Keynote地址(Dropbox)
Pieter Abbeel在刚刚过去的NIPS2017大会上做了一个讲话,总结了把深度学习应用在机器人身上遇到的种种问题,他为了解决这些问题所做的探索和工作,和推崇Meta Learning(元学习)。我非常欣赏Pieter Abbeel的研究。他自博士毕业以后做了许多Deep Reinforcement Learning的工作,把深度学习和强化学习结合,力图调教出更好的机器人。与许多理论家不同, 他的研究一般始于解决一个确切的问题。虽然他的解法不一定完美,但他的探索给我许多灵感。我希望能用中文简单概括一下他的讲话,让更多人接触到他的工作。
简单介绍一下Deep Reinforcement Learning(DRL)
Reinforcement Learning (RL)指名为强化学习的框架。这个框架让算法自行选择动作,与环境互动,收到反馈,进行探索。一般情况下,算法可以感知其所处的状态(state),根据当前状态选择动作(action),执行动作后收到反馈(reward)。一般反馈是一个数字,越大越好。算法收到反馈后会更新内部机制,使其在将来遇到相同情况(revisitng the same state)时做出更有利的动作。举一个简单例子,如果机器在玩吃豆子这个游戏时,发现吃掉前面的豆子能得到奖励,那么下次,机器在面对一个豆子时,就更可能去吃掉豆子。
Value Function Approximation是一种强化学习的学习方法。这种学习方法的目标是学习每个状态的好坏。通常此类算法会给每个状态一个打分。这样,在遇到某状态时,我们可以选择一个动作去最大化下一个状态的奖励。
End-to-end Reinforcement Learning 是另一种强化学习的学习方法。这种学习方法试图学习:给出当前的状态,我该采取什么行动?这个方法叫做end-to-end,因为它不需要人为地在中间干预。其他的方法,比如Value Function Approximate),需要几次操作:机器给状态打分,机器挑选动作去往高分状态。而这个方法里,机器自己想办法找出哪个动作有利。在深度学习以前,这个方法不容易写成代码(因为很难让机器意识到哪个动作是当前状态的最优动作),所以直到深度学习复兴才火爆起来。
Deep Learning(DL)指深度学习,或神经网络学习(Deep Neural Net)。它利用神经网络可以拟合任意函数的特性,被应用于各种拟合函数。比如,在DRL中,DL可以负责计算给定任意状态时的最优动作。
Abbeel讲话的概要
在这篇讲话中,Abbeel罗列了他所见的DRL的几大问题,并给出了他的团队为了解决这些问题的探索研究。本文着重列出三个Abbeel指出的问题,分别分析一篇Abbeel的对应的工作。对其他工作感兴趣的,可以看看他发的Keynote。
Faster Reinforcement Learning
问题描述:一般,Deep Learning需要很多步梯度下降,才能成功拟合函数;而Reinforcement Learning也需要探索一个环境很久,观察状态的不同动作导致的结果,才能学到如何做动作。两者放在一起,简直就是噩梦。举例来说,一个人来玩俄罗斯方块,几分钟就上手了;而一个机器要训练好几小时或几天才能达到人类刚刚上手的水准。
观察:现有的RL中套用的学习方法,比如TRPO,DQN,A3C,DDPG,PPO等算法,都是非常通用的算法。因此,不管给算法什么样子的状态或者环境,它都可以慢慢学习。但实际生活中,算法会遇到的状态其实没有那么多。举例而言,如果我在玩一个赛车游戏,那么大部分情况下这个车都是在赛道上跑;而算法却是准备了很多不会遇到的情况:车子在半空中跑;车子倒着跑;俄罗斯方块在跑……等等。
RL^2:RL^2是Abbeel团队投给ICLR2017会议的论文(好像被拒了hhh)。传统的RL算法,在训练结束后,只能玩一个游戏。即使有RL算法可以玩Atari这一套游戏,它要求每一个小游戏的状态必须长得不一样,否则机器会弄混它到底在玩哪个游戏。这篇论文试图解决:假设我不知道我在玩什么游戏,我可不可以记一下我每一步走到哪里了,记下环境的反馈,来推测我在哪个游戏,因此做决策。具体来说,这篇用一个RNN(Recurrent Neural Net)来生成对应状态的动作;用RL的算法来负责更新RNN的参数。直觉上讲,RNN可以考虑以前时间发生的事情,用这些信息来帮助做决策。
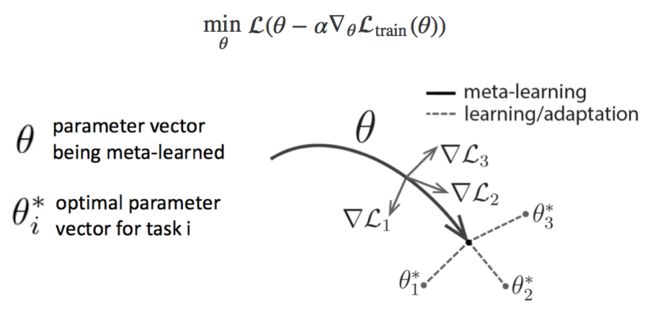
Model Agnostic Meta Learning:arXiv链接。这篇文章假设我们要玩好几个游戏。它要提出一个还不错的基础模型(Base Model),我们在玩每个游戏的时候只要小小改动一下基础模型,就能在几个游戏里各自取得不错的成绩。为了计算这个基础模型,这个文章并不要求这个基础模型能在每个游戏里取得好成绩,却要求:如果每个游戏里各自改了基础模型,他们改动过的模型应该取得好成绩。
Long Horizon Reasoning
问题描述:在RL中,机器一般要很久才能收到有效的反馈。比如我们在玩吃豆子,然后我操纵主角走进了迷宫,过了一会,我被敌人挂了。虽然机器立刻知道,主角跟敌人太近会导致不好的后果,它却要重复经历很多次才能学习到,主角一开始不该走进迷宫。
观察:我们在操纵小人时,我们想的是:我要一直走直线直到我到某个地方;而算法设计里,机器每秒都得做很多决策(向前~向前~向前~向前~)。实际这些决策有很多冗余。如果我们能有一个大方向决策器(我要向前走)和小方向决策器(我怎么操纵我的身体向前走),那么我们可以免去许多冗余,并且让大方向决策器更容易搞明白哪个决策更有利。
Meta Learning Shared Hierarchies: 这篇是前阵子上了新闻的论文,一作是KevinFrans,一个在OpenAI实习的高中生,大家可以去他网站瞧瞧。很佩服他一个高中生就有勇气去追求自己喜欢的东西,希望我们国家也可以出现一些不拘一格的人才。我个人非常喜欢这篇文章,它的灵感可以很容易运用到Vision/NLP。这篇文章主要提出大方向决策器和小方向决策器,并提出一种训练他们的方法。具体一点,大方向决策器根据现在状态决定接下来几个回合采用的策略,由对应的小方向决策器运行一定回合并返回大方向决策器。
Taskability
问题:有时候让机器慢慢学实在很麻烦,比如操纵机器人就得让机器人自己随意摆弄身上每一个部件,然后慢慢搞明白他们的作用。应对这种情况,有时会用Imitation Learning(模仿学习):给机器人一些演示,让他们模仿演示的动作。问题是,这种方法学出来的动作非常死板。而且由于现在机器人部件的灵敏度等等问题,没有办法精细地操控(manipulation)或模仿。举个例子,如果我训练一个模仿学习模型来操纵无人机。那么很可能,无人机会飞的歪歪扭扭,并且时常瞎转圈等等。并且,模仿学习一般也是只能学一个问题,不能完成好几个task。
One Shot Imitation Learning:这篇论文提出一个比较通用的模仿学习的方法。这个方法在运行时,需要一个完成当前任务的完整演示,和当前状态。假设我要机器人搭方块,那么我给它一个完整的把方块搭好的视频演示,再告诉他当前方块都在哪里。这个模型会用CNN和RNN来处理任务的演示,这样,它就有一个压缩过的演示纲要。模型再用CNN处理当前状态,得到一个压缩过的当前状态信息。利用Attention Model来扫描演示纲要,我们就得到了“与当前状态最有关的演示的步骤”,再将这些信息全部传递给一个决策器。然后输出决策。具体的模型有很多细节,但大致流程如下:

对这一方向有兴趣的欢迎来博客/邮件探讨。
原创:Liyiming Ke (https://kelym.github.io)
转载请注明作者