以下内容学习、摘录自《数学之美》

世界上有些事情常常超乎人们的想象,例如:余弦定理和新闻的分类看似八竿子打不着,却有着紧密的联系。
每天互联网都会产生大量的新闻或文章,对它们的分类需要自动化、准确的计算机程序来完成。所谓新闻的分类,或者更广义地讲任何文本的分类,无非是要把相似的新闻归入同一类中。如果让编辑来对新闻分类,他一定会先读懂新闻,然后找出其主题,最后根据主题的不同对新闻进行分类。但是计算机根本读不懂新闻,计算机本质上只能做快速计算。为了让计算机能够“算”新闻(而不是读新闻),就要求我们先把文字的新闻变成一组可计算的数字(量化新闻),然后再设计一个算法来算出任意两篇新闻的相似性。
首先让我们来看看怎样量化新闻:
1.建立一个常用词汇表(假设我们有64000个词汇);
2.对新闻进行分词;
3.计算新闻中每个词的TF-IDF值(可参考第11章);
如果单词表中的某个词在新闻中没有出现,对应的值为零,那么这64000个数,组成一个6400维的向量。我们就用这个向量来代表这篇新闻并称为新闻的特征向量( Feature Vector)。每一篇新闻都可以对应这样一个特征向量,向量中每一个维度的大小代表每个词对这篇新闻主题的贡献。当新闻从文字变成了数字后,计算机就有可能“算一算”新闻之间是否相似了。
再让我们看看如何算出两篇新闻的相似性。
学过向量代数的人都知道,向量实际上是多维空间从原点出发的有向线段,向量的夹角是衡量两个向量相近程度的度量。如下图:
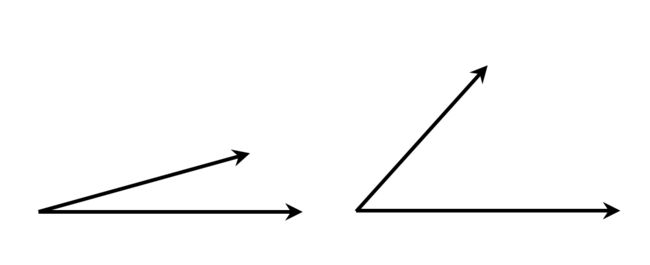
图中左边的两个向量夹角较小:比较相似;右边两个夹角较大:不太相似。因此,可以通过计算两个新闻向量的夹角来判断它们是否相似。这里就要用到余弦定理了,如下角A的余弦:
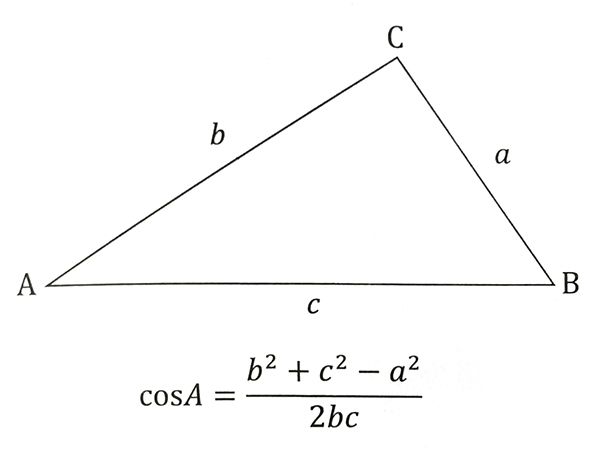
如果将三角形的两边b和c看成是两个以A为起点的向量,分母表示两个向量b和c的长度,分子表示两个向量的内积。举一个具体的例子,假如新闻X和新闻Y对应的向量分别是:
X1, X2, …, X64000
Y1, Y2, …, Y64000,
那么它们夹角的余弦等于:
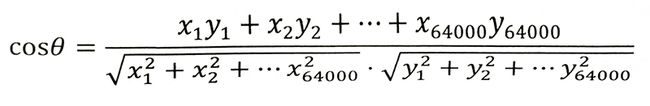
计算所得的余弦取值在0和1之间,也就是说夹角在0度到90度之间。当两条新闻向量夹角的余弦等于1时,这两个向量的夹角为零,两条新闻完全相同;当夹角的余弦接近于1时两条新闻相似,从而可以归成一类;夹角的余弦越小,夹角越大,两条新闻越不相关。当两个向量正交时(90度),夹角的余弦为零,说明两篇新闻根本没有相同的主题词,它们毫不相关。
经过以上步骤,我们能够量化新闻,并比较两篇新闻之间的相似度了。但新闻的分类还要解决“类别”问题。
常规的思路是“人工建立一些样板新闻”,并给该新闻定义好一个类别,如“体育”。然后把待分类新闻与之对比。这种人工的方式工作量大而且不准确。更好的方法是采用“无监督学习的聚类”方法。即:计算所有新闻之间两两的余弦相似性,把相似性大于一个阈值的新闻合并成一个小类。再把每个小类中所有的新闻作为一个整体,计算小类的特征向量、小类之间两两的余弦相似性,然后合并更大一点的小类。这样不断做下去,类别越来越少,而每个类越来越大。当某一类太大时,这一类里一些新闻之间的相似性就很小了,这时就要停止上述迭代的过程了。至此,自动分类完成。
采用自动聚类,而非人工定义类别的方法,可以看出优秀程序员做事的良好习惯:倾向于用机器(计算机)代替人工来完成重复性任务。虽然在短期内需要做一些额外的工作,但是从长远看可以节省很多时间和成本。
余弦定理就这样通过新闻的特征向量和新闻分类联系在一起了。我们在中学学习余弦定理时,恐怕很难想象它可以用来对新闻进行分类。在这里,我们再一次看到数学工具的用途。
大数据量时的余弦计算:我们假定常用词汇表的大小为10万,需要分类的新闻为10万篇,那总的计算量在10的15次方这个数量级。即使用100台服务器,每台服务器的计算能力是每秒1亿次,那么完成所有的计算需要两三个月,这个速度显然很慢。这里面可简化的地方非常多:
1.分母部分(向量的长度)不需要重复计算,计算向量a和向量b的余弦时,可以将它们的长度存起来,等计算向量a和向量c的余弦时,直接取用a的长度即可。这样,上面的计算量可以节省2/3;
2.在计算两个向量内积时,只需考虑向量中的非零元素。如果一篇新闻的一般长度不超过2000词,那么非零元素的个数一般也就是1000词左右,这样计算的复杂度大约可以下降100倍;
3.可以删除虚词,这里的虚词包括搜索中的非必留词,诸如“的”、“是”、“和”,以及“因为”、“所以”、“非常”,等等,这样计算时间还可以缩短几倍。
因此,10万篇新闻两两比较一下,也可以在一天内计算完成。
需要特别指出的是删除虚词,不仅可以提高计算速度,对新闻分类的准确性也大有好处,因为虚词的权重其实是一种噪音,干扰分类的正常进行。这一点与通信中过滤掉低频噪音是同样的原理。通过这件事,我们也可以看出自然语言处理和通信的很多道理是相通的。
位置的加权:和计算搜索相关性一样,出现在文本不同位置的词在分类时的重要性也不相同。显然,出现在标题中的词对主题的贡献远比出现在新闻正文中的重要。而即使在正文中,出现在文章开头和结尾的词也比出现在中间的词重要。因此要对标题和重要位置的词进行额外的加权,以提高文本分类的准确性。
点击这里可以查看《数学之美》的其它学习笔记。