随着智能客服机器人产业的迅速发展,尤其是伴随着人工智能AI的风潮,预计在2020年我国智能客服市场将达到万亿级别。在智能客服机器人领域中对电话信道语音进行端点检测处理的应用正在不断扩展和深化。
目前语音端点检测(Voice Active Detection,简称VAD)的主要任务是准确快速判决出待处理的语音信号有话还是无话,作为自动语音识别(Automatic
Speech Recognition,简称ASR)系统的前置处理模块,一旦检测到话音信号,就启动ASR系统,并进行话音数据流的传输。
准确的VAD将提高自动语音识别系统的利用率和减少语音处理的数据量。
然而现实应用环境中,智能客服的应用场景十分广泛,话音活动检测面临的噪声环境种类多样。
一方面是外在环境的复杂,另一方面是方言和口音。外在环境复杂包括噪声、混响、回声等,而且噪音又分为不同的会议室、户外、商场等不同环境;在方言、口音方面,大家都知道,在我们国家,几十种方言,每个人都有自己的独特口音。
随着智能客服机器人的快速发展,在电话语音客服机器人系统中实现大规模稳健性好、精准性高、鲁棒性强、运算量少的电话语音实时检测技术,具有迫切的现实需求。
在电话语音交互场景中,VAD面临着两个难题:
1、可以成功检测到最低能量的语音(灵敏度)。
2、如何在多变的复杂噪声环境下成功检测(漏检率和虚检率)。
漏检反应的是原本是语音但是没有检测出来,而虚检率反应的是不是语音信号而被检测成语音信号的概率。相对而言漏检是不可接受的,而虚检可以通过后端的ASR和NLP算法进一步过滤,但是虚检会带来系统资源利用率上升,以及造成响应不及时。
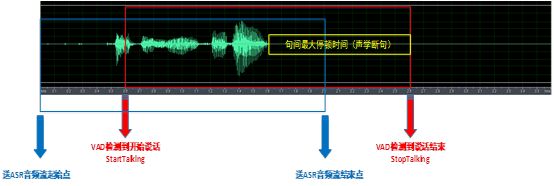
对于在目标人交互语音前发生虚检,主要问题是增加ASR识别处理数据量,如下图所示:


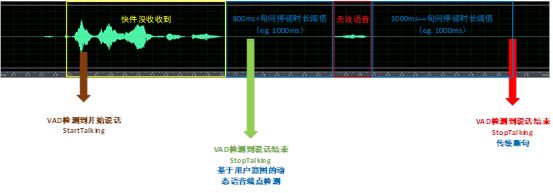
对于在目标人交互语音后发生虚检,不仅增加ASR识别处理数据量,还会造成响应不及时。传统的断句是基于能量的检测来判定,但是有两个主要缺点,一是无法过滤噪音和无效的语音,另外就是对说话人的要求较高,中间不能有停顿。如果句间停顿时长设置的太短,容易造成截断;句间停顿时长设置太长,又会造成响应不及时。如下图所示:


电话语音机器人采用的是全双工交互方式,作为一个持续的交互过程,不只是持续的拾音和网络传输,更需要包括持续的语音唤醒、智能有效人声检测、动态语音端点检测、无效语音拒识等各个模块相互配合,才能确保语音识别和语义理解模块能够做出快速的响应。目前,壹鸽科技采用的技术架构如下图所示:
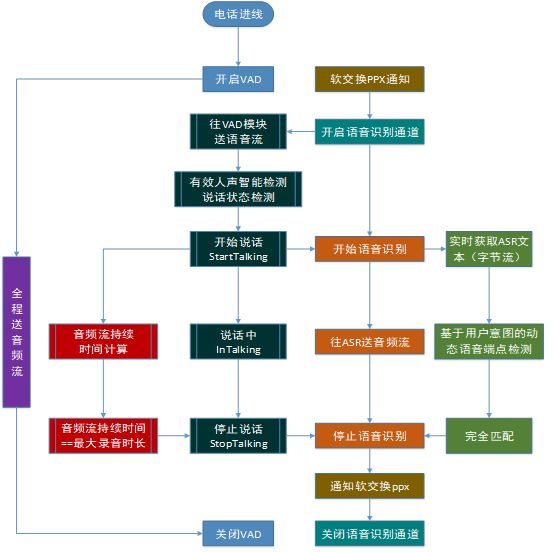
通过语音唤醒来触发语音识别,主要是降低虚检,尽量避免无意义的音频送入ASR识别,为保证在触发语音识别后所送往ASR的音频流的完整性,采用了前瞻技术,如下图所示:
为确保语音识别和语义理解能够做出快速的响应,壹鸽科技采用了基于模型的有效人声智能检测和基于用户意图的动态语音端点检测。
1、基于模型的有效人声智能检测
基于模型的检测可以有效解决噪音和无效语音。这块主要是通过采集不同环境的噪音,基于深度神经网络的训练出对应声学模型,进行过滤,把有效的语音传送到ASR服务器进行交互。
2、基于用户意图的动态语音端点检测
动态端点检测算法实现从连续输入的数据流中检测出包含完整用户意图的语音送入语义理解模块,可以很好的解决用户的停顿,因为在人机的交流过程中,在一句包含完整意图语音中,停顿是很常见的现象,这在我们对用户的行为分析中得到验证。
在持续的语音交互过程中,由于不同地区方言、口音差异,ASR识别后文本语料中含有大量的同音错误、音近错误,如平卷舌差异、前后鼻音差异、“了”(l)“呢”(n)差异以及“胡”(h)“福”(f)差异等用户大量无意识的输入错误及语音识别错误,造成大量语音识别错误文本送给后续的语义理解模块处理并做出交互动作,导致语音交互流程不可控,严重影响交互体验。
针对全双工交互中被吸收进来的无效的语音和无关说话内容,拒识和语音识别后文本纠错是必须,目前壹鸽科技正在从声学信号、语义等多个方面对接收的语音进行拒识判断和语音识别后文本纠错技术研究。
电话录音通常存在着大量的背景噪声、方言口音、信道干扰,而且电话录音通常采用较低的采样率,音质不高,这些都严重影响到语音识别的准确率。语音识别稳定度方面,我们主要考察语音识别引擎输出结果的统计特性,将通话录音识别结果输出音频检索网络,通过比较正确的语句和大量的错误语句,可以集中发现其中比较稳定和容易出错的部分,如发现一些出错较为频繁的短文本,例如:
正确语句:查快递
错误语句:前快递、车快递、千快递、彩快递、曹快递、送快递、天快递等
将这些出错较为频繁的短文本指定为语音关键字符串,在检索网络中进行匹配,输出检索结果,如下图所示:
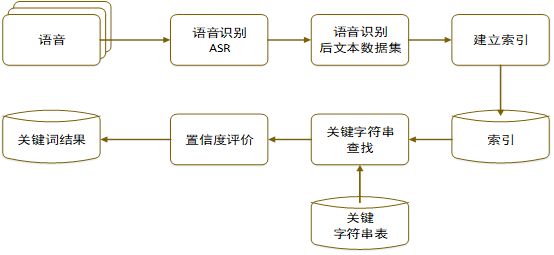
某些词语的发音组合对于语音识别系统很容易确定,而另一些则容易造成错误,特别是汉语。来自不同地域的人在某些音节发声的时候容易出现不规范的现象。对于这种现象进行统计,可以得到不同高频短文本的置信度,透过置信度评价来衡量前端识别的可靠性,对于那些可能是错误的结果,加以特别的处理,或者将之完全舍弃,让系统仅接受正确的部分,在很大程度上拓展了语音识别的应用范围。