什么是高可用
高可用是系统的一个特性,保证系统能在足够长的时间内提供指定程度的服务等级。再细化一下,可以说是在有限的故障条件下,提供一定级别的稳定服务。
在传统领域,SLA用于在商业上定义系统的高可用。
SLA全称是service level agreement,在网络服务供应商领域被广泛使用,约定了最小带宽,同时服务客户数,最大故障时间等等一系列指标。在软件领域,最广泛使用的指标是平均服务时间。
见下图
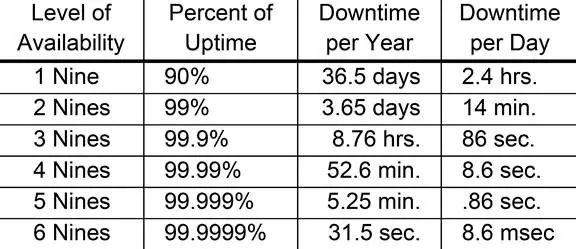
因为软件领域的各项指标不好度量,很难约束,因此其他指标也很少提到。但可以想像,作为高可用的系统,不止要有达标的故障时间,同时要保证在服务时间达到用户可接受的服务质量,对于数据库而言,类似tps,事务平均时延,99%时延等。
各家SLA展播
| 服务商及产品 | 可用性 | 数据持久度 | 除外条款 | 赔偿条款 |
|---|---|---|---|---|
| 阿里云ECS | 99.95% | 99.9999999% | (1)不可使用的服务时间低于5分钟的,不计入不可用时间;(2)阿里云预先通知用户后进行系统维护所引起的,包括割接、维修、升级和模拟故障演练; (3)不可抗力以及意外事件引起的; | 不可用时间100倍 |
| 阿里云rds | 99.95% | 同上,高可用版和金融版为1分钟 | 不可用时间100倍,高可用版和金融版,服务费的15% - 30% - 100% (99.95%-99%-95%) | |
| AWS EC2 | 99.95% | 无活跃链接,运维不算,不可抗力不算 | 低于99.95%,赔 10%;低于99%,赔30% | |
| AWS RDS | 99.95% | 类似阿里,不计时间为1分钟 | 低于99.95%,赔 10%;低于99%,赔25% | |
| AWS S3 | 99.99% | 99.999999999% | ||
| 腾讯云云主机 | 99.95% | 99.999% | 5分钟以下不计费,无其他除外条款 | 不可用时间100倍 |
从这几家对比看,AWS是最强的,阿里也差不多了,腾讯云是相对较差的,看一下服务条款的完善程度就能明显地感受到。
评价高可用的标准
评价系统高可用,可以有几个维度:
- 有限故障下数据是否丢失,系统的服务等级降低幅度是否合理;
- 高压力下系统的服务等级;
- 服务变更下系统的服务等级;
有一个关于故障条件下系统表现较好的分级,见下表:
| 分级 | 描述 |
|---|---|
| 1 | Crash with data corruption, destruction. |
| 2 | Crash with new data loss. |
| 3 | Crash without data loss. |
| 4 | No crash, but with no or very limited service, low service quality. |
| 5 | Partial or limited service, with good to medium service quality. |
| 6 | Failover with significant user visible delay, near full quality of service |
| 7 | Failover with minimal to none user visible delay, near full qualityof service. |
摘自《来自 Google 的高可用架构理念与实践》
数据库系统的一些度量方法
数据持久度
数据库系统可以通过副本备份等方式有效提高数据持久度,抵御磁盘损坏等故障造成数据丢失的风险。
当然随着现在分布式存储的发展,持久度已经很少有人关心了,但是对于直接使用磁盘的情况,这仍然是一个需要考虑的问题。
平均服务时间
对于计算服务可用时间,引入3个来自工业界的概念:
- MTBF (Mean Time Between Failures) =平均故障間隔時間
- MTTF (Mean Time To Failure) =平均故障時間
- MTTR (Mean Time To Repair) =平均修復時間
高可用时间=MTBF/(MTBF+MTTF)
显然,这里存在执行上的问题,假设tcp超时时间是2min,那么低于两分钟是很难确定到底是系统故障还仅仅是软件处理较慢。或者软件由于资源(比如IO)受限被卡住,这是客户也是很难判断是否发生了故障。
对于系统管理员来说,同样存在类似的问题,心跳检测是最常见的监控手段,但是心跳时间也很难设置太短,这是受网络条件限制的,常常,故障的发现就是以分钟计算的。
RTO/RPO
RTO和RPO是传统数据库领域常见的两个衡量高可用的指标。
- RTO(Recovery time objective):故障恢复耗时
- RPO(Recovery point objective):恢复后数据对应的时间点,即丢失的数据量转换为时间
举个简单的例子,数据库同城同步备机,故障后RPO必然是0,tikv一般情况下RPO也是0。RTO也是秒级的,对于不同的故障,结果也不同
请求成功率
对于分布式系统来说,从系统层面考察平均服务时间的意义并不是很大,对于很多分布式系统来说,单机的故障并不能影响系统整体稳定的继续运行,从这个角度来说,系统可用性可以说是100%的。这时,计算请求的成功数可能更适合这样的系统,如下:
可用性=成功请求数/总请求数
当然这种指标更方便观察系统的内部错误,对于事务回滚这种行为,并不能认为是失败的请求。这是和业务行为及事务语义相关的。
长稳
上面提及SLA,也提到了,其实在传统领域,不止可服务时间受人关注,服务质量指标(SLO)同样受人关注。
大家都知道木桶原理,数据库做为基础软件,既是吞吐没有下降,一时的性能抖动可能导致业务软件的性能大幅下降。
衡量数据库服务质量通常有几个指标:
- 吞吐量,对于数据库系统,一般是qps,或者tps;
- 时延,关于时延,一般有如下几个指标, 平均时延,95%时延,99%时延,最大时延;
- 回滚率
制定合理的高可用目标
不客气的说,对于绝大部分系统,在正常故障下,2个9到3个9已经足够用了,不考虑系统变更,这也是一个很容易达到的指标。
而提升一个9,系统设计和实现的复杂度都要提升很多,所得未必偿所失。
打个比方,我们看到阿里rds的SLA是99.95%,而且是按月结算的,那么每个月允许的故障时间大概是4min,加上1min的不计时间,算5min,严格来说,这5min包含故障发现和故障处理。可以想像,如果是人来处理,5min都未必能及时登录到系统上。必然是全自动的故障处理,这个要求对系统的自动化故障处理能力的要求就非常高了。很多大型互联网公司也未必有这个开发能力,当然,也没有这个必要。
不过只要不发生大规模的故障,赔100倍的时间,对阿里也不算什么。不按客户损失赔偿,都是玩笑罢了。
参考资料
- 《SRE: google运维解密》
- 来自 Google 的高可用架构理念与实践
- 关于SLA,你到底知多少?
- 云服务器(ECS)服务等级协议(SLA)
- 腾讯云服务SLA
- 《the tail at scale》
广告
最后,打个广告,如果对创业,分布式数据库和开源社区感兴趣,欢迎加入pingcap,实习和工作都很欢迎!
Email: [email protected]
微信: fbisland
pingcap是国内为数不多的newsql方向的分布式数据库,维护国内最顶级的开源社区,关注度近万,目前已在腾讯云和ucloud上线,做类f1+spanner架构,和多家公司有合作关系。
TiDB: https://github.com/pingcap/tidb
TiKV: https://github.com/pingcap/tikv