项目说明 :
在linux终端下有时候遇到一个想查询的英语单词 , 但是不想打开浏览器去谷歌或者百度去搜索 , 因此就写了这个基于爬虫的单词翻译工具 , 实现原理很简单 , 基本开发已经完成 ,总共有三个分支 , 分别对应 : 爬虫/BaiduAPI/YoudaoAPI , 感觉在有时候读代码变量命名不太懂的时候还是挺有用的 , 毕竟比打开浏览器去访问翻译网站方便多了
项目地址 有兴趣的小伙伴儿咱们可以一起写 : D
安装方法 :
- 申请有道翻译Key
需要填写一下邮箱和应用名称 , 然后邮箱中会收到Key , 在第三步会用到
- 安装Python第三方库
安装第三方python库
sudo apt-get install python-pip
sudo pip install requests
sudo pip install bs4
- 克隆项目
git clone https://git.coding.net/yihangwang/PyTranslator.git
cd PyTranslator
git checkout release
- 进行安装
sudo python Setup.py
按照Setup.py中的指引就可以完成安装
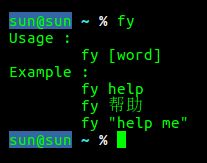
使用方法 :
Usage :
fy [Your words]
Example :
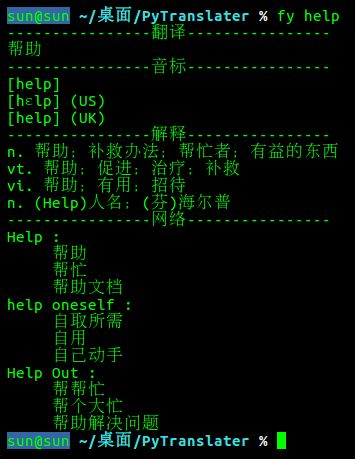
fy help
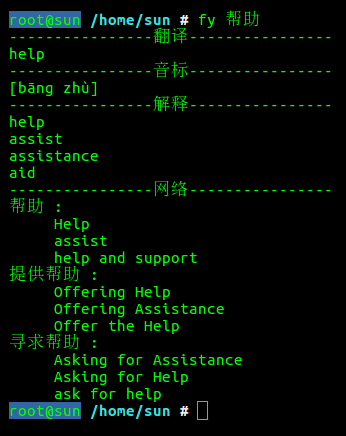
fy 帮助
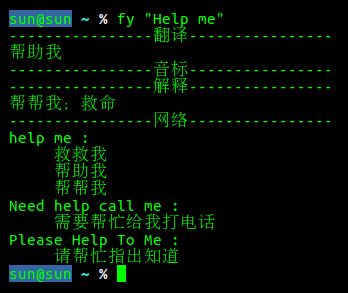
fy "Help me"
悄悄话 :
其实只用一句shell命令就可以在linux下面完成翻译工作 , 需要用到curl, grep和tr命令
curl http://dict.cn/[Your word] | grep "" | tr -d "\t"
curl http://dict.cn/help | grep "" | tr -d "\t"
T_T由于不会正则...只能用这种比较low的方法 , 不知道怎么过滤掉流中的字符串 ... 所以输出格式还是有点问题
这里非常感谢@左蓝同学提供shell命令 :
curl -s http://dict.cn/help | grep "" | tr -d '\t' | sed 's///g' | sed 's/<\/li>//g' | sed 's/<\/strong>//g'

截图展示 :
原理 : (使用爬虫进行实现 , 对应git仓库的master分支)
使用爬虫技术 , 将用户输入作为关键字发送HTTP请求到在线翻译网站(http://dict.cn/)
解析返回HTML页面 , 提取有用的信息 , 将结果呈现给用户
首先需要分析目标网站是如何处理用户参数的
使用浏览器访问该网站 , 任意查询某单词 , 例如help
发现跳转到新的结果页面以后 , url 就变成了 : http://dict.cn/help
说明我们可以访问这样的url就可以得到查询结果 :
http://dict.cn/[word]
这样的话 , 我们的脚本就需要做这几件事情
- 接受用户输入的单词
- 拼接url
- 访问该url得到返回页面
- 解析页面 , 提取我们感兴趣的信息
这样的话 , 前三步都应该不会很难 ,
重要的是我们如何从返回页面中提取出我们感兴趣的信息
首先我们分析一下结果页面中都包含哪些有效的数据 ?
经过分析得到 :
1. 音标
2. 简意
---
3. 详尽释义
4. 英英释义
5. 行业释义
6. 双解释义
---
7. 例句
8. 常见句型
9. 常用短语
10. 词汇搭配
11. 经典引文
---
12. 词语用法
13. 词义辨析
14. 常见错误
15. 词源解说
---
16. 近反义词
17. 缩略词
18. 互动百科
19. 临近单词
这个时候 , 我们需要对结果页面的代码结构进行分析 , 我们需要分析这些信息都具有什么样的特征可以供我们进行提取
分析之后得到 :
1. 音标 # ...
2. 简意 # ...
---
3. 详尽释义 # ...
4. 英英释义 # ...
5. 行业释义 # ...
6. 双解释义 # ...
---
7. 例句 # ...
8. 常见句型 # ...
9. 常用短语 # ...
10. 词汇搭配 # ...
11. 经典引文 # ...
---
12. 词语用法 # ...
13. 词义辨析 # ...
14. 常见错误 # ...
15. 词源解说 # ...
---
16. 近反义词 # ...
17. 缩略词 # ...
18. 互动百科 # ...
19. 临近单词 # ...
总共有这么多的属性 , 我们这里先做一个比较简单的功能 , 就是将用户输入单词的简单意思输出
这样的话 , 可能我们只需要用到第二个属性 : 简意 # ...
这样我们解析了返回页面的DOM节点之后就可以查找对应的节点
TODO :
- 将结果保存在本地 , 当用户多次查找的时候减轻服务器的压力
- 添加命令行参数 , 让用户可以自己定义都需要返回什么数据 ,
比如说有的时候就只需要知道单词的意思 , 但是有的时候就需要深入学习这个单词
这个时候就需要用户使用参数来获取更加详细的信息 - 帮助文档
汉译英功能- 自动补全功能
短语查询功能- 整句翻译功能
做成一个小项目 , 可以直接给别人用的那种