10个可能的数字。在这个案例中,10个神经元中,只有1个输出1,权值最高的和被看做是正确的输出,而其他的则输出0。
感知机的缺点
感知机是线性的模型,其不能表达复杂的函数,不能出来线性不可分的问题,其连异或问题(XOR)都无法解决,因为异或问题是线性不可分的,怎样解决这个问题呢,通常有两种做法。
其一:用更多的感知机去进行学习,这也就是人工神经网络的由来。
其二:用非线性模型,核技巧,如SVM进行处理。
神经网络
神经网络实际上就是将大量之前讲到的感知机进行组合,用不同的方法进行连接并作用在不同的激活函数上。
我们简单介绍下前向神经网络,其具有以下属性:
1. 一个输入层,一个输出层,一个或多个隐含层。上图所示的神经网络中有一个四神经元的输入层、一个三神经元的隐含层、一个二神经元的输出层。
2. 每一个神经元都是一个上文提到的感知机。
3.输入层的神经元作为隐含层的输入,同时隐含层的神经元也是输出层神经元的输入。
4. 每条建立在神经元之间的连接都有一个权重w(与感知机中提到的权重类似)。
5. 在t层的每个神经元通常与前一层(t - 1层)中的每个神经元都有连接(但你可以通过将这条连接的权重设为0来断开这条连接)。
6. 为了处理输入数据,将输入向量赋到输入层中。然后这些值将被传播到隐含层,通过加权传递函数传给每一个隐含层神经元(这就是前向传播),隐含层神经元再计算输出(激活函数)。
7. 输出层和隐含层一样进行计算,输出层的计算结果就是整个神经网络的输出。
如果每一个感知机都只能使用一个线性激活函数会怎么样?整个网络的最终输出也仍然是将输入数据通过一些线性函数计算过一遍,只是用一些在网络中收集的不同权值调整了一下。换名话说,再多线性函数的组合还是线性函数。如果我们限定只能使用线性激活函数的话,前馈神经网络其实比一个感知机强大不到哪里去,无论网络有多少层。正是这个原因,大多数神经网络都是使用的非线性激活函数,如对数函数、双曲正切函数、阶跃函数、整流函数等。