CSS表达式和XPath表达式不是银色的子弹
当抓取一些网页时,数据被包含在一些本地JavaScript语句(js对象)中,我们需要找到一种方法来提取数据,而不会导入诸如phantomjs之类的重度浏览器。css表达和xpath表达无法很好地完成这项工作,我们需要其他选择来解决这个问题。
如果你Scrapy tutorial在谷歌搜索,大多数会告诉你如何使用css或xpath表达式来提取数据,只要你喜欢。但是,regex在另一些情况下,它是帮助您提取数据的另一个强大工具,似乎它已被大多数人忽略。
在这个Scrapy教程中,我将向您展示如何使用Regex和Json从原生JavaScript语句中提取数据。但是,您也可以在使用其他框架(如BeautifulSoup)开发web scraper时使用该方法。
检查HTML源代码
假设我们正在抓取的目标网页是http://quotes.toscrape.com/js/,如果您检查该网页的html源代码,您会发现数据是在javascript对象中调用的data。
var data = [
{
“tags” :[
“change” ,“deep-thoughts” ,
“thinking” ,
“world”
],
“author” :{
“name” :“Albert Einstein” ,
“goodreads_link” :“/ author / show / 9810.Albert_Einstein“ ,
”slug“ :”Albert-Einstein“
},”text“ :”\ u201c我们创造的世界是我们思考的过程,不改变我们的思维就不能改变。\ u201d “ },
......
data当页面在网络浏览器中呈现时,网页中的JavaScript会迭代对象并创建DOM,因为它不包含在原始HTML中,因此您无法使用xpath表达式或css表达式来提取Scrapy或BeautifulSoup中的数据。
在我们开始之前,您应该对Json的基本知识有所了解。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。人类阅读和写作很容易。机器解析和生成很容易。它基于JavaScript编程语言的一个子集
在这里,我们需要从HTML源代码中提取有效的json文本,然后json在Python中使用库来加载数据,之后我们可以轻松访问数据。
正则表达式来提取数据,JSON来加载数据
正则表达式是用于描述搜索模式的特殊文本字符串。你可以将正则表达式看作类固醇上的通配符。
首先,我们可以re从Python 进入Scrapy shell和导入库。
$ scrapy shell'http://quotes.toscrape.com/js/'
在[1]中:import re
现在我们需要从代码块中提取JavaScript列表
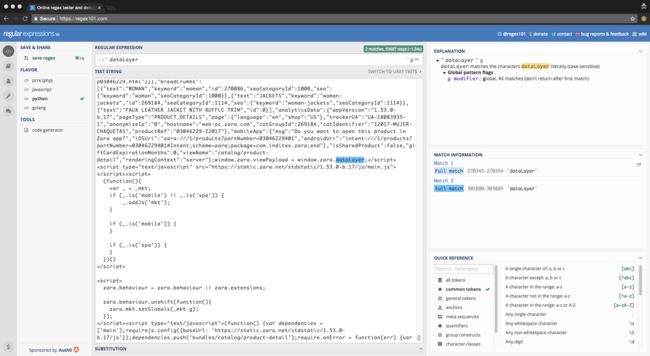
在[ 2 :data = re 。的findall (“VAR数据=(+);?\ n ” ,响应。体。解码(“UTF-8” ),再。小号)
让我解释一下这个说法。我们使用re.findall帮助我们从中找到匹配文本的方法response.body。var data =(.+?);这里是我们创建的正则表达式表达式的含义是查找var data第一个和第一个之间的所有内容;\n。这re.S是正则表达式传递的正则表达式,这里re.S告诉正则表达式引擎表达式匹配换行符。
如果re.findall可以找到一个mateched,它会回退,如果没有,它会返回None。提取json数据文本后,我们可以在Python中使用json库来加载数据,以便我们可以轻松访问数据。
导入json
ls = []
如果数据:
ls = json.loads(data [0])
如果ls:
打印(LS)
现在我们可以看到数据可以像Python原生字典和列表一样被访问。
[{'author':{'goodreads_link':'/author/show/9810.Albert_Einstein',
'名字':'阿尔伯特爱因斯坦',
'slug':'Albert-Einstein'},
'tags':['change','deep-thoughts','thinking','world'],
'文本':''我们创造它的世界是我们思考的过程。不改变我们的想法就不能改变。“'},
{'author':{'goodreads_link':'/author/show/1077326.J_K_Rowling',
'name':'JK罗琳',
'slu'':'JK罗琳'},
'tags':['abilities','choices'],
'文本':'“这是我们的选择,哈利,它显示了我们真正的实力,远远超过
我们的能力。”'},
{'author':{'goodreads_link':'/author/show/9810.Albert_Einstein',
'名字':'阿尔伯特爱因斯坦',
'slug':'Albert-Einstein'},
'标签':['励志','生活','生活','奇迹','奇迹'], '文字':'“只有两种方式来过你的生活。其中一个就像没有奇迹。另一种就好像一切都是奇迹。“'}, ......
]
有没有一些好的资源或工具可以让我学习正则表达式?
如果你想学习正则表达式,你可以检查re模块的doc 。
python2重新模块
python3重新模块
如果你想调试你的正则表达式,你可以检查regex101,这是一个很棒的在线免费工具,可以让你调试你的正则表达式。
有没有其他的方法来从JavaScript中抓取数据
JavaScript的数据将被用于创建网页的html元素,所以如果你很难在scrapy蜘蛛中编写正则表达式,你可以使用Selenium来完成工作。
真实世界的例子
现在我可以给你一个真实的例子,让你更好地理解关键点。
例如,你的老板需要你收集一些关于时尚产业的数据,那么你可能想写蜘蛛来获取zara.com的数据,当挖掘zara产品的数据时,你会发现产品的细节包含在javascript代码块,因此您可以使用我上面讨论的方法快速提取数据。
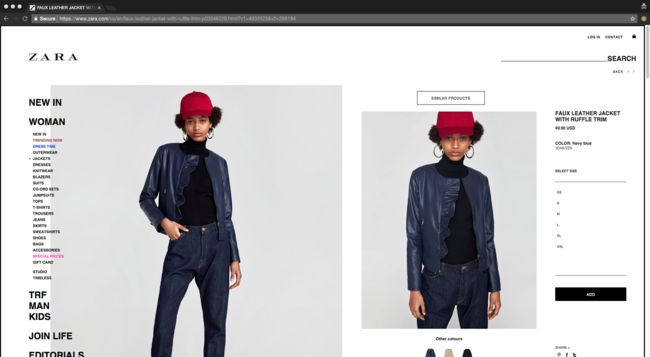
您可以在代码块中找到产品的详细信息
window.zara.appConfig = ............window.zara.viewPayload = window.zara.dataLayer;
现在你可以享受自己的写的过程了。