一. 背景
1. 算法应用
短文本, 长文档, 网页以及新闻的相似度, 购物网站的协同过滤推荐算法
2. problem
找到所有相互距离在s以内的vector pairs, 设我们有n个vector.
naive solution takes O(n^2)
我们的目标是O(n).
今天的例子以document similarity为例子.
3. Jaccard distance/similarity
sim(C1, C2) = |C1∩C2| / |C1∪C2|
d(C1, C2) = 1 - sim
比如: {a, a, a, b} 和 {a, a, b, b, c}的相似度 sim = {a, a, b} / 9 = 3/9 = 1/3, 注意有重复元素的话, 交集中a要取出现在两个集合中的最小次数2, 并集中a要取在两个出现的次数之和5.
一般我们对距离函数的要求: 距离值非负, 一个点/向量自己到自己的距离必须为0, 值的对称性.
Jaccard similarity可以应用在镜像网站的检查, 相似新闻稿的挖掘. (这个可以做毕设!!!)
4. 相似发掘的三个关键技巧
(1) Shingling: Convert doc to sets
(2) Min-Hashing: Convert larges sets to short signatrues while preserving similarity characters.
(3) Locality-Sensitive Hashing(LSH): Focus on pairs of signatures likely to be similar
二. k-shingle
1. k - Shingle(k-gram) for a doc
我们把输入的文档都看成字符串, 那么我们假设有doc = "abcab", 我们如果计算2-Shignle的集合, 就是 {'ab', 'bc, 'ca'} , 注意我们舍弃了最后尾部的'ab', 这是因为它和前面已经出现过的'ab'重复了.
实际应用中, Shingle的单位可以是一个letter, 也可以是一个word. 这里我们用letter来作为讨论单位.
同时, 我们还会对多个空格进行压缩成单个空格, 并且把所有空格替换成'_'以方便运算.
2. 把Shingle映射成token(int类型)
研究论文类型的长文档往往使用的是9-Shingle, 长得类似 {'able_to_d', 'o_somethi'}.
我们可以把这个集合中的每个9-Shingle都哈希成数值(int, 4Byte), 这样从而可以实现存储空间的压缩, 并且方便了后面的运算.
三. min-hash signature
1. 向量运算
each doc is a 0/1 bit vector in the space of k-shingles.
这里为了方便, 我们假设我们在讨论1-Shingle,
比如d1 = {a, d}, d2 = {c}, d3 = {b, d, e}, d4= {a, c, d}.
我们的全集, 即向量空间, 或者说字典集是 {a, b, c, d, e}, 这其实意味着这是一个五个维度的空间.
我们可以列出一个5×4的矩阵M. 一般化地, 我们把这时候的矩阵叫做特征矩阵M(m行p列)
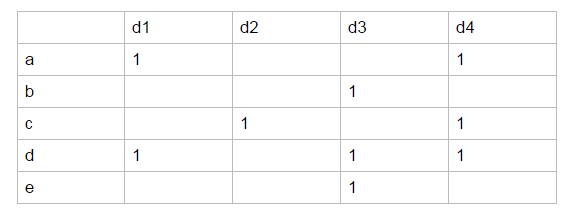
note: 这里我只标出了1, 其他位置都是0. 而且, 这里我们为了容易理解, 用的还是a, b, c, d, e这样的具体1-Shigle的字符串型变量, 真实的情况应该是它们被映射成了int型数值了, 比如1, 2, 3, 4, 5这样. 我们定义三种情形:
X情形为1,1
Y情形为1,0或者0,1
Z情形为0,0.
让我们注意, 这时候sim(d1, d2) = X / { X+Y } = 0, sim(d3, d4) = 1/5
2. 构建signature (n-round-min-hash)
1) min-hash
permutation. 我们先把行的维度进行随机排列, 可能会从本来的abcde->12345变成beadc->12345.
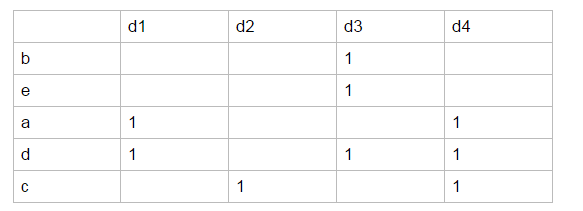
这时候, 我们将把一个Vector给映射成一个1-Shingle, 比如H(d1) = a, H(d2) = c, H(d3) = b, H(d4) = a
(注意: 在实际情况中是映射成a, b等1-Shingle对应的int值)
这样子我们成功把一个Vector的大小给大大压缩成了一个数值.
2) 构建min-hash signature
构建signature十分简单, 只需要做n次permutation(常用的n=100), 然后每次我们都把d1到dp转换成为数值value[1]~value[p], 最后我们可以构成一个n行p列的S矩阵(SmallMatrix)来表示原先的m行p列M特征矩阵(MassiveMatrix). 通常, S矩阵明显小于M矩阵.
四. LSH: Locality Sensitive Hash
我们将用一个函数F来评估d1和d2是否是一个candidate pair of similarity>= s, 即值得去运算的潜在高相似文档pair.
1. 用S矩阵估计出sim
那么, 先看下我们所有的100行p列的S矩阵能为我们做什么.
我们可以用100行中H(d1)=H(d2)的equal/all比率来估计sim, 为什么?
我们知道, 如果d1和d2是50%程度相似的, sim=1/2=X/(X+Y), 也就是说如果在某个维度b上, b(d1)∪b(d2) = 1, 我们会有一半的情况是二者都为1, 剩下一半情况是1, 0和0,1这样子.
回顾下, 我们的这个S矩阵, 本身就是遇到第一个为1的时候记录下这行的1-Shingle, 因此我们根本不用担心二者都为0的情形会在表中出现.
所以, 事实上S表中100行里面, H(d1)==H(d2)/all 就代表了X/X+Y的值, 也就是sim的值.
2. 切band极大改进算法效率&提高中部斜率
这时候, 我们能估计斜率了, 问题理论上是得到了解决. 然而, 我们对比两个文档仍然需要把他们的所有行都比较一次, 而我们有n choose 2对 -->算法是O(n^2)的.
我们要提高效率, 就得极大改进算法对比的速度.
我们将再利用一次哈希, 这次, 我们会将之前所有文档都进行多次哈希到bucket中, 这样我们只需要去检查至少有一次哈希到同一个bucket中的文档对是否真的是候选对, 这样我们的对文档的检查算法的复杂度将大大下降.
哈希算法策略:
把标志矩阵M切成band, 每个band 有r行, 也就是 总行数n = b · r, 这里假设为100 = 20x5
接下来我们进行哈希,
在同一个band里, 如果两个列的全部5行都能被一起hash到一个bucket里的话, 那么他们就是candidate pair. 这20个band里头, 只要有一个band能够实现这样的要求, 那么就允许这两个doc被hash到一个bucket.
3. 分析false positive, false negative
原先, 如果我们采用直接取第一行是否都为1这种简单naive算法的话, 对于sim=0.8的情形, 我们犯错排除false negative的概率有0.2; 而对于sim=0.3的情形, 我们犯错算入的概率false positive的概率是0.3, 这并不理想.
而用了我们的LocalSensitiveHash
如果真实的sim=0.8 和真实的sim=0.3的文档对d1/d2, 在这种情况下被hash到一个bucket的概率是多少呢???
P(sim=0.8) = 1-(1-0.85)20 = 0.99964
P(sim=0.3) = 1-(1-0.35)20 = 0.04743
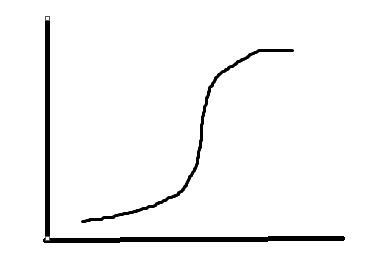
显然, 这样的hash方法大大放大了原有的sim差异, 使得落在一个bucket的概率上极大可能是真正的相似文档pair.
note: 其实b, r的值的选取是有讲究的, 这是因为threshhold value -> t = (1/b)^(1/r), 当b=20, r=5的时候, t=0.55.
而实际情况中, 我们一般是依据t来选取b和r的.
五.总结
min-Hash signature方法, 主要是为了用较小体积的签名来代替原先比较大体积的文档特征. 我们用十个哈希函数给doc1, doc2的所有k-shingle(可以是3-shingle, 可能每个文档有1000个3-shingle)进行哈希计算, 将哈希值最小的k-shingle的哈希值记录下来, 我们做十次这样子的事, 得到了H1(doc1), H2(doc1), … , H10(doc1)以及H1(doc2), …, H10(doc2).
接下来估算sim(doc1, doc2) = 两个doc哈希值交集/两个doc哈希值并集 (其实就是在minHash签名之上去算Jaccard相似度)
这是因为哈希本质上是在用相同的规则随机选出一个k-shingle代表整个doc, 那么如果doc1和doc2有1/3的shingle是一样的, 则有1/3的概率下, 他们会有相同的哈希值来代表整个doc. 10中有3个相同, 那么我们算出来的就是sim=3/(7+7) = 3/14;
这是一种估计而已. 也有一定的可能性说我随机选10个shingle, 结果都选到了恰好不一样的shingle. 因此如果空间允许, 可以把代表doc的哈希值增加到30个, 50个, 乃至100个(针对特别长的文档).
接下来, 由于我们不希望计算O(n^2)时间的Jaccard相似度, 我们只关心相似度差异最大或者最小的那些pair. 因此我们搞了一个LocalSensitiveHash. 我们制定一个threshold值, 然后根据t = (1/b)^(1/r), 给出b和r值. 我们设置b个哈希数组行, 然后对每个band, 如果某两列值完全一样, 那可以哈希到一个bucket中. 对于b个band对应的b个哈希数组行, 对每个桶中只要是被哈希到一个桶里面的值, 我们就当做相似文档的candidate, 进行检查. 检查的时候可以先再用min-Hash值估算一下相似度,如果相似了, 再用比较大的k-shingle来算一次确保正确.
参考资料:
MinHash Tutorial with Python Code
http://mccormickml.com/2015/06/12/minhash-tutorial-with-python-code/
Stanford, Mining of Massive Dataset(MMDS)