1.引言
第一章的时候讲了 进化性, 就是应对不断变化的需求
如果说数据模型变了,我们的表以及业务代码也要相应变化,比如说多了一个字段等等
对于关系型数据库,是有schema的,通过修改schema来应对变化的结构(如alter语句)
对于文档性,schema less的(也是schema on read)的,需要自行兼容新老数据结构
当数据变化的时候,要考虑两个问题
向前兼容性:
新的代码能够解析旧的数据
向后兼容性:
老的代码能够读出新的数据(忽略掉新的属性)
向后兼容更难一点
这一张讲解encoding data的几种格式,包含json,xml,proto buff,thrift和avro
讲解他们如何处理schema的变化,保证新旧数据的共存,并且讲解在REST和RPC中的作用
2.数据的format以及序列化
数据往往有两种表现形式:
1.内存中,用object,structs,list等记录
2.bytes串,当需要把数据进行持久化或网络发送的时候
当两种表现形式进行转换的时候,就需要encoding技术(java中称为序列化)
有很多第三方的包提供这个功能,但是往往有下面几个问题
1.针对特定的语言:encoding时用A语言,那么decoding的时候往往也要A语言
2.安全性:如果encode和decode方式泄露了很不安全
3.考虑兼容性:向前向后兼容
4.效率(encode和decode时间,序列化出来的bytes长度等)
2.1 json,xml以及二进制变种
json,xml比较常见
xml因为过于详细,和不必要的负责而被批评。
json由于支持浏览器(js的一部分)而流行。
但是依旧有一些问题
- 编码数字时有歧义,xml无法区分String还是Number
- json和xml支持Unicode字符集但是不支持binary string,使得data size变大
- json和xml有一些可选的schema,但是太强大太复杂了
2.1.1 二进制变种
json没有xml那么详细,但是相对二进制format,仍然用了很多空间,
有一些JSON变种如 MessagePack,BSON,BJSON等
还有些XML变种如WBXML等
比如json串如下
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
用MessagePack表示如下

从json的81字节到MessagePack的66字节
是否值得为了这么小的空间压缩而失去可读性,尚不明确
2.2 Thrift和protocal buffers
Thrift是Facebook开发的,pbf是谷歌开发的,都需要interface definition language(IDL),
PBF的例子如下
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
都有一个code生成器,根据schema的定义,用不同的语言生成classes来实现这个schema
比如Thrift的CompactProtocol如下,
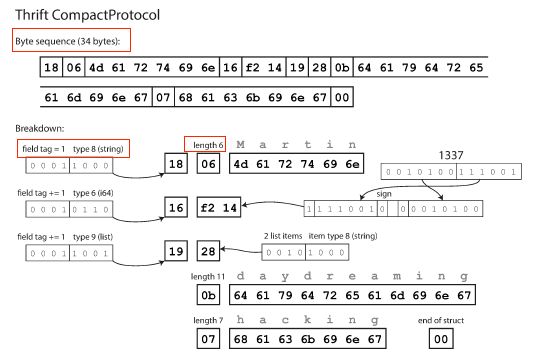
和上面MessagePack的区别就是不包含field names,如“userName”,“favoriteNumber”这些内容
只用了field tags(1,2,3)
2.2.1 field tags与schema的变动
之前说schema不可避免的会有改动,称为schema evolution,Thrift和PBF如何处理前后的兼容性呢?
改字段的名字:IDL里面用field tags替代了field names,因此只要filed tags不变,decode方就可以正常处理
添加field:旧的代码忽略掉它不认识的field tags即可(向后兼容),但是要求这个field在IDL定义中不能使required
否则解析旧数据出错。新的代码依然能够处理旧的field,因为旧的tags能够识别(向前兼容)
删除field:同上,旧代码读新数据时忽略掉不认识的tag,新代码读旧数据时处理它知道的tags即可
但是要求删掉的fields的tags以后也不能再用
2.2.2 数据类型与schema的变动
如果改变field的数据类型怎么办,详情看文档,但是有损失精度以及截断的风险
比如32位改成了64位,旧的代码不一定能处理新的数据
2.3 Avro
是Hadoop的一个子项目,IDL如下
record Person {
string userName;
union { null, long } favoriteNumber = null;
array interests;
}
序列化后,内容如下
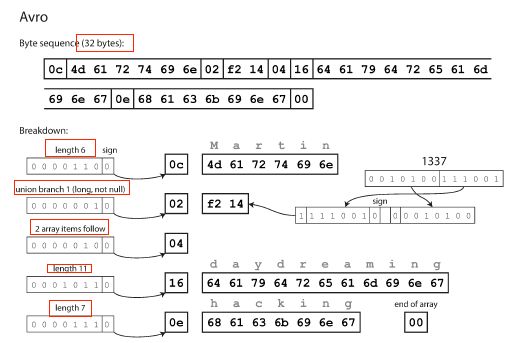
首先注意IDL里面没有tag number
序列化后内容没有标识是哪一个字段,数据类型是什么
这样的话,要求数据decode时用的schema和写时的schema完全一样才行。
那么如何处理schema改动的问题呢?
2.3.1 写schema和读schema
encode的时候会有一个写schema
decode的时候会有一个读schema
Avro不要求两个一样,只要两个兼容即可
Avro的包会解决两个schema的差异,通过比较两个schema
解决方法如下

如果两个schema顺序不同,会通过匹配field name来解决
如果read schema遇到了只在write schema出现的field,那么会忽略掉
如果read schema遇到了自己希望有但是write schema未出现的field,那么填充默认值
2.3.2 schema改动规则
前后的兼容性要求添加或者删除field时,field需要有一个默认值。
其他一些改动只有向前兼容不具有向后兼容:
如改动field name则只满足向前兼容(类似于field name有一个alias)
等等
2.3.3 read schema怎么知道write schema是怎样的
分几个场景
有很多记录的大文件:如hadoop,所有的记录的schema都是一样的,因此直接把write schema记录在file中即可
有不同write schema写记录的数据库:每一个记录新加一个write schema version number,加一个write schema的表,这样reader获取record时通过version找到对应的write schema
网络发送记录:双方协商好schema,之后进行RPC调用
2.3.4 动态生成schema
Avro对于动态变化的schema更友好,直接生成一个新的schema就好了
而Thrift和PBF面对动态变化的schema的时候,则需要手动控制好field tags(个人感觉类似于自增主键的管理)
2.3.5 代码生成以及动态类型语言
Thrift和PBF依赖代码生成,即根据schema生成对应的class的代码,在静态类性语言中有效,如Java,C++等。默认不支持动态类型语言
Avro则既支持静态语言,也支持动态类型语言(python,js等)
2.4 schema的优点
相比JSON,XML来说,上面的Thrift,PBF,Avro有很多优点:
- 数据压缩的更小
- schema能够表示文档,记录的一种组织形式
- 记录下schema能够更好的保证前后兼容性
- 对于静态类型语言,schema能够generate code的特性非常有用,能够进行编辑检查
3. 数据流的模式
上面讲了数据的encode和decode,那么是谁进行encode和decode呢,数据的发送方和接收方,是怎样进行数据的传输的呢,最主要有下面几种
数据库
服务调用(REST或者RPC)
异步消息处理
3.1 数据库的数据流
写入db的进程对数据进行encode,从db读数据的进程对数据进行decode
前后兼容性依然需要保证:新老代码都要能够处理新老schema的数据
另外在业务层的代码也要注意保证兼容性
比如

不同时期写下的记录
比如有5s前写下的记录,有5年前写的记录,但是两者的encoding是不一样的(因为不同的schema)
重启应用程序很快,但是重启db也不会改变它们的encoding,重复rewrite。
Rewrite和migrate都是可行的,但是是很重的操作。
一般是加一些有默认值的列进来,而不修改原有的数据。当旧的数据被读的时候,就塞入默认值。
3.2 REST和RPC的数据流
当网络通信时,最常见的是client和server交互。
server把API暴露在网络上,称为服务,并且client能够连接上server去请求API。
当然,server自己也可以作为client去调用其他服务,比如数据库
某种意义上,服务就类似数据库,允许client提交和查询数据,不过数据库只允许特定的sql语言,而应用的server方则暴露API。
所以同样的,client和server之间的数据encode和decode也要用兼容性。
3.2.1 web服务
把http作为底层协议调用的服务称为web服务
主要有两种形式,SOAP和REST
REST不是一个协议,是一个基于HTTP协议上的设计思路
强调用简单的数据形式,用URL来标示资源,以及HTTP的特性来完成控制认证等。相对SOAP更加流行
而SOAP就是用基于XML的如WSDL语言描述,在静态类型语言中有用,但是在动态类型语言中没那么有用。
并且不是人可读的,而且人为构建太复杂。
两者在这里不详细介绍了
3.2.2 RPC遇到的问题
RPC定义参照refer
目前网络请求相对本地调用,有这些问题
1.本地调用要么成功要么失败,而通过网络请求,要考虑丢包,延迟,超时等等。必须考虑这些情况,比如失败重试
2.本地调用要么返回结果,要么抛异常,要么死循环。而网络请求则可能由于超时而无法返回。此时根本不知道发生了什么,不知道请求是否发送过去了
3.网络传输,重试的时候,要求要有幂等性,即第一次请求和第二次同样的请求,得到的结果应该是一样的。而本地操作不用考虑这个问题。
4.网络调用要考虑网路情况,可能快可能慢。本地调用则更快
5.调用方法传递参数时,如果是基础类型还好,如果是自定义的很大的object,就会变得复杂(应该是考虑序列化之类的问题)
6.client和server如果用不同语言实现,那么数据类型从一个语言到另外一个语言可能会有问题,比如js的数字可以比2^53大
3.2.3 目前RPC的方向
尽管上述诸多问题,我们还是会用RPC。比如Thrift和Avro支持RPC,谷歌研发了gRPC等等。
有些框架提供了 服务发现功能,即允许client找到在哪个ip,port上有哪个服务。
而REST方便调试,被主流语言,平台支持,有一些的工具
因此公共API用RESTful
而同组织的内部服务调用,则用RPC好
3.2.4 数据encoding以及RPC的进化
对于进化性来说,RPC需要允许client和server进行改变并且独立部署。
合理假设RPC服务都是server先升级,然后client升级。
因此,只要考虑 request的向前兼容性(server处理)以及response的向后兼容性(client处理)即可
1.Thrift,gRPC(PBF),Avro的RPC都能根据encoding规则达到兼容性
2.SOAP用xml schema,能够达到兼容性但是有一些陷阱
3.RESTful API常用json串进行回复,用json或者URI-encoded/form-encoded进行请求。如果请求加入了可选册数,或者回复加入了新字段都被认为是变动
RPC常用于组织内部,使得服务兼容性更困难。
因为无法强制client升级,要一直保持兼容性。
如果有些破坏兼容性的改动,那么往往会终止对某些旧版本client的支持。
3.3 消息传递数据流
这里简单看看异步消息传递系统(就是消息队列)
它是介于RPC和db之间
像RPC是client发送请求(消息)到另一个处理进程
像DB是消息会间接的暂时存储在broker中(中间件)
broker相对RPC来说有以下优点
1.如果接收方挂了,broker还可以作为buffer
2.自动重发机制处理进程挂掉,避免消息遗失
3.不需要直接知道ip端口(部署在云上方便)
4.允许消息发送给多个接收方
5.逻辑上把sender和receiver分开,两者可以互相不知道
另外一个区别在于消息队列是单向的,发送方不会接收到接收方的回复,所以消息是异步处理的
3.3.1 message broker
最近很多开源实现如RabbitMQ,ActiveMQ以及Kafka等很流行。
通常,broker工作机制如下
一个进程发送消息到特定的queue或者topic。
然后broker保证消息发送到订阅了这个queue或者topic的receiver中。
当然也要考虑到兼容性问题,这里不展开对MQ的讨论
3.3.2 分布式actor框架
这个直接参照refer就好,书中简单介绍了下
4.总结
考虑到数据在网络传输,数据有序列化的需求。然后为了应对数据格式的变化(进化性),数据的encode和decode方需要有前后的兼容性。
讲解了几种序列化(Avro,Proto buff, Thrift)的方法,以及应对兼容性的处理.
再讨论了数据传输的几个场景(数据流):从DB,RPC以及REST API以及消息队列三个场景出发,介绍了背景以及编码以及兼容性的
5.思考
RPC和REST的思考
书中说REST更适合public API而RPC适合公司内部调用(3.2.3)
另外对RPC的兼容性的总结讲的太好了,公司内部server先升级再client升级,而如果作为public API,则往往要考虑client不能升级,终止某些client版本的服务等等(3.2.4)
数据流上
思考数据是如何encode和decode,怎样保证兼容性的,满足变化的需求
6.问题
讲Avro最后对动静态语言的支持(2.3.5),这一小部分不是非常理解,没有深入研究
对于REST我还不是很熟悉,后面再抽空看
7.refer
SOAP和RESTful
https://zh.wikipedia.org/wiki/SOAP
https://zh.wikipedia.org/wiki/%E5%85%B7%E8%B1%A1%E7%8A%B6%E6%80%81%E4%BC%A0%E8%BE%93
RPC
https://zh.wikipedia.org/wiki/%E9%81%A0%E7%A8%8B%E9%81%8E%E7%A8%8B%E8%AA%BF%E7%94%A8
actor framework 参与者模式
https://zh.wikipedia.org/wiki/%E5%8F%83%E8%88%87%E8%80%85%E6%A8%A1%E5%BC%8F