先说下xml的基本结构,一张图了解

Image.png
DOM解析
解析原理:
首先解析文件(会把整个文件加载到内存中--所以不适合解析大文件),将文件分为独立的元素、属性和注释等,然后以节点树的形式在内存中对XML文件进行表示,就可以通过节点树访问文档的内容。
//(1)dom解析
private void domParser(){
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();//创建解析工厂
try {
InputStream mAssets = getAssets().open("test.xml");//得到assets目录下的文件
DocumentBuilder builder = factory.newDocumentBuilder();
//解析文档,并返回一个Document对象,此时xml文档已加载到内存中
Document doc = builder.parse(mAssets);
//获取文档根元素(节点)
Element element=doc.getDocumentElement();
//上面找到了根节点,这里开始获取根节点下的元素集合
NodeList list=element.getElementsByTagName("book");
for (int i = 0; i < list.getLength(); i++) {
//通过item()方法找到集合中的节点,并向下转型为Element对象
Element n = (Element) list.item(i);
//获取元素的属性map,用for循环提取并打印
NamedNodeMap node = n.getAttributes();
for (int x = 0; x < node.getLength(); x++) {
Node nn = node.item(x);
Log.e("-----",nn.getNodeName() + ": " + nn.getNodeValue());
}
//打印元素内容,代码很纠结,差不多是个固定格式 1获取该元素下的子元素集合,2获取子元素,3
// Log.e("title: " ,n.getElementsByTagName("title").item(0).getNodeValue());
//此处求告知为什么要上面的方法得不到值,下面的可以。
Log.e("title: " ,n.getElementsByTagName("title").item(0).getFirstChild().getNodeValue());
Log.e("author: " , n.getElementsByTagName("author").item(0).getFirstChild().getNodeValue());
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
效果图:
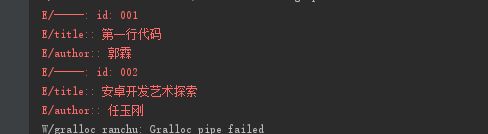
Paste_Image.png
(2)PULL解析:
原理:pull是依靠数字来做判断的xml解析方式,而且只能是从上往下。对于我们只想解析一个xml文档某条数据来说,就显得力不从心了。因为pull很傻,只能一步一步的解析。
private void pullParser() {
try {
InputStream mAssets = getAssets().open("test.xml");//得到assets目录下的文件
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();//
XmlPullParser xmlPullParser = factory.newPullParser();//构建解析对象
xmlPullParser.setInput(mAssets, "utf-8");//开始解析---传流
// xmlPullParser.setInput(new StringReader(str));//传字符串
int eventType = xmlPullParser.getEventType();//当前的解析事件--就是当前解析的节点
//判断是否解析完毕
while (eventType != XmlPullParser.END_DOCUMENT) {
String nodeName = xmlPullParser.getName();//获取节点名称
switch (eventType) {
//开始解析某个节点---
case XmlPullParser.START_TAG: {
/**
* 解释下这里为什么要判断。点进去nextText方法可以看到
* If current event is START_TAG then if next element is TEXT then element content is returned
* or if next event is END_TAG then empty string is returned, otherwise exception is thrown.
* After calling this function successfully parser will be positioned on END_TAG.
* 意思就是说:如果当前事件是starttag那么如果下一个元素是文本那么元素内容就会返回
* 如果下一个事件是endtag,则返回空字符串,否则将抛出异常。成功地调用这个函数之后,解析器将被定位在endtag上。
* 不判断必定报异常,因为很多节点下面都是子元素,并不是文本内容。也不是endTag
*/
if ("title".equals(nodeName)) {
Log.e(nodeName + "----", xmlPullParser.nextText());//打印出改节点的值---只能在START_TAG中调用nextText()方法
}
}
break;
//完成某个节点的解析
case XmlPullParser.END_TAG: {
// Log.e(nodeName+"----", xmlPullParser.nextText());//报错
}
break;
}
eventType = xmlPullParser.next();
}
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
效果图就不再贴了,可自行测试看效果。
(3)SAX解析
原理:SAX会顺序扫描文档,在扫描到文档(document)开始与结束、元素(element)开始与结束、元素内容(characters)等时通知事件处理方法,事件处理方法进行相应处理,然后继续扫描,直到文档扫描结束。
//sax 解析
private void saxParser() {
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
XMLReader reader = factory.newSAXParser().getXMLReader();
MyHandler handler = new MyHandler();
reader.setContentHandler(handler);
InputStream mAssets = getAssets().open("test.xml");//得到assets目录下的文件
reader.parse(new InputSource(mAssets));//开始解析
} catch (SAXException e) {
e.printStackTrace();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public class MyHandler extends DefaultHandler {
StringBuilder title;
StringBuilder author;
String nodeName;//节点名
@Override
public void startDocument() throws SAXException {
//开始解析xml的时候调用
title = new StringBuilder();
author = new StringBuilder();
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
//开始解析某个节点的时候调用
nodeName = localName;
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
//获取节点内容的时候调用---注意,换行符空格什么的也会被当做内容解析出来。
switch (nodeName) {
case "title":
title.append(ch, start, length);
break;
case "author":
author.append(ch, start, length);
break;
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
//解析某个节点完成的时候调用
}
@Override
public void endDocument() throws SAXException {
//完成解析整个xml时候调用
Log.e("endElement", "title=" + title.toString().trim());
Log.e("endElement", "author=" + author.toString().trim());
super.endDocument();
}
}
最后 有个问题请大家帮忙解释:
// Log.e("title: " ,n.getElementsByTagName("title").item(0).getNodeValue());
//此处求告知为什么要上面的方法得不到值,下面的可以。
Log.e("title: " ,n.getElementsByTagName("title").item(0).getFirstChild().getNodeValue());
源码传送门