在接下来的分词练习中将使用到四川大学公共管理学院的一篇新闻进行练习,文本如下:
为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。
一、利用在线分词工具进行分词练习
(1)ICTCLAS分词系统分词
ICTCLAS分词系统最早的中文开源分词项目之一,主要功能包括:中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。
使用时,首先进入ICTCLAS分词系统的在线演示,将新闻文本粘贴到空白框中,点击开始分析即可,当然,该分词系统也支持通过输入url实现页面文本的抓取,但是由于会抓取到很多页面上其他的信息,我在这里采用直接粘贴文本的方法
可以看到这个在线分析工具的分析方向和结果是十分丰富的:

a.分词标注

在ICTCLAS分词系统中我们可以看到它将全文分成了上面的内容(未展示完),比较突出的几个分词点是: 十九大,该分词系统将“十九”看做数词分到了一块; 公共管理学院也被处理成了三个分词,至于人名更多的是划分成了一个字一个字,但是总体来说划分出来原材料的内容并没有被划掉。用户也可以通过自定义词语来改变分词的划分结果
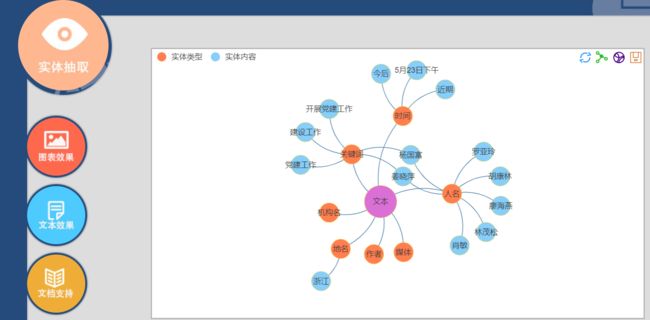
b.实体抽取
c.词频统计
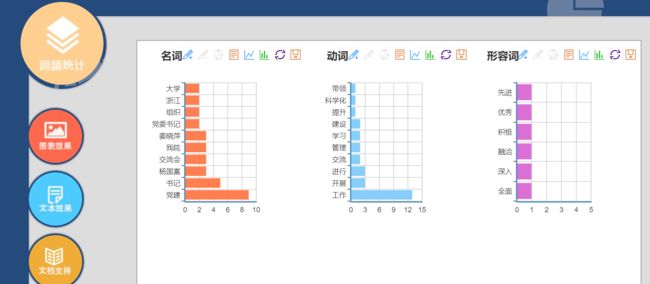
可以看到这一段新闻主要是关于党建工作、学习交流,与学院有关的。
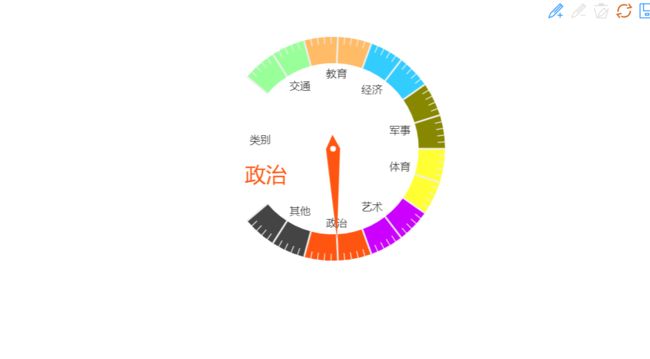
d.文本分类
e.关键词提取

这里有点小疑惑是“党建”在词频统计出现的次数是最多的,但是做出的关键词提取竟然只是用很小的字体显示出来的,并且还被放在了最边上。
(2)词无忧——中文在线分词
这个中文在线分词是我在网上随便找的一个在线分词工具,用它做分词练习是想有些对比效果。
同样,进入这个网站,将之前准备好的新闻文本粘贴到对应的空白框处,点击进行分词。可以看到出现如下情况:
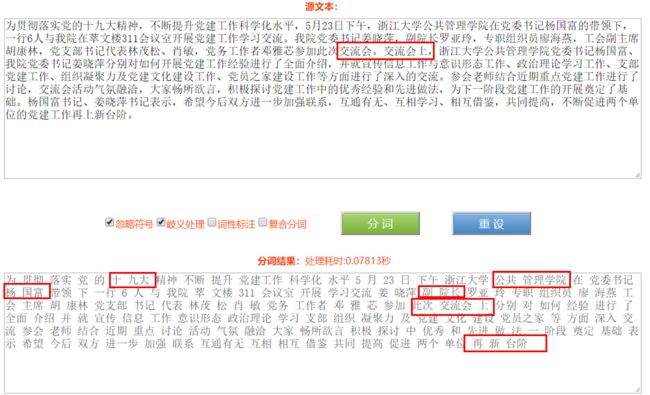
同样的,它也将 十九大划分成了两个词,和前面ICTCLAS分词系统不同的是它将其分成了十、九大,所以词库不同或者分词算法不同也会出现多种切分的情况。对于 公共管理学院它也没能将其划分到一块,不过倒是将“管理学院”切分到了一起。另外,这一分词切分工具出现了一个与前面ICTCLAS分词系统最大的不同得地方,在上图中“交流会”部分,该分词工具直接将其中一个“交流会”去掉了,这种情况还出现在后面的划分内容中。
二、利用Jieba进行分词练习
官方文档:https://github.com/fxsjy/jieba
Jieba简介:“结巴”中文分词:可以将中文的句子进行单词分割,多种分词模式,支持繁体、自定义词典。
特点:
a.支持三种分词模式:
•精确模式,试图将句子最精确地切开,适合文本分析;
•全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
•搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
b.支持繁体分词
c.支持自定义词典
d.MIT 授权协议
1.安装Jieba
pip install jieba
接下来,新建一个文件夹jeiba,在该文件夹下新建news.py
2.根据jieba的官方文档进行分词练习
(代码参考来源:jieba官方文档)
1)分词
•jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
•jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
•待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
•jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
•jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
# encoding=utf-8
import jieba
seg_list = jieba.cut("为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。")
print(", ".join(seg_list)) # 默认是精确模式,据说可以新词识别
seg_list = jieba.cut_for_search("为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。")
print(", ".join(seg_list)) # 搜索引擎模式
在命令行中进入到jieba目录下,输入:
python news.py
几种不同模式下的划分结果:




从上面的结果可以看出搜索引擎模式将该段新闻文本划分出多个相关词,划分结果相对来说较细。
2)添加自定义词典
载入词典
•开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
•用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
•词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
•词频省略时使用自动计算的能保证分出该词的词频。
从前面的分词结果可以看出,出现的“新词”,例如党的十九大、公共管理学院、萃文楼……都是词库中没有包含到的词,这里我们以将添加自定义词典的方式添加这些词来提高分词准确率。
首先,在jieba文件夹下新建userdict.text,设置添加的新词
党的十九大
公共管理学院
萃文楼
杨国富
再上新台阶
注意要一个自定义词一行,并且保存文件时需要以utf-8形式保存,否则会出现以下报错情况:
ValueError: dictionary file userdict.txt must be utf-8
其次,在jieba文件夹下新建news1.py文件,编辑如下:
# encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
test_sent = (
"为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
python news1.py
执行结果如下图:

我们可以看到经过自定义已经能够将“党的十九大”、“公共管理学院”等分成一个词了
第三,可以通过add_word() 和 del_word() 在程序中动态修改词典
调整词典
•使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可
在程序中动态修改词典。
•使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
•注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
下面举例动态添加词典,修改new1.py如下:
# encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
jieba.add_word('廖海燕')
jieba.add_word('副院长')
test_sent = (
"为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
执行结果如下:

可以看到经过添加词典,在前面规定的词典下,又将“副院长”以及“廖海燕”划分到了一起~
3)基于 TF-IDF 算法的关键词抽取
-
关键词提取
import jieba.analyse (引入关键词提取)
•jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
①sentence 为待提取的文本
②topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
③withWeight 为是否一并返回关键词权重值,默认值为 False
④allowPOS 仅包括指定词性的词,默认值为空,即不筛选
•jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
在jieba文件夹下新建news_extract_tags.py文件,编辑如下
# -*- coding: utf-8 -*-
import sys
sys.path.append('../')
import jieba
from jieba import analyse # 引入TF-IDF关键词抽取接口
from optparse import OptionParser
text = "为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
# 原始文本内容
keywords = analyse.extract_tags(text)
print ("keywords:")
for keyword in keywords:
print (keyword + "/")
python news_extract_tags.py
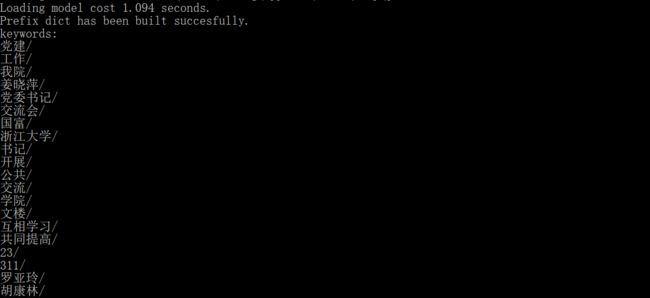
-
关键词提取所使用逆向文件频率
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
在程序中添加:
jieba.analyse.set_idf_path("file_name")
(官方提供的语料库好像打不开了)
-
关键词提取所使用停止词
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
由于每个网站都有“在”、“里面”、“也”、“的”、“它”、“为”等无索引意义的副词、介词、冠词……这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。因此通过使用停止词来减少这些词在关键词中的出现。
这里由于之前已经提出了一些关键,不涉及一些“也”、“的”、“它”、“为”等词,为了能更好的理解停止词的作用,我将在jieba文件夹下的新建stop.txt,在其中添加人名和数字,stop.txt如下(注意一行写一个词!)
的
是
和
至
与
着
或
我们
你们
妳们
他们
罗亚玲
胡康林
林茂松
肖敏
邓雅芯
姜晓萍
23
311
为了方便直接在news_extract_tags.py中添加一句:jieba.analyse.set_stop_words("stop.txt") ,如下:
# -*- coding: utf-8 -*-
import sys
sys.path.append('../')
import jieba
from jieba import analyse # 引入TF-IDF关键词抽取接口
from optparse import OptionParser
text = "为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
# 原始文本内容
jieba.analyse.set_stop_words("stop.txt") #停用词
keywords = analyse.extract_tags(text)
print ("keywords:")
for keyword in keywords:
print (keyword + "/")
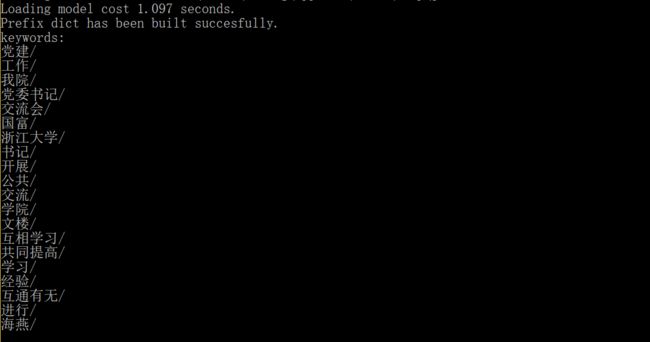
4)基于 TextRank 算法的关键词抽取
基于TextRank算法抽取关键词的主调函数是TextRank.textrank函数,主要是在jieba/analyse/textrank.py中实现。
其中,TextRank是为TextRank算法抽取关键词所定义的类。类在初始化时,默认加载了分词函数和词性标注函数
抽取方法:
•首先定义一个无向有权图,然后对句子进行分词;依次遍历分词结果,如果某个词i满足过滤条件(词性在词性过滤集合中,并且词的长度大于等于2,并且词不是停用词),然后将这个词之后窗口范围内的词j(这些词也需要满足过滤条件),将它们两两(词i和词j)作为key,出现的次数作为value,添加到共现词典中;
•然后,依次遍历共现词典,将词典中的每个元素,key = (词i,词j),value = 词i和词j出现的次数,其中词i,词j作为一条边起始点和终止点,共现的次数作为边的权重,添加到之前定义的无向有权图中。
•之后对这个无向有权图进行迭代运算textrank算法,最终经过若干次迭代后,算法收敛,每个词都对应一个指标值;
•如果设置了权重标志位,则根据指标值值对无向有权图中的词进行降序排序,最后输出topK个词作为关键词;
关键词抽取:
在jieba文件夹下新建news_textrank.py,编辑如下:
# -*- coding: utf-8 -*-
import sys
sys.path.append('../')
import jieba
from jieba import analyse
from optparse import OptionParser
text = "为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
keywords = analyse.textrank(text)
print ("keywords")
for keyword in keywords:
print (keyword + "/")

- 词性标注
•jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
•标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
# -*- coding: utf-8 -*-
import jieba
import jieba.posseg as pseg
words = pseg.cut("为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。")
for word, flag in words:
print('%s %s' % (word, flag))

- 并行分词
•原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
•基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
三、利用jieba提取关键词制作词云
新建文件news2.py
# encoding=utf-8
from __future__ import print_function, unicode_literals
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
import jieba.analyse
content = "为贯彻落实党的十九大精神,不断提升党建工作科学化水平,5月23日下午,浙江大学公共管理学院在党委书记杨国富的带领下,一行6人与我院在萃文楼311会议室开展党建工作学习交流。我院党委书记姜晓萍,副院长罗亚玲,专职组织员廖海燕,工会副主席胡康林,党支部书记代表林茂松、肖敏,党务工作者邓雅芯参加此次交流会。交流会上,浙江大学公共管理学院党委书记杨国富、我院党委书记姜晓萍分别对如何开展党建工作经验进行了全面介绍,并就宣传信息工作与意识形态工作、政治理论学习工作、支部党建工作、组织凝聚力及党建文化建设工作、党员之家建设工作等方面进行了深入的交流。参会老师结合近期重点党建工作进行了讨论,交流会活动气氛融洽,大家畅所欲言,积极探讨党建工作中的优秀经验和先进做法,为下一阶段党建工作的开展奠定了基础。杨国富书记、姜晓萍书记表示,希望今后双方进一步加强联系,互通有无、互相学习、相互借鉴,共同提高,不断促进两个单位的党建工作再上新台阶。"
try:
jieba.analyse.set_stop_words('stop.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
#权重是小数,为了凑整,乘以10000
print (v + '\t' + str(int(n * 10000)))
finally:
file_in.close()
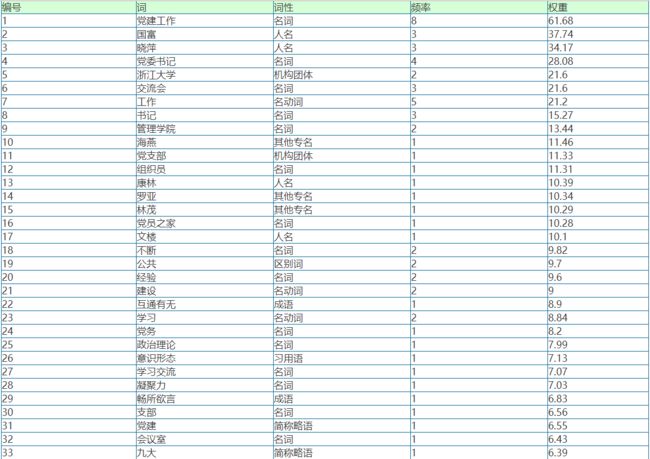
通过计算权重,为了能在云图上绘制出来,将权重乘以了10000,结果如下:
党建工作 7775
我院 3221
杨国富 2915
党委书记 2646
交流会 2490
公共管理学院 1943
工作 1708
浙江大学 1534
书记 1521
开展 1474
交流 1102
互相学习 999
共同提高 999
党的十九大 971
萃文楼 971
组织员 971
再上新台阶 971
学习 939
经验 930
互通有无 921
进行 909
畅所欲言 875
党建 822
科学化 804
党务 804
建设 798
不断 781
凝聚力 759
融洽 742
参会 735
专职 726
党支部 723
支部 721
下一阶段 714
意识形态 713
工会 684
会议室 674
贯彻落实 664
工作者 651
党员 632
借鉴 626
探讨 577
带领 568
一行 567
奠定 553
优秀 551
气氛 545
做法 539
宣传 531
院长 529
深入 520
老师 518
相互 514
讨论 510
先进 509
今后 506
下午 485
主席 469
双方 468
结合 466
全面 457
精神 456
联系 456
提升 452
介绍 449
促进 446
此次 445
单位 435
加强 435
理论 427
信息 427
重点 427
近期 426
希望 423
积极 422
政治 417
文化 413
参加 412
代表 403
大家 396
组织 395
水平 394
进一步 392
如何 388
基础 387
分别 383
活动 383
方面 346
两个 336
表示 318
接下来制作云图,打开WordArt.com,将数据粘贴进去
接下来依次设置形状和字体
值得注意的是这个工具是没有中文字体的。所以需要添加,就自己去网上下载一种字体(我这里下的是雅黑的),然后添加进入就OK了。

最后点击进行云图的制作:


参考:
jieba官方文档
结巴5——关键词抽取
用jieba分词提取关键词做漂亮的词云
推荐:
云图制作工具:WordArt.com