为什么要使用正则表达式
在软件开发过程中,经常涉及到大量的关键字等各种字符串的操作,使用正则表达式能很大简化开发的复杂度和开发效率,所以在Python中正则表达式在字符串的查询匹配操作中占据很重要的地位。
Python中的re模块
Python 为了方便使用正则,提供了re模块
import re # 引入re模块
dir(re) # 查看方法属性
-
re中的方法
match方法
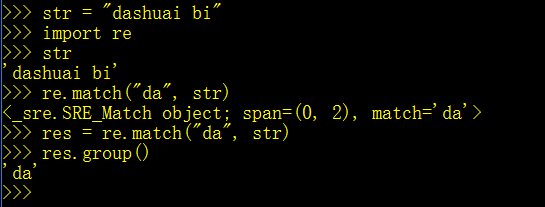 aste_Image.png
aste_Image.png
re.match(p, str) # p 匹配格式
- 常见的元字符
* 匹配所有

Paste_Image.png
. 匹配任意一个字符(\n除外)

Paste_Image.png
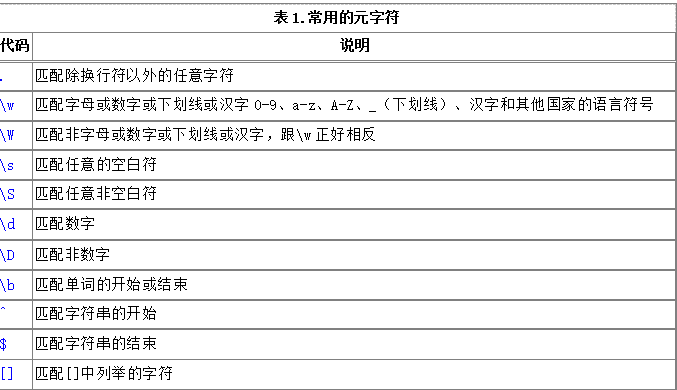
元字符
.匹配除换行符以外的所有字符
\S匹配任意非空字符
\d匹配数字
\D匹配非数字
\b匹配单词的开始或结束
^匹配字符串的开始
$匹配字符串的结束
[]匹配[]中列举的字符
\w匹配字母或数字下划线或汉字0-9,a-z,A-Z, _(下划线),汉字和其他国家的语言符号
\W匹配非字母或数字或下划线或汉字,跟\w正好相反
\s匹配任意的空白符
Paste_Image.png
字符转义
- 如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没法指定它们,因为它们会被解释成其它的意思。这时你就必须使用\来取消这些字符的特殊意义。因此,你应该使用.和*。当然,要查找\本身,你也得用\\.
重复

Paste_Image.png
反义
- 有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:

Paste_Image.png
分组
- 我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作。
re.match("\d+(183|192|168)\s","452183 ")
re.match("\d+(183|192|168)\s","452183 ").group()
re.match("\d+(183|192|168)\s","452183 ").group(1) #注意当输入1的结果
re.match("\d+(183|192|168)\.(li|wang|liu)","452168.wang").group(2)
re.match("(.*)-(\d+)","0931-5912872 ").group(2) #小括号的使用场景,特别方便
re.match("<[a-zA-Z]*>\w*","liujianhong") #看似正确,其实Error
re.match("<[a-zA-Z]*>\w*","liujianhong