摘要: 本文作者,结合在阿里云自主研发云数据库产品创新之路上的思考、对云计算时代IT产业格局转变的理解,以及对于未来开放式竞合(Co-opetition)发展的展望等多个维度来阐述和分享云服务的创新、进化、竞合和开放的思维和实践。
前言
数据库作为信息时代平台科技(CPU/芯片、PC/手机操作系统、数据库)最复杂最核心的技术之一,在数字化经济时代,成为了和“水电煤”一样不能缺少的数字化能源,是现代化社会经济运作的源动力。当今这些最核心的IT科技,还完全掌握在美国的高科技公司(如Intel、高盛、微软、苹果、谷歌、Oracle、IBM等)手中。
跻身于全球最顶级的高科技公司行列,中国互联网公司在应用创新层面的巨大成功,能否进化成核心科技自主研发的创新能力,是众多业界精英们相互“确认过眼神”后的普遍疑问。传统IT厂商数十年沉淀的技术壁垒能否被破局?云厂商近十年的技术积累和创新能否足以肩负核心科技自主研发的重任?云计算的商业模式和互联网的创新基因能否碰撞孕育出“换道超车”的时代机遇? 互联网在“兵不血刃”的商业竞争中能否找到一条融合创新之路?
带着这些问题,本文作者,尝试用不一样的个人视角,结合在阿里云自主研发云数据库产品创新之路上的思考、对云计算时代IT产业格局转变的理解,以及对于未来开放式竞合(Co-opetition)发展的展望等多个维度来思考。由于个人能力有限,认知偏颇之处难以避免。“嘤其鸣矣 求其友声”,更多的是希望能激发大家的共鸣,共同探讨和开拓未来之路。
1. 时代背景和使命
当下,我们享受着互联网时代的活色生香,商业模式“乱花渐入迷人眼”,新奇、有趣、刺激的流量变现无所不在,“眼球经济”迷倒众生一片,网罗了无数男女老少。人性和消费欲望在自由竞争的互联网新经济中不断被激发和放大,互联网应用在资本的推波助澜下繁花似锦,科技造富的神话亦不绝于耳。此起彼伏的互联网公司已经不是在满足需求,而是在创造需求。狄更斯的那句名言“这是一个最好的时代,也是一个最坏的时代”同样适用于描述今天的互联网。因为从来没有一个时代,把科技和经济联系得像今天这样紧密,也从来没有一个时代,像今天这样用追逐商业成功的梦想来催生和促进科技应用的创新和进步。对于快速奔跑的互联网人,其实内心需要更多的“慢下来”的思考,我们是想成为红极一时的互联网现象,还是成为经久不衰的时代经典?
我们知道,互联网繁华的背后,是IT科技在支撑着(CPU,操作系统、数据库、算法、开源软件、工程管理、网络连接等)。放到今天来讲,云计算作为IT技术在互联网时代的演进形态,肩负着互联网服务大众、创新变革的使命。无论是大数据热潮,人工智能的方兴未艾,还是智慧星球的宏伟梦想,无不是构建在云计算、IT基础设施和科技平台之上的。
然而,互联网的喜新厌旧总会让繁华散场,能够沉淀下来的才是经典。作为核心科技之一的数据库,在IT技术发展浪潮中历久弥新,在数字化经济时代,更加焕发光彩,现代社会的商业和经济活动都离不开数据库。数据库在银行、证券、保险、互联网、电子商务、电子政务、移动支付、商品流通和售卖、共享经济、教育、泛娱乐服务等各行各业中发挥巨大作用,影响着商业活动和社会服务的健康高效运行,是城市运营、公司经营、商品交易和商业化服务的内在支撑。
所以云计算厂商,在互联网时代,都加大了对于数据库技术的研发投入,也找到了一条自主研发的新路——云原生数据库。云原生数据库,融合了云计算的服务能力和弹性架构、开源数据库的简洁易用和开放生态,以及传统数据库的SQL管理和处理性能等各方面的优势,通过融合创新,换道超车,在云环境下能够为用户提供更好的数据库服务。亚马逊作为云计算行业的先行者,在自研数据库方面已经进行了多年的投入和努力。亚马逊在2014年11月召开的AWS re:Invent 年度大会上,发布了云原生数据库Aurora,三年后在2017年SIGMOD数据库大会, 亚马逊发布了论文”Amazon Aurora: Design Considerations for High Throughput Cloud Native Relational Databases”,更加开放的解释了云原生(Cloud-Native)数据库Aurora的设计架构和实现方式。
而阿里云紧跟其后,经过三年的研发,于2017年9月发布了自主研发的云原生数据库POLARDB,经过半年多时间的公测,2018年4月正式商用,并且在ICDE数据库大会进行了阿里云自主研发云原生数据库的技术专题分享。
POLARDB商用以来,获得了业界人士的广泛关注,也收获了一大批用户的拥趸,让我们看到了自研数据库带来的商业价值和美好前景。在我们回顾过去、分析现在、展望将来的时候,为了更好的理解自主研发云数据库的选择之路,让我们先来看一看IT行业在云计算时代的产业格局。
2. 云计算时代的产业格局
2007年,云计算“Cloud Computing”这个新鲜词刚刚诞生,没有人会想到10多年后,云计算给整个IT行业会带来了如此深刻的产业变革。从10年前IT业界对云计算的犹疑、观望,到如今云计算已经服务于各行各业并逐渐赢得用户的信任。互联网和大数据,可以说对于云计算的变革起到了至关重要的作用。

在云计算服务出现之前,IT行业主要是两极生态,一类是传统IT科技公司,一类是ISV应用和系统服务厂商,在互联网和云计算成为主流之后,IT行业主要呈现出四极生态水乳交融的态势。如上图所示。由于云计算技术的不断融合渗透,四种类型的厂商在经营自己的主营业务的同时,都尝试在其他领域进行竞合创新,厂商之间的边界已经不再那么重要。传统厂商可以提供云服务,云服务厂商也能研发基于云环境的新的科技产品,网络和IT设备商建立全球化的网络,加速和拓展了云服务和云用户之间的连接,而基于云服务的应用服务商,能快速开发出更贴近用户的应用,或者是为企业用户提供的一揽子解决方案。边界一直在打破,传统的竞争被竞合的方式所取代。
原有的IT产业格局发生着巨大的行业变迁,这个变化将影响未来二、三十年的走向。云计算服务商一直在拓展商业服务的边界。亚马逊、阿里云等国内外云厂商一直在拓展基于云计算的商业服务边界,可以看到几乎各行各业都在云计算上开展着自己的商业服务。
其实历史总是惊人的相似,总是重复着各种各样的“变迁“。当20世纪40年代,IBM决定从打孔机、打字机跨界到电子计算机的时候,创始人Thomas·J·Watson也不会想到40年后IBM会成为世界上最大的工业公司。而20世纪80年代,当比尔盖茨还在从事BASIC程序解译器开发推广的时候,谁曾想把购买来的QDOS进行改进后,竟然成为被IBM PC选中的DOS操作系统,进而不断演化出后来的Windows,帮助微软成为软件帝国,市值在2000年左右一度超过6000亿美金。而上世纪60年代末创建于美国硅谷的Intel公司,最初的产品是半导体存储器芯片,1971年,英特尔通过购买专利,生产出世界上第一个通用可编程微处理器,而后在CPU处理器领域逐渐取得霸主地位。时至今日,CPU仍然是云计算时代无可取代的核心技术。1986年,当史蒂夫乔布斯被赶出自己于1976年创建的苹果公司时,他通过购买加州的一家电脑动画工作室跨界成立了“皮克斯动画工作室”在电脑动画领域取得巨大成功。1996年后乔布斯被请回经营陷入困局的苹果公司,并在2000年推出ITunes和iPod向音乐行业融合的科技产品,这个进一步演化出2007年的iPhone智能手机和应用商店,可以说乔布斯开启了互联网的移动时代,是现代IT科技史上最为传奇的人物。
回顾了这么多IT科技翘楚的发展历史,跨界融合无疑是时代演进的主旋律,商业和行业的边界一直在被拓展。对于云计算时代的IT产业格局而言,传统IT厂商一直拓展计算、存储和网络性能的边界。如Intel追寻CPU芯片的摩尔定律,微软追求极致算法的软件性能,谷歌追求信息搜索的性能,高通追求移动计算的性能。ISV应用和系统服务商一直在拓展应用和方案整合的边界。以苹果为代表的的智能手机,特斯拉的智能汽车等,都提供了整合应用创新的极致体验。而网络和IT设施提供和运营服务商一直在拓展网络连接的边界。中国三大电信运营商的通讯服务,华为公司的“网络管道”战略,光环新网、世纪互联、网宿等网络信息服务商等的IDC和内容加速服务,本质都是为了网络的连接无处不在而提供服务。
当四种科技形态在云环境下融合裂变,意味着巨大的思维方式的冲击,也意味着你中有我,我中有你的科技融合。无论是哪一类的科技公司,都将在云计算领域大有作为,如何避免认知的局限和偏见,形成更好的竞合关系。将会引领着资源、科技、服务和应用优势互补相互依存,通过利他而利己形成生态,打破纳什均衡的窘境,创造出更大的价值空间。
3. 什么是云原生数据库
作为云服务厂商,阿里云提供的数据库服务目前主要分为三类,一类是开源数据库(如MySQL,PostgreSQL,Redis,MongoDB,HBase等),一类是商业数据库(SQLServer,PPAS等),还有自主研发的数据库(POLARDB,HybridDB等)。
POLARDB是阿里云自主研发的云原生数据库品牌,它包含关系型数据库(兼容MySQL、PostgreSQL、Oracle等主流数据库)的服务,目前正在商用售卖的是MySQL兼容的版本,其他SQL类型兼容的版本正在开发之中。
云原生数据库是为了更好的服务于云环境下的应用而诞生的,它是一种融合了众多创新技术而跨界的云数据库服务,本质上是云的能力和SQL能力的融合。相比较于传统IT数据库的SQL管理和数据处理能力,云原生数据库还具有以下特征:
SQL in Cloud
在IT时代,传统的计算力(例如用关系型数据库来处理结构化数据等)是服务于系统硬件隔离环境下的多用户使用场景的。而云计算时代是多客户Self-Service租用环境,各种计算负载场景更加复杂,在这种计算负载变迁的环境下,如何解决IT时代的技术产物和云计算时代应用环境的适配矛盾,正是云原生数据库得以融合创新内在推动力。
例如,在公有云环境下,随着用户的增多,以及用户业务和数据的增长,备份、性能、迁移、升级、只读实例、磁盘容量、Binlog延迟等相关问题渐渐显现出来。这背后大部分原因是由于数据本地存储架构导致,亟须通过技术革新以及新的产品架构解决这个问题。
另外云原生数据库能够更好的衔接云上数据ETL以及迁移的工具,形成数据生命周期管理的闭环。
云的本质是弹性,只有实现了计算和存储的Serverless,把云作为一个“Single Image”的操作系统,完全不用关心硬件的单一故障点、性能瓶颈以及可用性,一切交给云来考虑。在这样一个完全透明的云环境下,高性能的运行SQL程序,这是“SQL in Cloud”提供给用户的核心价值。而目前绝大多数云数据库服务,还是“SQL on Cloud”。
产品即方案
云原生数据库的另一个显著特征是,提供满足企业级数据业务服务的解决方案能力,并把这种方案沉淀成产品能力。提供7*24小时的高可用服务,提供读写分离的自适应负载均衡能力,提供故障自动恢复的业务连续保障能力,提供数据存储容量自适应增长的能力,提供计算资源的即时在线扩展能力,还可以跨IDC以及区域实现数据的容灾能力,这些都是传统私有IT机房运行数据库需要通过构建方案才能组建的能力。而云原生数据库从诞生起,就具备企业级数据解决方案的能力。
全托管服务
云计算的全托管服务是指云服务厂商提供了IDC机房建设、资源供应链和部署、监控运维、以及售后服务支持等服务体系,相比于传统的IT数据库购买流程,更加简单快捷,即买即用,又极大的降低了购置成本和后期的维护成本,并且让用户把注意力关注于数据的定义、收集、处理和业务表达上。剩下的资源、性能、维护等等全部由云厂商完成。
普惠科技
云原生数据库的用户,共享的不一定是局限于物理服务器的计算资源,更多共享的是超高速的网络环境,以及具有先进绿色计算环境的IDC机房,还有足够可靠的安全防御体系和设施。在极大的降低了高科技产品的准入成本后,风险与故障成本也被共享分担,云服务商提供SLA协议来保障服务的质量,并对超出承诺的服务故障提供补偿。
从100到200
很多创新的产品都会经历一个从0到1的过程,就如同Peter Thiel在《从0到1》那本经典著作中描述的那样,一些新事物,新的表达方式,和产品新的形态,将经历一个从无到有,破茧成蝶的过程。这个从0到1的过程用来描述云计算早期的形态是非常合适的。然而,云计算服务已经经历近10多年的发展,云服务已经日臻完善,完善的这个过程可以看成从1到100的进程体现。那么云原生数据库的诞生是什么样的一个过程呢?它和之前的云数据库有什么本质区别呢?首先,云原生数据库可以看成是云数据库服务的内在进化,基于云数据库服务多年在技术、产品服务和运维能力的经验积累之上,追求安全、可靠、性能、容量、弹性等全方面的进步。这个进化的过程其实就是从100到200的过程。如果说云数据库是SQL能力(数据库技术)和云能力(Cloud is Computer)的叠加,那么云原生数据库就是SQL能力和云能力的融合。云原生数据库没有直接表现为一个从0到1不同的产品形态,但是内在要求驱动云原生数据库服务在能力、质量、效率各个维度做到超越,而这种超越是基于之前云数据库服务的能力基础上的。
4. POLARDB的融合创新
作为云原生数据库,POLARDB集众多创新技术于一身,并充分利用了最新的IT硬件发展技术,无论是高速网络还是存储设备。采用了自主研发分布式存储引擎设计,计算服务器和存储数据分离的架构,MySQL版本提供100%兼容,性能更快,弹性能力更佳,自带只读节点,数据自适应扩展,存储三副本,秒级备份,提供更高的可靠性。
接下来将着重分析POLARDB的产品架构和技术创新点。关于POLARDB详细的产品功能介绍,请参考官方文档。
POLARDB产品架构
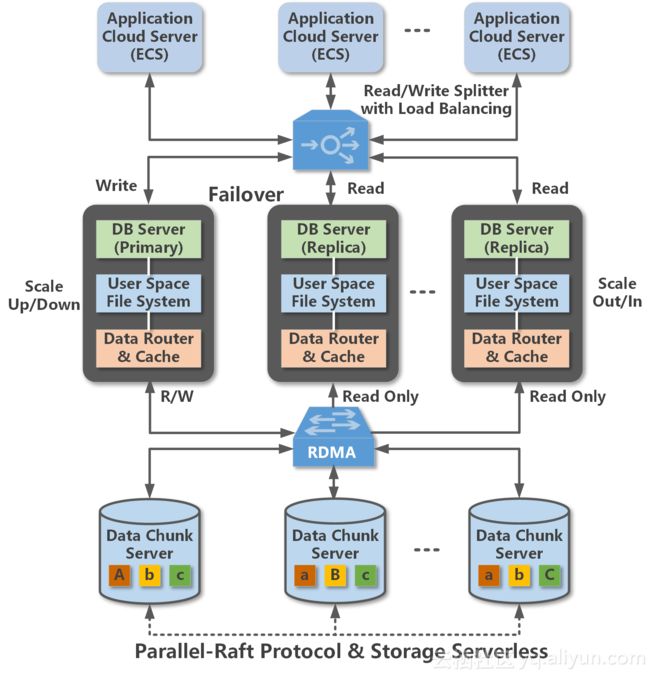
如图所示,POLARDB产品是一个分布式集群架构的设计。它集众多高级的技术实现于一身,使得数据库OLTP处理性能有了质的飞跃。POLARDB采用了存储与计算分离的设计理念,数据库计算节点和存储节点之间采用高速网络互联,并通过RDMA协议进行数据传输,使得I/O性能不在成为瓶颈。
数据库节点采用和MySQL完全兼容的设计。主节点和只读节点之间采用Active-Active的Failover方式,提供DB的高可用服务。DB的数据文件、redo log等通过User-Space用户态文件系统,经过块设备数据管理路由,依靠高速网络和RDMA协议传输到远端的Chunk Server。同时DB Server之间仅需同步redo log相关的元数据信息。Chunk Server的数据采用多副本确保数据的可靠性,并通过Parallel-Raft协议保证数据的一致性。
多个ECS云服务器可以通过读写分离连接地址,通过自适应负载均衡能力,把请求转发到POLARDB的各个服务节点。
在描述了POLARDB的产品架构之后,我们再分别从分布式架构,数据库高可用,网络协议,存储块设备,文件系统和虚拟化等方面逐一介绍下POLARDB融合使用的如下技术创新点。
分布式共享存储
POLARDB采用自主研发的分布式存储系统,其根本原因是上述的计算与存储分离的需要。逻辑上DB数据都放在所有DB server都能够共享访问的数据chunk存储服务器上。而在存储服务内部,实际上数据被切块成chunk来达到通过多个服务器并发访问I/O的目的。
物理复制
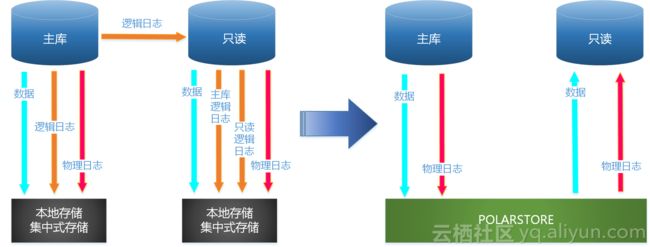
如上图所示,POLARDB通过将数据库文件以及Redolog等存放在共享存储设备上,由于数据共享,只读节点的增加无需再进行数据的完全复制,共用一份全量数据和Redo log,只需要同步元数据信息,这使得系统在主节点发生故障进行Failover时候,切换到只读节点的故障恢复时间能缩短到30秒以内。系统的高可用能力进一步得到增强。而且,只读节点和主节点之间的数据延迟也可以降低到毫秒级别。
双25Gbps高速网络下的RDMA协议
RDMA通常是需要有支持高速网络连接的网络设备(如交换机,NIC等),通过特定的编程接口,来和NIC Driver进行通讯,然后通常以Zero-Copy的技术以达到数据在NIC和远端应用内存之间高效率低延迟传递,而不用通过中断CPU的方式来进行数据从内核态到应用态的拷贝,极大的降低了性能的抖动,提高了整体系统的处理能力。
Snapshot物理备份
Snapshot是一种流行的基于存储块设备的备份方案。其本质是采用Copy-On-Write的机制,通过记录块设备的元数据变化,对于发生写操作的块设备进行写时复制,将写操作内容改动到新复制出的块设备上,来实现恢复到快照时间点的数据的目的。Snapshot是一个典型的基于时间以及写负载模型的后置处理机制。也就是说创建Snapshot时,并没有备份数据,而是把备份数据的负载均分到创建Snapshot之后的实际数据写发生的时间窗口,以此实现备份、恢复的快速响应。POLARDB提供基于Snapshot以及Redo log的机制,在按时间点恢复用户数据的功能上,比传统的全量数据结合Binlog增量数据的恢复方式更加高效。
Parallel-Raft算法
Parallel-Raft是在Raft协议的基础上,针对POLARDB chunk Server的I/O模型,进行改良的一致性算法。Raft协议基于Log是连续的,log#n没有提交的话,后面的Log不允许提交。而POLARDB实现的Parallel-Raft针对非关联数据chunk允许并行的提交,在保证了多副本数据一致性的基础上,进一步提高了并发性能。
Docker容器虚拟化
容器虚拟化的实现相对于KVM等虚拟化技术而言,更加轻量级。如果用户不需要感知整个操作系统的功能,那么用容器虚拟化技术理论上应该能够获得更好的计算能效比。POLARDB采用Docker环境来运行DB计算节点,用更轻量的虚拟化方式,解决了资源的隔离和性能的隔离,也节省了系统资源。
User-Space文件系统
POLARDB采用User-Space文件系统设计数据库服务器专用的API接口,由于不用完全兼容POSIX标准,也无需在操作系统内核进行系统调用的1:1mapping对接,直接在用户态实现文件系统的元数据管理和数据读写访问支持,实现难度大大降低,并且更加有利于数据库服务器和分布式存储系统之间的高速数据传送。
5. 自主研发之路
技术的创新,是需要持续的研发投入,云原生数据库还需要不断解决云用户对于大容量数据处理速度的极致追求,对于云厂商而言,需要跨界,深入研究并借鉴传统数据库厂商在SQL编译、优化器、并行执行计划等方面的技术优势。这是一个充满极度挑战的过程。
云服务是自研数据库最好的催化剂
自主研发创新的背后,是长期苦练内功,厚积薄发的体现,不仅需要长期的研发投入,还需要快速找到商业变现的途径,找到一条能够自给自足的商业模式,并且持续投入到研发之中。幸运的是,云计算的商业模式,以及阿里云目前的数据库服务有能力支撑这种开拓进取的研发成本。已经商用的POLARDB也开始赢得越来越多的用户的青睐,云服务业务的自我造血能力,将支撑自主研发的更多投入,达到良性的闭环反馈。这是自主研发数据库需要解决的首要问题。
自主研发的云原生数据库,利用云计算的商业模式,反哺资源的长期投入,利用后发优势,在数据时代,不断赢得用户的信任。而这些在POLARDB上构建的用户业务需求反馈,也为POLARDB的自身演进提供了方向。我们非常欣慰的看到,在新金融,新教育,新媒体,泛娱乐等互联网+行业应用当中,已经有越来越多的用户正在使用POLARDB创建他们在数字化经济时代的价值传递。而这,正是自主研发数据库存在的根本意义。
自研数据库生于创新
回顾数据库发展史,在这个知识日新月异的TMT时代,听起来有些“古董”,这个起源于半个世纪以前的IT技术,事实上一直处于现代社会科技的核心,支撑着当今世界绝大多数的商业科技文明。CPU、操作系统、数据库这三大核心领域,基本上就是IT时代的缩影,同时也是一切信息化处理、计算力和智能化的基石。从1970年E.F.Codd发表了一篇里程碑论文“A Relational Model of Data for Large Shared Data Banks”,到80年代初期支持SQL的商用关系型数据库DB2,Oracle的面市,以及90年代初SQL-Server的诞生,都是商业数据库成功的代表,而其中Oracle占有绝对的市场地位。
自研云数据库如何应对商业数据库多达上千万行量级的数据库工程实现和复杂度,还有数千人的研发投入,所以云厂商在SQL核心层面的积累还不足以与商业数据库匹敌,唯有创新,尤其是基于云计算环境用户使用模式的融合创新,才是和传统商业数据库差异化共生的有效途径。从长远来讲,用今天来支撑明天。今天的融合创新,本质上是为了明天或者后天的颠覆式创新。不积硅步无以至千里。
自研数据库的挑战
自研数据库在云环境下的融合创新的确能够在云用户的需求引导下进行自我进化和成长,但是对于to B的用户业务来讲,和互联网to C的用户场景有很大的不同。To B的企业级用户在进行选型和判断的时候,更加理性,通常是公司内部多个相关角色集体参与和决策的过程,越是大的B类客户,这个决策的链条更长,参与的角色更多,对于不同规模的公司,具体使用产品的用户身份(Persona)而言也各有不同,有DBA,架构师,研发工程师,甚至是技术总监以及CTO等都会参与到重大的产品和技术选型当中。也就是说,自研数据库本身在根据某些场景的问题提供解决能力的同时,背后还有一个很大的诉求就是,在产品的通用能力(安全、可靠、易管理、多功能、精细度)方面要体现整体能力的成熟度。也就是说一个自研数据库从诞生的那一天开始,需要有一个非常高的标准达到同类产品的成熟度,立足这个成熟度的基础之上,通过提供解决某些场景问题的特定能力,并以此获得客户进行选择的价值认同感和优越感。
结语
在描述了云计算产业的融合创新和边界拓展之后,我们分享了POLARDB的融合创新以及云原生数据库的关键特征。通过实现这些技术创新点并形成完整的产品服务体系之后,在自主研发的道路上我们快速成长。
我们深刻的领会到,连接现实和浪漫情怀以及远大理想的,从来不是诗和远方的田野,而是雪山、草地、沙漠和荆棘。选择自主研发之路,并不是一蹴而就的事情,这是一条“比难更难”的漫长之旅。我们知道,最难的路,才是自我升华最快的路。
“信仰是去相信我们所从未看见的,而这种信仰的回报,是看见我们相信的。”但丁700多年前的这句名言,和今天“因为相信而看见”描述的是同样的价值追求。如果一个企业要活102年,那么这种价值追求将会书写它的传奇,这就是我理解的卓越公司和优秀公司的区别之一。
本文作者:仝一
阅读原文
本文为云栖社区原创内容,未经允许不得转载。