对照的字幕来自http://asciiwwdc.com/2014/sessions/419,部分借助谷歌翻译
创建可响应的ui需要对core animation和gpu怎么工作的理解。
学习关于ios core animation渲染途径。
新的UIVisualEffectView和它如何利用gpu。
发现可以侦测ui性能的工具。
了解如何改善在各种设备上的ui表现问题。
(以上是关于这个session要讲的东西)
....省略前面的介绍语
第一部分我们要讲的是core animation pipeline还有它是如何和应用产生交互的。
接下来我会介绍一些渲染概念,在之前我们需要理解两个新类,UIBlurEffect and UIVibrancyEffect,在之后,mike将会展示一些分析工具和演示一些例子。

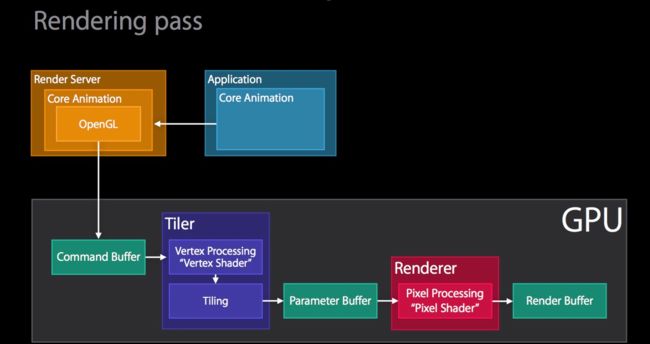
让我们从core animation pipeline开始,他从应用开始,应用建立了一种层次,间接的跟uikit或者直接的跟core animation产生联系。我们需要注意的是应用过程没有对core animation做渲染工作。
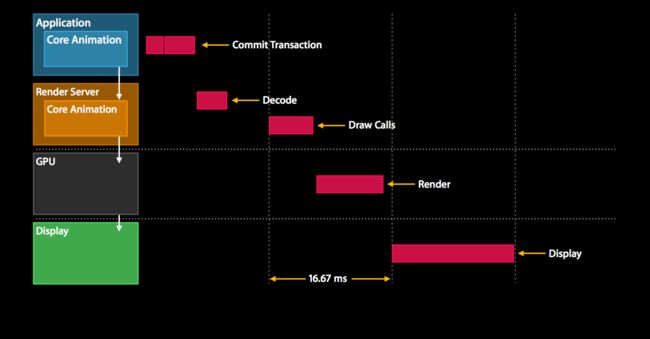
相反的,这个视图层次提交给渲染服务器(单独的一个process),这个渲染服务器有一个专门用于core animaiton的服务器版本来接受这个view hierarchy。
这个视图层次然后渲染core animaition通过open gl和metal,那就是gpu。(指的是图中)。然后,一旦渲染了视图层次结构,我们终于可以将其显示给用户。
因此有趣的这看起来像一个time wise在应用内。因此我将给你介绍下面这个表格(指的是图中的虚线)。
每个垂直直接的间隔指的是16.67ms(指的是渲染时间).
第一件事发生在应用的,你接受到了来自用户的事件,可能是一个touch,因此,我们要更新视图层次。这发生在我们称之为提交事务阶段的阶段。
在这个阶段结束后,视图层次结构被编码发送给渲染服务器。渲染服务器第一件事就是解码这个视图层次,然后,渲染服务器必须等待下一个重新同步才能等待缓冲区从显示器中恢复,实际可以渲染,然后最终开始为GPU,这个OpenGL或金属重新发出绘制调用。一旦这个如期完成,gpu就可以开始渲染工作
(值得注意的是:在 Prepare 这个阶段做的事是图像解码以及图像转换。无论是网上下载的图像还是从磁盘读取图像文件,得到的图像一般是不能直接用于显示的,需要解码为位图(bitmap)。如果你的视图中使用了 JPEGs 或是 PNGs的图像,将在这个阶段进行解码;如果你使用了 GPU 不支持的图像格式(就是 JPEG 和 PNG 之外的格式),那么图像就需要转换格式。Path 团队的图像缓存开源库FastImageCache就利用这个特性来加速图像的显示。)
我们希望这个渲染工作结束能在下一个resync之前,因为这样我们就能交换缓冲然后展示view hierarchy给用户
你可以看到这些操作跨越不同的框架。在这种情况下,它是三个框架,我们现在将继续下一个处理程序事件和提交事务显示后,我们只能渲染20赫兹。加起来就是60hz。所以,我们正在做的就是覆盖这些阶段。
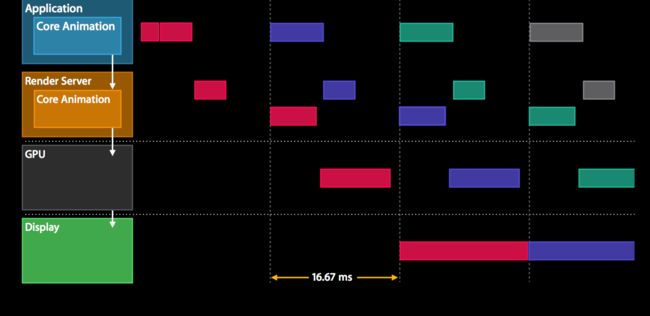
这段的意思就是说,在我们draw的同时,你将看见我们下一个handle event,commit transcation在flowing step diagram快结束的时候
In the next few slides I would like to focuson the commit transaction stagebecause that's what affects application developers the most.
然我们来看下commit transaction,他本是由4个阶段组成,

第一个是布置建立视图,这个阶段layoutSubviews被重写,这是视图创建发生的地方,这是我们通过addsubview向视图层次里面添加视图的地方,还有填充数据和做一些轻量级的数据库查找,之所以说轻便,是因为我们不想在这里停留太久。The lightweights could be, for example, localized stringsbecause we need them at this point in orderto do our label layout.Because of this, this phase is usually CPU bound or I/O bound.
第二各阶段是展示视图,这是一个画内容的过程和调用drawrect,值得注意的是,这个阶段实际是CPU or memory bound,因为渲染是悄无声息的。我们用core graphics,而且是利用cg context来做这个渲染过程,所以关键在于,我们希望通过 用core graphic避免一些性能开销过大的工作来最小化工作。
第三个阶段是准备阶段,这是图像解码和图像转换的地方。这个发生在如果在你的视图层次结构中有一些jpg和png准备解码,图像转换不是那么简单,因为可能有些图片不被gpu所支持,因此我们需要转换这些图片,你想避免这个好的解决方案可能是index bitmap。
在最后阶段的Commit阶段,我们打包层并将它们发送到渲染服务器。这个过程是递归的,你不得不重复执行整个layer tree而且这是expensive(指的这个性能开销)。因为这个layer tree是复杂的。因此这是我们为什么要保持这个layer tree平坦的理由,以确保这个效率高。
让我们来看看这个如何工作的动画
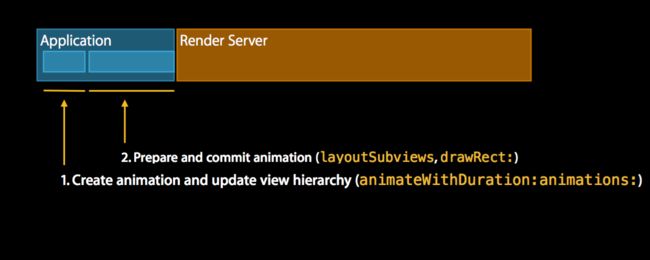
动画自己有三个阶段,其中两个发生在应用程序内,最后一个阶段发生在渲染服务器上。第一个阶段,我们可以创建动画,更新视图层次结构。
This happens usually with the animate restorationanimations method.
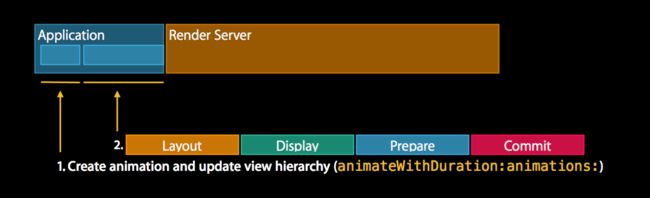
第二个阶段是我们准备和提交动画。这里layoutsubview和drawrect是如此的相似,由于这是这和我们之前看到的四个阶段。唯一的区别我们不仅提交视图层次结构,我们还提交动画。
这是layoutSubview被称为drawRect的地方,这听起来很熟悉。
唯一的区别就是我们不仅仅提交view hierarchy,我们还提交动画。还有一个原因,因为我们想要提交动画给渲染服务器,这样我们就能持续的更新这个动画,而避免了去回头跟application说。这是处于效率的原因。
会有3个方面的内容:第一,基于tile的渲染,是GPU工作的方式,第二,渲染过程的概念,第三是渲染过程中mask的影响。
With tile based rendering,这个屏幕分割成m*n的像素块,tile的尺寸是chosen的以至于我们可以放soc缓存。

(tile指的就是这个手机所占的格子)
您可以看到手机图标跨越多个图块,手机图标本身将呈现为CA图层。ca图层在ca中是两个三角形,这两个三角形将会被分割成多个三角形,多个tile
And so what a GP will do now, 他将会开始分割这些三角形,我们将会提交这些tile每个tile都会被单独的渲染。
(gp是什么?)
(这一节介绍了一些基本的渲染知识:屏幕被分割成 NxN 像素的小块来渲染,每个小块的大小与 SoC(System on Chip) 的cache相关。具体的操作过程如下:对于一个 app icon,被当做一个 CALayer 来渲染,而 CALayer 在 Core Animation 中被划分为两个三角形,每个三角形可以被继续分割成多个三角形,对每一个三角形单独渲染。)
The idea is here that we do this process nowfor the hue geometries so at some point we have the geometryfor each tile collected and then we can make decisionson what pixels are visibleand then decide what pixel shade to run.
So we run each pixel shade only once per pixel.
如果你做一些混合的工作,这仍然会有overdraw的问题。
那么让我们来看看rendering passes的的类型,我们假设应用已经建立了拥有core animation的view hierarchy。他提交给了渲染服务器,然后core animation被解码了,现在它需要用到metal或者open gl来渲染它,在幻灯片中我们说到metal只是简单的渲染它,opengl命令会生成它,然后提交给gpu,GPU将会接收到这个命令缓冲区,然后开始工作。
GPU首先要做的是顶点处理是顶点着色器运行的地方。将所有的顶点转换成屏幕空间,这样我们就可以做第二阶段的平铺的工作。然后我们就可以看到tile了。
这个阶段的输出是写入一个叫做参数缓冲区的东西,下一个阶段不是马上开始的。相反我们会等到所有几何位置都处理好之后或者parameter buffer满了之后,因为满了之后必须flush。这样的话,就会实际上执行它因为接下来需要开始vertex processing并获取pixel shader开始工作。
这个阶段即是pixel shader stage,它其实是称为render stage, 可以在instruments OpenGL ES Analysis ->GPU driver 中有一项统计 render utilization,这个阶段的输出是写入到render buffer中的。
接下来让我们通过masking来看看实际的例子。,假定view层次已经准备好了,command buffer也已经OK。在第一个过程中发生的第一件事情是将layer mask渲染到一个texture中,这个例子中是这个相机icon,第二个过程是将layer content渲染到一个texture中,这个情况下是这个蓝色素材。最后一个过程中调用组合过程将mask应用到content texture中,并最终合成为蓝色相机icon。
UIBlurEffect
对于那些不知道UIBlurEffect的用户,可以使用UIVisualEffect视图,现在这是一个公共API。
ios引入了blur的概念,这里将会展示三种不同的blur,我才用了ios常用的壁纸来实验 extra light, light and dark。

暗黑的是用了最少的渲染过程。您需要记住这个渲染过程我们对某些硬件做了优化。
因此第一步就是渲染这个将被模糊的content。第二部是捕获这个content,然后缩小它,缩小的尺寸取决于硬件,在接下来的两个过程中,我们应用了实际的模糊算法,这是分开的,所以我们首先做出水平模糊,然后是垂直模糊。然后还有一个优化,就是如果像素是11*11的,两步合成一步的结果就是每个像素121个采样,分成两步就是每步采样11个,所以变小了很多。最后一个步骤就是提高这个模糊和色调。
接下来看看这个性能

第一行是tile activity,第二行是render activity,最后一行是vblank interrupt we can actually see what our frame boundaries are.
因为我们运行在60hz的ui上,所以single frame是16.67ms.
我们可以看见first tile过程在first render过程之前,因为tile需要pull this在整个几何上,正如我们刚才看到的。

让我们快速看下这个过程,第一个过程是content过程,这个所花费的时间取决于view hierarchy,在这个例子中他仅仅是一个简单的图像,如果涉及到ui可能花费更长的时间,然后第二个就是缩小和捕获这个内容,这非常快,subpass是水平模糊,它非常快而且cost几乎不变,因为它仅仅用于很小的一片区域,第四个是垂直模糊,处理他也非常的快,第五个是放大并tint。
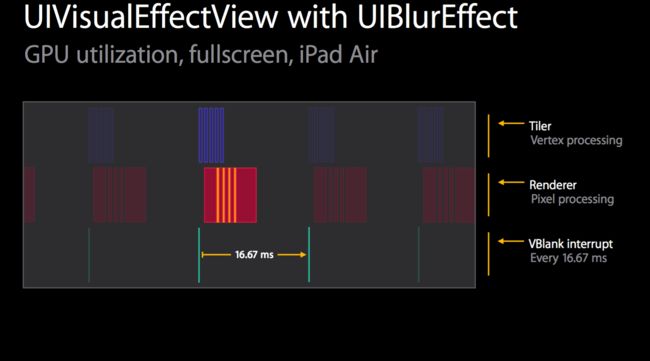
可能你已经注意到了render 过程中的这些gap,它们实际上是GPU idle time,这里是在做GPU的上下文切换。这些gap实际时间也很短,每个大概是0.1到0.2毫秒。
由于在iPad2和3上面blur耗时太大,所以在这两个设备上的blur效果被禁用,而只是应用tint。
UIVibrancyEffect很花费性能,所以你要注意仅仅用于他在很小的一块区域。
光栅栏化

因为更新时会有额外的离屏过程,所以最好只用于静态内容,需要注意的是,如果光栅化的区域过大,如果超过了2.5倍屏幕size的缓存,则可能会不断引发离屏过程,缓存会一遍一遍被更新。所以不要过度使用它。
So if you start setting the rasterize propertyof the last part of your view hierarchy you might blow thecache flow over and over and end up as a lot of offscreen passes.
然后就是如果不用的时间超过了100ms,他就会被从缓存中逐出。所以你要确保你经常使用它们,
group opacity

group opacity能被禁用,因为在calayer上它允许group opacity属性,如果layer不是opaque的,那么group opacity会引入离屏渲染,所以这意味着opacity属性不等于1
And if a layer has nontrivial contentthat means it has child layers or a background image.
And what this means in turn is that sub view hierarchy needs to be composited before its being blended.
所以不用的时候就关闭它。

https://objccn.io/issue-3-1/
http://www.jianshu.com/p/79a7d0afb699
http://www.jianshu.com/p/0bfba3d84cc8