研一上学期上了多核软件设计,以及算法设计与分析的并行算法部分,其中算法的课程大作业是要使用MPI,openmp以及pthread实现大型稀疏矩阵的求解算法。下学期上了分布式与并行计算,主要了解了分布式计算的内容,学了MapReduce,Hadoop,Spark以及了解了虚拟化等相关技术,动手搭建了Hadoop集群,OpenStack云平台,算是对云计算有了初步的了解。
当前利用并行技术开发软件是一个趋势,无论是在移动的APP,桌面应用,还是在云服务应用领域,并行计算越来越得到开发者的关注。下面总结一下并行计算,也算是对这一段时间学习的总结,以下内容是作者学习中的总结,如果有错误请在评论区指出。
什么是并行计算
并行计算是相对于串行计算而言,比如一个矩阵相乘的例子,下面给出串行程序的代码
void matrixMultiplication(int a[][SIZE], int b[][SIZE])
{
int i,j,k;
for(i = 0; i < c_row; i++)
{
for(j = 0; j < c_col; j++)
{
for(k = 0; k < a_col; k++)
{
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
在上面的程序中,程序编译运行之后以一个进程(注意区分进程和线程这两个概念)的方式是按照for循环迭代顺序执行。那怎么并行矩阵相乘的代码呢?这里需要使用高级语言级别的并行库,常见的并行库有opemp,pthread,MPI,CUDA等,这些并行库一般都支持C/C++,程序员可以直接调用并行库的函数而不需要实现底层的CPU多核调用。下面给出opemmp版本的矩阵相乘程序。
void matrixMultiplication(int a[][SIZE], int b[][SIZE])
{
int i,j,k;
#pragma omp parallel shared(a,b,c) private(i,j,k)
{
#pragma omp for schedule(dynamic)
for(i = 0; i < c_row; i++)
{
for(j = 0; j < c_col; j++)
{
for(k = 0; k < a_col; k++)
{
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
}
opemmp在没有改动原本代码的基础上实现了矩阵相乘的并行化,实现的办法仅仅是添加了两条openmp编译制导语句,在程序运行到并行代码时,程序的主线程会启动多线程把任务分成n份(n=CPU核心数),然后在多核心上同时计算,最后主线程得到结果。当然除了多线程,程序也可以启动多进程进行并行计算,关于多进程,Linux下的fork()想必很多人都有了解,而mpich是目前很流行的多进程消息传递库。并行化看起来很简单不是么,但是,要设计高效能解决复杂问题的并行程序可不那么容易。
上面提到了多核,这里聊聊多核吧。
多核
多核,就是多核处理器,我们知道,目前的计算机的CPU一般是双核的,有的甚至更多,下图是我的电脑的处理器

我的电脑是8个核心的,其实并行计算就是利用CPU的多核处理器的特点,把之前在单核心上串行的代码并行化,从而缩短得到计算结果的时间。比如上文中提及的矩阵相乘的并行程序,就是把计算任务平分到每个处理器,然后把结果返回,这样相比串行执行时间上要高效。那怎么判断并行程序的效率呢?那就是加速比了,下文会介绍加速比。
关于多核,需要介绍摩尔定律(Moore’s Law)
摩尔定律由英特尔联合创始人之一的Gordon Moore于1965提出,摩尔定律的内容为:
The number of transistors per square inch on integrated circuits had doubled
every year since the integrated circuit was invented.
其中文意思为
当价格不变时,集成电路上每平方英寸可容纳的晶体管的数目,约每隔一年便会增加一倍,性能也将提升一倍。
这意味着没有摩尔定律,就没有如今廉价的处理器。而随着集成电路上的晶体管数据量越来越多,功耗的增加以及过热问题,使得在集成电路上增加更多的晶体管变得更加困难,摩尔定律所预言的指数增长必定放缓。因此,摩尔定律失效。
当前和未来五年,微处理器技术朝着多核方向发展,充分利用摩尔定律带来的芯片面积,放置多个微处理器内核,以及采用更加先进的技术降低功耗。
当然,多核并行计算不仅仅可以使用CPU,而且还可以使用GPU(图形处理器),一个GPU有多大上千个核心,可以同时运行上千个线程。那怎么利用GPU做并行计算呢?可以使用英伟达的CUDA库,不过前提是计算机安装了英伟达的显卡。
并行计算的分类
虽然并行计算可分为时间上的并行和空间上的并行, 时间上的并行是指流水线技术,而空间上的并行则是指多核心并发的执行计算。但是目前并行计算主要研究空间上的并行问题。
按照Flynn分类(1966年)的标准,根据指令流和数据流的多倍性(机器瓶颈部件所能支持最多指令条数或数据个数)可以分成以下几类
- 单指令流单数据流机SISD,即传统的单处理机
- 单指令流多数据流机SIMD
- 多指令流单数据流机MISD
- 多指令流多数据流机MIMD
下图是并行计算四种分类的计算机体系结构
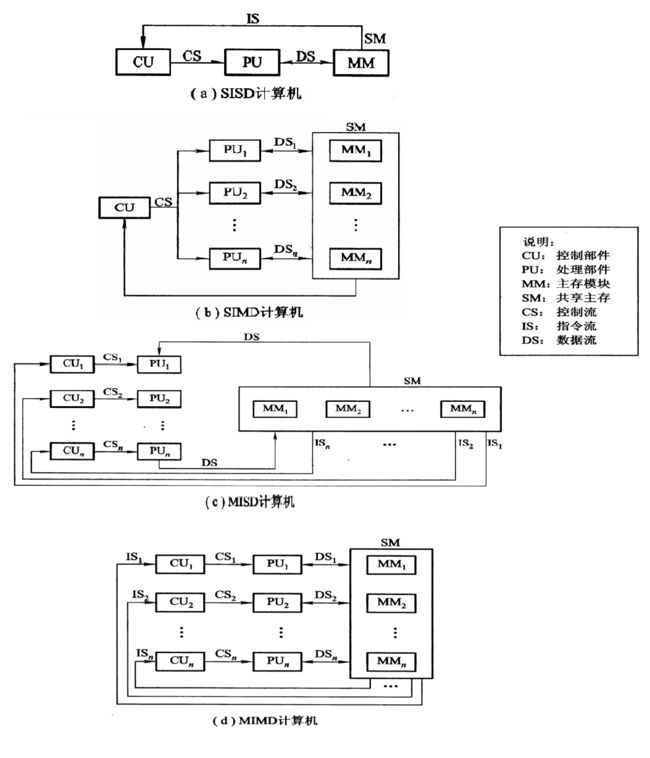
既然有了并行计算,那少不了并行计算机,大家比较熟悉的并行计算机应该是天河一号,天河二号以及最近大家熟知的神威·太湖之光超级计算机。超级计算机涉及CPU,内存,存储,缓存,通信,I/O,网络,制冷等多个领域的知识,由于本文主要介绍并行计算,因此超级计算机的内容不在本文中详述。
并行程序的评价指标
评价并行计算程序效率,不单单从并行程序的执行时间来考虑,而是从与串行程序的对比来去评价。最常用的指标是加速比(speedup)
加速比=串行执行时间/并行执行时间
还有效率
效率=加速比/处理器个数
以及成本
成本=并行执行时间×所用处理器的数目
举个例子:用N个处理器计算N个数的和(N为2的整数次幂)
- 串行计算需要
O(N)的时间 - 并行方法:每个处理器获得一个数,两个处理器之一将其叠加,递归上述步骤。需要
O(logN)的时间 - 加速比
S = O(N/logN) - 成本
C = O(N*logN)
并行计算模型
并行计算模型是并行算法设计与分析的模型,不涉及并行算法实现的程序设计模型和并行算法执行的程序执行模型,如PRAM模型(SIMD模型)。
并行程序设计模型侧重于并行算法如何使用某种程序设计语言正确地编程实现,如MPI,OpenMP,pthread。
并行程序执行模型侧重于并行算法如何在具体的并行机上运行并优化性能,如指令级并行程序执行模型ILPPEM
并行计算模型是算法设计者与体系结构之间的桥梁,并行计算模型屏蔽不同并行机的具体差异,只抽取若干能反映计算特性模型参数,按照模型所定义的计算行为构造成本函数,以此分析时空复杂度。机器参数(如CPU性能参数、存储器参数、通信网络参数)、计算行为(同步或异步)和成本函数(机器参数构成自变量)构成并行计算模型的三要素
写着写着,好像越写越底层了,下面说说并行计算与大数据吧。
并行计算与大数据
大数据不仅给我们带来了大量的数据,而且还带来了计算和查询的麻烦。在数据挖掘领域,对大数据集进行logistic回归,如果不使用并行计算,可能需要好几个月,如果使用分布式的计算平台,计算结果可能只需要几个小时。而在深度学习,人工智能,科学计算领域同样也需要使用并行计算,并行计算缩短了得到结果的时间。
在大数据环境下的并行计算,Hadoop MapReduce和Spark大家一定不会陌生,Hadoop MapReduce把任务分成Map和Reduce两个部分,把大型任务切分成子任务,而Spark提供一种新的存储方式——resilient distributed datasets (RDDs),弹性分布式数据集。RDD是一个容错的、并行的数据结构。RDD只读,可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。所谓弹性,是指在内存不够时可以与磁盘进行交互。这涉及到RDD的另一个特性:内存计算,就是将数据集存到内存中。
同时为了解决内存容量限制的问题,Spark为我们提供了最大的自由度,将所有数据均可以由用户进行cache的设置。RDD还提供了一组丰富的操作来操作这些数据,如map、flatMap、filter、reduce、reduceBy、groupBy等。
下面以一个统计网页中词频的方式来介绍Hadoop MapReduce和Spark,数据存储在MongoDB中,下面是数据的样例。
{ "doc" : "good good day", "url" : "url_1" }
{ "doc" : "hello world good world", "url" : "url_2" }
Hadoop MapReduce
下面给出Map和Reduce的代码
- Map
public void map(Object key, BSONObject value, Context context)
throws IOException, InterruptedException {
ArrayList tags = (ArrayList) value.get("tag");
for (int i = 0; i < tags.size(); i++) {
tagSet.add(tags.get(i));
}
String url = value.get("url").toString();
String doc = value.get("summary").toString().replaceAll("\\p{Punct}|\\d", "")
.replaceAll("\r\n", " ").replace("\r", " ").replace("\n", " ").toLowerCase();
StringTokenizer itr = new StringTokenizer(doc);
HashMap word_count = new HashMap();
while (itr.hasMoreTokens()) {
String kk = itr.nextToken();
if (tagSet.contains(kk)) {
if (word_count.containsKey(kk)) {
word_count.put(kk, word_count.get(kk)+1);
} else {
word_count.put(kk, 1);
}
}
}
// get word and counts (url, counts)
for (Map.Entry entry : word_count.entrySet()) {
BasicBSONObject counts = new BasicBSONObject();
counts.put(url, entry.getValue());
Text myword = new Text(entry.getKey());
context.write(myword, new BSONWritable(counts));
}
}
- Reduce
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
HashMap mymap = new HashMap();
BasicBSONObject result = new BasicBSONObject();
for (BSONWritable val : values) {
@SuppressWarnings("unchecked")
HashMap temp = (HashMap) val.getDoc().toMap();
for (Map.Entry entry : temp.entrySet()) {
mymap.put(entry.getKey(), entry.getValue());
}
}
result.putAll(mymap);
try {
context.write(new Text(key.toString()), new BSONWritable(result));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
System.out.println(" \n\n ERROR HERE BulkWriteException \n\n");
}
}
写Hadoop MapReduce程序必须重新写map和reduce类,在程序员自定义的map和reduce类添加计算逻辑。但是Spark却没有这种限制。
Spark
Spark代码主要是对RDD进行操作,下面给出代码
# 定义统计单词和词频的函数
def f(record):
""""""
table = string.maketrans("", "")
raw_summary = record[1]['summary']
temp = raw_summary.encode("utf-8").translate(table, string.punctuation)
temp_str = re.sub("[+——!,。?、~@#¥%……&*()]+".decode("utf8"),
"".decode("utf8"), temp).replace("\r\n", " ").replace("\n", " ")
summary = re.sub(r'([\d]+)', ' ', temp_str).lower()
url = record[1]['url']
_temp = dict(collections.Counter(summary.split()))
result = [(key,{url:value}) for key,value in _temp.items()]
return result
# reduce操作函数
def reduce_values(record):
""""""
result = {}
for element in record[1]:
key, value = element.items()[0]
result[key] = result.get(key, 0) + value
return [(record[0], result)]
# 从MongoDB中读取数据
rdd = sc.mongoPairRDD(
"mongodb://localhost/testmr.test_in")
newrdd = rdd.flatMap(f) # map
sortrdd = newrdd.sortByKey() # sort
resultrdd = sortrdd.groupByKey()
.flatMap(reduce_values) # reduce
resultrdd.saveToMongoDB('
mongodb://localhost:27017/testmr.test_out')
在Spark中,虽然有map和reduce这两个RDD的操作接口,但却不是和Hadoop的MapReduce一一对应。在Spark中,可以通过两个RDD的flatMap操作来实现Hadoop MapReduce。
Spark的速度比Hadoop更快。最后Hadoop Reduce和Spark的结果(以下是样例的结果)为
> db.stackout.find().limit(4)
{ "_id" : "world", "data" : [ { "url_2" : 2 }, { "url_3" : 1 }, { "url_4" : 1 } ] }
{ "_id" : "good", "data" : [ { "url_1" : 2 }, { "url_2" : 1 }, { "url_3" : 2 } ] }
{ "_id" : "day", "data" : [ { "url_1" : 1 } ] }
{ "_id" : "hello", "data" : [ { "url_2" : 1 }, { "url_3" : 2 }, { "url_4" : 2 } ] }
延伸阅读和推荐书籍
要进一步了解并行计算及并行程序的开发,大家除了需要具备基本的编程能力之外,还需要了解计算机体系结构及操作系统,特别是CPU,cache,内存,多进程,多线程,堆,栈等概念。就比如cache优化的问题吧,如果在实现矩阵相乘并行化程序时考虑cache优化的问题,那么运行的时间又会缩短,加速比又会提高。另外还需要使用一些常用的并行计算的库,不过这些库几乎都比较容易上手使用。不过我觉得在开发并行程序时最重要的是并行算法的设计——把串行问题并行化,虽然矩阵相乘的问题很容易并行化,但是现实世界中的很多计算问题都很复杂,如何将串行问题并行化这也考验着一个开发者的算法基础和数学能力。
下面给出课堂上老师推荐的书,我目前在看《Hadoop 权威指南》。其实还有一本叫做《深入理解计算机系统》的书没有列出,推荐给有经验的程序员阅读。





总结
并行计算其实是一个很大的概念,今天只是蜻蜓点水,接下来还要好好写文章总结并行计算领域的技术知识。