Spark RDD五大属性
- 1) A list of partitions :有很多分区(Partitions),数据集的基本组成单位。
- 对于RDD来说,每个分区都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。(比如:读取HDFS上数据文件产生的RDD分区数跟block的个数相等)
- 2)A function for computing each split :一个计算每个分区的函数。
- Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的。
- 3)A list of dependencies on other RDDs:一个RDD会依赖于其他多个RDD,RDD之间的依赖关系。
- RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- 4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):一个Partitioner,即RDD的分区函数(可选项)。
- 当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一 个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner(必须产生shuffle),非key-value的RDD的Parititioner的值是None。Partitioner函数决定了parent RDD Shuffle输出时的分区数量。
- 5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):一个列表,存储每个Partition的优先位置(可选项)。
- 对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置(spark进行任务分配的时候尽可能选择那些存有数据的worker节点来进行任务计算)。
RDD弹性表现在哪几方面
1.自动的进行内存和磁盘数据存储的切换
2.基于lineage的高效容错
3.task失败会自动进行特定次数的重试
4.stage如果失败会自动进行特定次数的重试而且重试时只会试算失败的分片。
5.checkpoint和persist,是效率和容错的延伸。
6.数据调度弹性:DAGTASK和资源管理无关
7.数据分片的高度弹性 a.分片很多碎片可以合并成大的,b.partiton比较大就要考虑换成更小的分区;
RDD有几种操作类型
答:
1)transformation:RDD由一种转为另一种RDD;
2)action:算子会触发 SparkContext 提交 Job 作业。Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统;
3)crontroller:crontroller是控制算子,cache,persist,对性能和效率的有很好的支持。
三种类型,不要回答只有2种操作。
RDD的创建有几种方式
- 共有七种方式,不能仅仅回答前三种
1).使用程序中的集合创建RDD
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
- 适用场景: 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程
2).使用本地文件系统创建RDD
val rdd2 = sc.textFile("/words.txt")
- 适用场景: 使用本地文件创建RDD,主要用于的场景为:在本地临时性地处理一些存储了大量数据的文件
3).使用hdfs创建RDD,
- 代码
- // 实现文件字数统计
// textFile()方法中,输入本地文件路径或是HDFS路径
// HDFS:hdfs://spark1:9000/data.txt
// local:/home/hadoop/data.txt
val rdd = sc.textFile(“/home/hadoop/data.txt”)
val wordCount = rdd.map(line => line.length).reduce(_ + _)
- 适用场景: 使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作
4).基于数据库db创建RDD(Oracle 、mysql)
- 创建方式: 1>首先创建数据库连接函数
- 从JDBC数据源中读取数据
- def createDbconnection() =
{
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost/test/?user=root")
}
def extractValues(r:ResultSet)=
{
(r.getInt(1),r.getString(2))
}
val data = new JdbcRDD(sc,createDbconnection,"select * from userlist", lowerBound =1,upperBound =3,numPartition =2,mapRow=extractValues)
println(data.collect.tolist)
- 适用场景: 从数据库读数据,适用于结构化数据的处理
5).基于Nosql创建RDD,如hbase
- 创建方式
- val conf = new SparkConf(true).set("spark.cassandra.connection.host","hostname")
val sc = new SparkConetext(conf)
val data = sc.cassandraTable("userlist","kv")
- 适用场景: 从Nosql数据库中读取数据,适用于那些互联网公司
6).基于s3创建RDD
- 创建方式: 你首先把你的S3访问凭据设置为AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量
- sc.textFile("s3n://***:***@filepath")
- 适用场景: 从S3中读取数据,适用中小型公司,没有足够的存储设备
7).基于数据流,如socket创建RDD
- 创建方式
- // Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
- 适用场景: 适用于实时数据处理
注意:4,5,6三种方式要做getPreferedLocations
RDD中产生Shuffle的算子
1 去重:
def distinct()
def distinct(numPartitions: Int)
2 聚合
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
3 排序
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
4 重分区
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)
5集合或者表操作
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
Spark中的reduce(func)是不是action?
答:reduce是action型算子。reduceByKey(numPartitions:Int)是transformation算子。
RDD的依赖关系
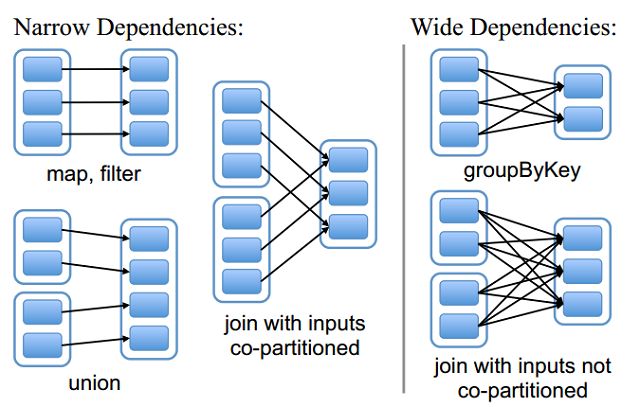
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency / shuffle dependency)。
- 窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女 - 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:宽依赖我们形象的比喻为超生
spark的RDD就是记录数据更新的方式,但为何高效?
- 1)RDD是不可变的而且是lazy的。由于RDD是不可变的,所以每次操作时就要产生新的RDD,新的RDD将父RDD作为第一个参数传入,所以不存在全局修改的问题,控制难度就有极大的下降。计算时每次都是从后往前回溯,不会产生中间结果。在此基础上还有计算链条,出错可以从中间开始恢复。
恢复点要么是checkpoint要么是前一个stage的结果(因为Stage结束时会自动写磁盘) - 2)如果每次对数据进行很小的修都要记录,那代价很大。RDD是粗粒度的操作:原因是为了效率为了简化。粗粒度就是每次操作时作用的都是所有的数据集合。细粒度代价太大。
- 对RDD的具体的数据的改变操作都是粗粒度的。--RDD的写操作是粗粒度的。但RDD的读操作既可以是粗粒度的又可以是细粒度的。
Spark的RDD通过Linage(记录数据更新)的方式为何很高效?
答:
1)lazy(懒加载)记录了数据的来源,RDD是不可变的,且是lazy(懒加载)级别的,且RDD之间构成了链条,lazy(懒加载)是弹性的基石。由于RDD不可变,所以每次操作就产生新的RDD,不存在全局修改的问题,控制难度下降,所有有计算链条将复杂计算链条存储下来,计算的时候从后往前回溯900步是上一个stage的结束,要么就checkpoint;
2)记录原数据,是每次修改都记录的话代价很大。如果修改一个集合,代价就很小,官方说RDD是粗粒度的操作,是为了效率,为了简化,每次都是操作数据集合,写或者修改操作,都是基于集合的RDD的写操作是粗粒度的,RDD的读操作既可以是粗粒度的也可以是细粒度,读可以读其中的一条条的记录;
3)简化复杂度,是高效率的一方面,写的粗粒度限制了使用场景如网络爬虫,现实世界中,大多数写是粗粒度的场景。
Attention Please--文章来自互联网资料整理,如有雷同,纯属李小李抄袭,如有侵权请联系删除 From 李小李