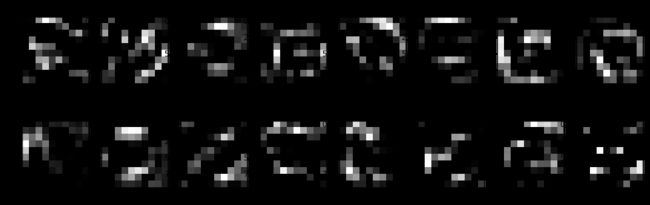Traffic Sign Recognition
Build a Traffic Sign Recognition Project
The goals / steps of this project are the following:
- Load the data set (see below for links to the project data set)
- Explore, summarize and visualize the data set
- Design, train and test a model architecture
- Use the model to make predictions on new images
- Analyze the softmax probabilities of the new images
- Summarize the results with a written report
Here is a link to my project code
Data Set Summary & Exploration
1. Provide a basic summary of the data set. In the code, the analysis should be done using python, numpy and/or pandas methods rather than hardcoding results manually.
Re: I used the python, numpy and matplotlib library to calculate summary statistics of the traffic signs data set:
- The size of training set is ?
34799 (Is it a large enough dataset? I'm not sure. The traffic signs in different weather, brightness condition are totally different. Image augmentation is good choice to solve the brightness problem. I wonder the whether we should collect a larger dataset.) - The size of the validation set is ?
4410 - The size of test set is ?
12630 - The shape of a traffic sign image is ?
Image data shape = (32, 32,3) - The number of unique classes/labels in the data set is ?
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42}
2. Include an exploratory visualization of the dataset.
Re: First, we draw all the classes in the following figure. There are 43 classes in all. As shown in the figure, some images are too dark to figure out the detail of the sign. It's necessary to preprocess the image into grayscale.

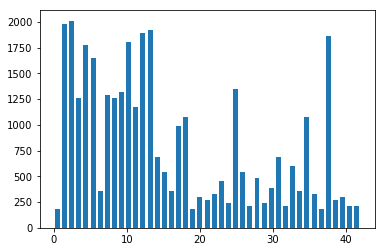
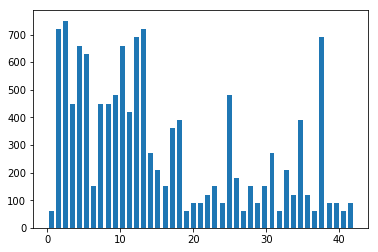
Here is an exploratory visualization of the data set. It is a bar chart showing distributions of all the classes in train, validation and test data. We can see that the distributions in the three parts are similar.

Design and Test a Model Architecture
3. Describe how you preprocessed the image data. What techniques were chosen and why did you choose these techniques? Consider including images showing the output of each preprocessing technique. Pre-processing refers to techniques such as converting to grayscale, normalization, etc.
Re: As a first step, I decided to convert the images to grayscale. On the one hand, the color information is not very useful. On the other hand, the gray image has only one channel, which greatly reduces the computation.
Here is an example of a traffic sign image before and after grayscaling.

The codes are as follows:
# Convert to grayscale
X_train_rgb = X_train
X_train_gry = np.sum(X_train/3, axis=3, keepdims=True)
X_test_rgb = X_test
X_test_gry = np.sum(X_test/3, axis=3, keepdims=True)
X_valid_rgb = X_valid
X_valid_gry = np.sum(X_valid/3, axis=3, keepdims=True)
As a last step, I normalized the image data because the normalization of a relational data can reduce data redundancy and improve data integrity.
# Normalize the train and test datasets to (-1,1)
X_train_normalized = (X_train - 128)/128
X_test_normalized = (X_test - 128)/128
X_valid_normalized = (X_valid - 128)/128
The difference between the original data set and the normalized data set is as follows. We cannot tell the difference by looking at the images.

4. Describe what your final model architecture looks like including model type, layers, layer sizes, connectivity, etc.) Consider including a diagram and/or table describing the final model.
Re: My final model is based on LeNet architecture. To improve the performance, we add one more dense layer. The overall model consists of the following layers:
| Layer | Description | |
|---|---|---|
| Input | 32x32x1 Gray image | |
| Convolution 5x5 | 1x1 stride, valid padding, outputs 28x28x6 | |
| RELU | ||
| Max pooling | 2x2 stride, outputs 14x14x6 | |
| Convolution 5x5 | 1x1 stride, valid padding, outputs 10x10x16 | |
| RELU | ||
| Max pooling | 2x2 stride, outputs 5x5x16 | |
| Flatten | outputs 400 | |
| Fully connected | outputs 256 | |
| Fully connected | outputs 120 | |
| Fully connected | outputs 84 | |
| Fully connected | outputs 43 | |
| Softmax | outputs 43 |
5. Describe how you trained your model. The discussion can include the type of optimizer, the batch size, number of epochs and any hyperparameters such as learning rate.
Re: To train the model, I used an Adam optimizer with learning rate 0.001. Learning rate 0.01 is too large, the CNN cannot learn anything from the data. Learning rate 0.0001 is too small, which consumes much time in training. The batch size is set to 128. Larger batch size costs much time. The number of epochs is 100. Actually, the model converges about after 35 epochs.
6. Describe the approach taken for finding a solution and getting the validation set accuracy to be at least 0.93. Include in the discussion the results on the training, validation and test sets and where in the code these were calculated.
My final model results were:
- training set accuracy of ?
Re: 96.2% - validation set accuracy of ?
Re: 95.9% - test set accuracy of ?
Re: 93.8%
If a well known architecture was chosen:
What architecture was chosen?
Re: We choose the LeNet to classify the images.Why did you believe it would be relevant to the traffic sign application?
Re: LeNet is simple and it works well on the Minist dataset, which is also a multi-classification task.How does the final model's accuracy on the training, validation and test set provide evidence that the model is working well?
Re: The final model's accuracy the training, validation and test set are similar. Hence, it works well. If the training acc is much larger than the validation and test acc, it is over-fitting. If all the acc are small, it is under-fitting. For the over-fitting case, we can add dropout and regularizer. For the under-fitting case, we can add more fully connected layers to get better performance.
Test a Model on New Images
7. Choose nine German traffic signs found on the web and provide them in the report. For each image, discuss what quality or qualities might be difficult to classify.
Re: Here are five German traffic signs that I found on the web. All the images are high resolution. To feed these five images to our LeNet model, we first resize the image into (32,32,3). The pre-process of the images is similar to the training data.





In my opinion, all the traffic signs in the images are very easy to identify. However, the experimental results are not the situation that we imagined.
8. Discuss the model's predictions on these new traffic signs and compare the results to predicting on the test set. At a minimum, discuss what the predictions were, the accuracy on these new predictions, and compare the accuracy to the accuracy on the test set (OPTIONAL: Discuss the results in more detail as described in the "Stand Out Suggestions" part of the rubric).
Here are the results of the prediction:
| Image | Prediction |
|---|---|
| Yield | Traffic lights ahead |
| General danger | Traffic lights ahead |
| Priority road | Traffic lights ahead |
| Turn right | Traffic lights ahead |
| Stop Sign | Traffic lights ahead |
Re: The model was able to correctly guess 0 of the 5 traffic signs, which gives an accuracy of 0%. The problem is that the data is too small, i.e., the resolution of the image is only 32×32. The model may perform well on larger images. We didn't use augmentation technique. In addition, the LeNet is not robust. In other words, the convolutional neural network is not robust against noises and simple tansformations. Yan Lecun published a paper that demonstrate that the neural network cannot identify some traffic signs after they take a photo and feed the photo into CNN. Hence, they proposed the adversarial training method to make the model robust. It's a very hot topic recently. In the future, we can also try the adversarial training method to improve the performance.
9. Describe how certain the model is when predicting on each of the five new images by looking at the softmax probabilities for each prediction. Provide the top 5 softmax probabilities for each image along with the sign type of each probability.
Re: The code for making predictions on my final model is located in the 60th cell of the Ipython notebook.
For the first image, the model is relatively sure that this is a stop sign (probability of 0.4). The top five soft max probabilities were
| Probability | Prediction |
|---|---|
| .60 | General danger |
| .20 | Speed limit 70 |
| .05 | Bend |
| .04 | Bumpy Road |
| .01 | Slippery Road |
(Optional) Visualizing the Neural Network (See Step 4 of the Ipython notebook for more details)
10. Discuss the visual output of your trained network's feature maps. What characteristics did the neural network use to make classifications?
Re: The feature maps learn many high level features from the images. For instance, the shape of the sign, and the edges of numbers on the sign.