练习:
1. 统计用户所有微博被转发的总次数,并输出TOP-3 用户
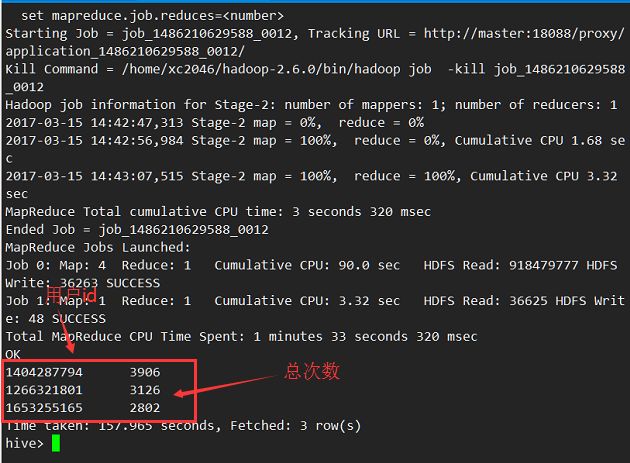
hive> select t.userId,count(*) count from
(select get_json_object(w.json,'$.beForwardWeiboId') beForwardWeiboId,get_json_object(w.json,'$.userId') userId from
(select substring(json,2,length(json)-2) as json from weibo) w) t
where t.beForwardWeiboId !='' group by t.userId order by `count` desc limit 3;
说明:
get_json_object :函数可将json解析成对象,get_json_object函数第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用 . 或 [] 读取对象或数组;
substring(json,2,length(json)-2) as json *** :是将前两个字符和最后两个字符*去掉。数据格式是:
[{"beCommentWeiboId":"","beForwardWeiboId":"","catchTime":"1387159495","commentCount":"1419","content":"分享图片","createTime":"1386981067","info1":"","info2":"","info3":"","mlevel":"","musicurl":[],"pic_list":["http://ww3.sinaimg.cn/thumbnail/40d61044jw1ebixhnsiknj20qo0qognx.jpg"],"praiseCount":"5265","reportCount":"1285","source":"iPad客户端","userId":"1087770692","videourl":[],"weiboId":"3655325888057474","weiboUrl":"http://weibo.com/1087770692/AndhixO7g"}]
结果:
结果
2. 统计每个用户的发送微博总数,并存储到临时表
- 先建立临时表user_count
CREATE TABLE user_count (
userId STRING,
`count` INT
);
- 插入数据
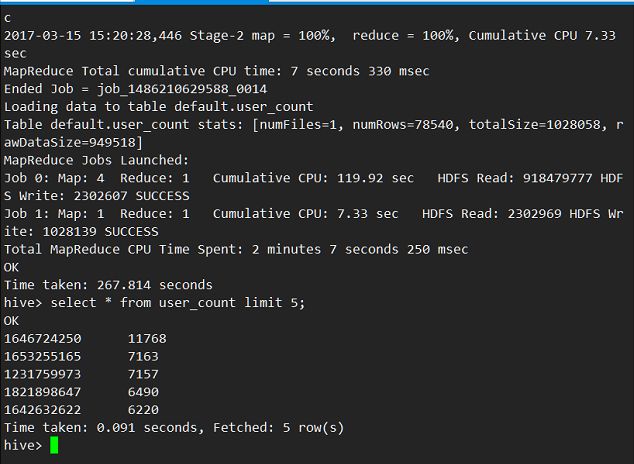
insert into table user_count
select userId,count(distinct(weiboId)) `count` from
(select get_json_object(w.json,'$.userId') userId,get_json_object(w.json,'$.weiboId') weiboId from
(select subString(json,2,length(json)-2) as json from weibo) w) w1 group by userId order by `count` desc
- 去临时表user_count查询前5条,查看是否插入成功
结果:
结果
通过自定义udf来执行HQL
Q:将微博的点赞人数与转发人数相加求和,并将相加之和降序排列,取前 10
- 自定义udf函数代码
package udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public final class addCount extends UDF {
public long evaluate(final Double column1, final Double column2) {
if (column1 != null && column2 != null) {
Double result = column1 + column2;
return result.longValue();
}
if(column1 == null && column2 != null){
return column2.longValue();
}
if(column2 == null && column1 != null){
return column1.longValue();
} else {
return 0;
}
}
}
- 生成jar文件:
** 1.**
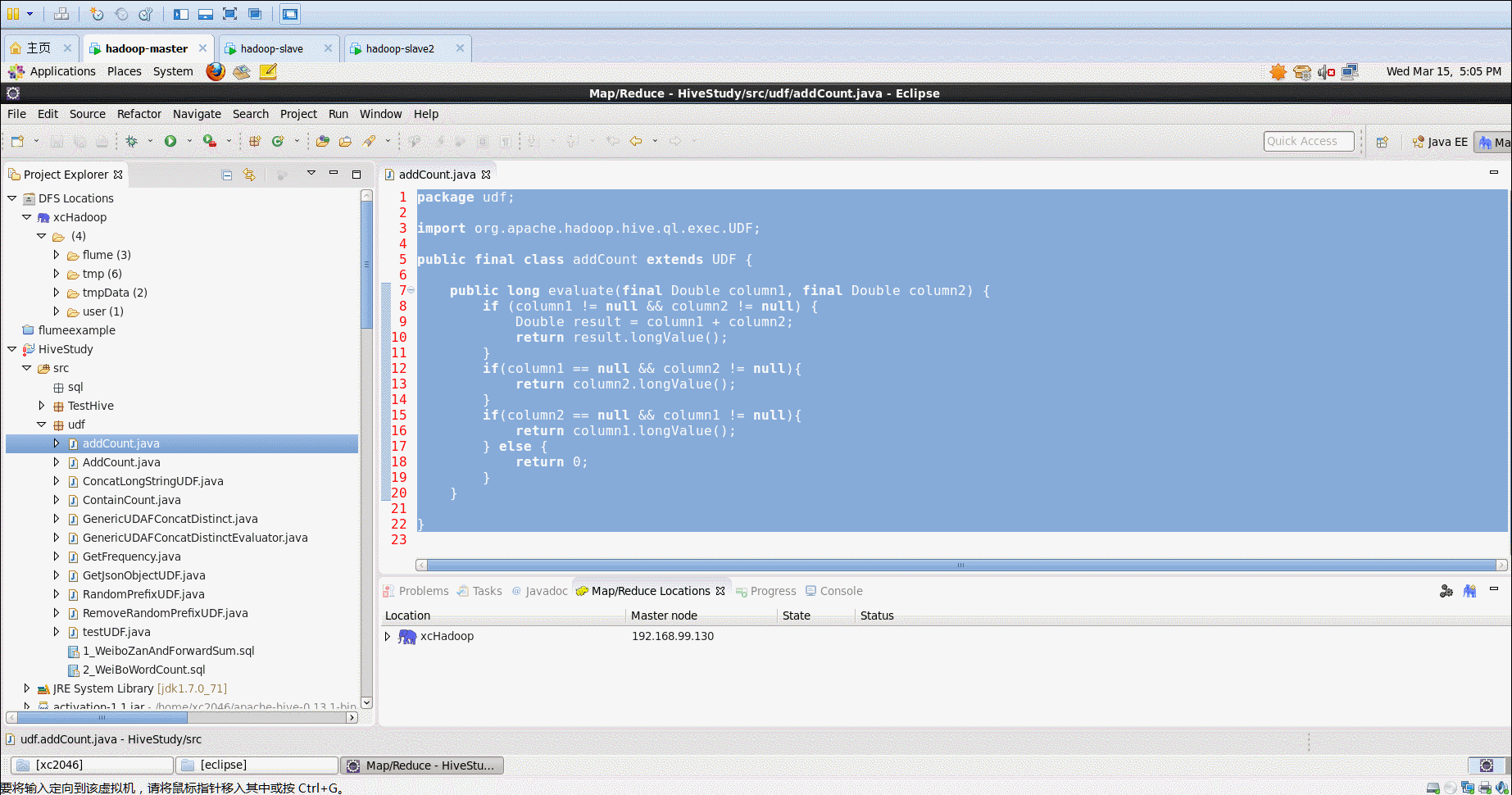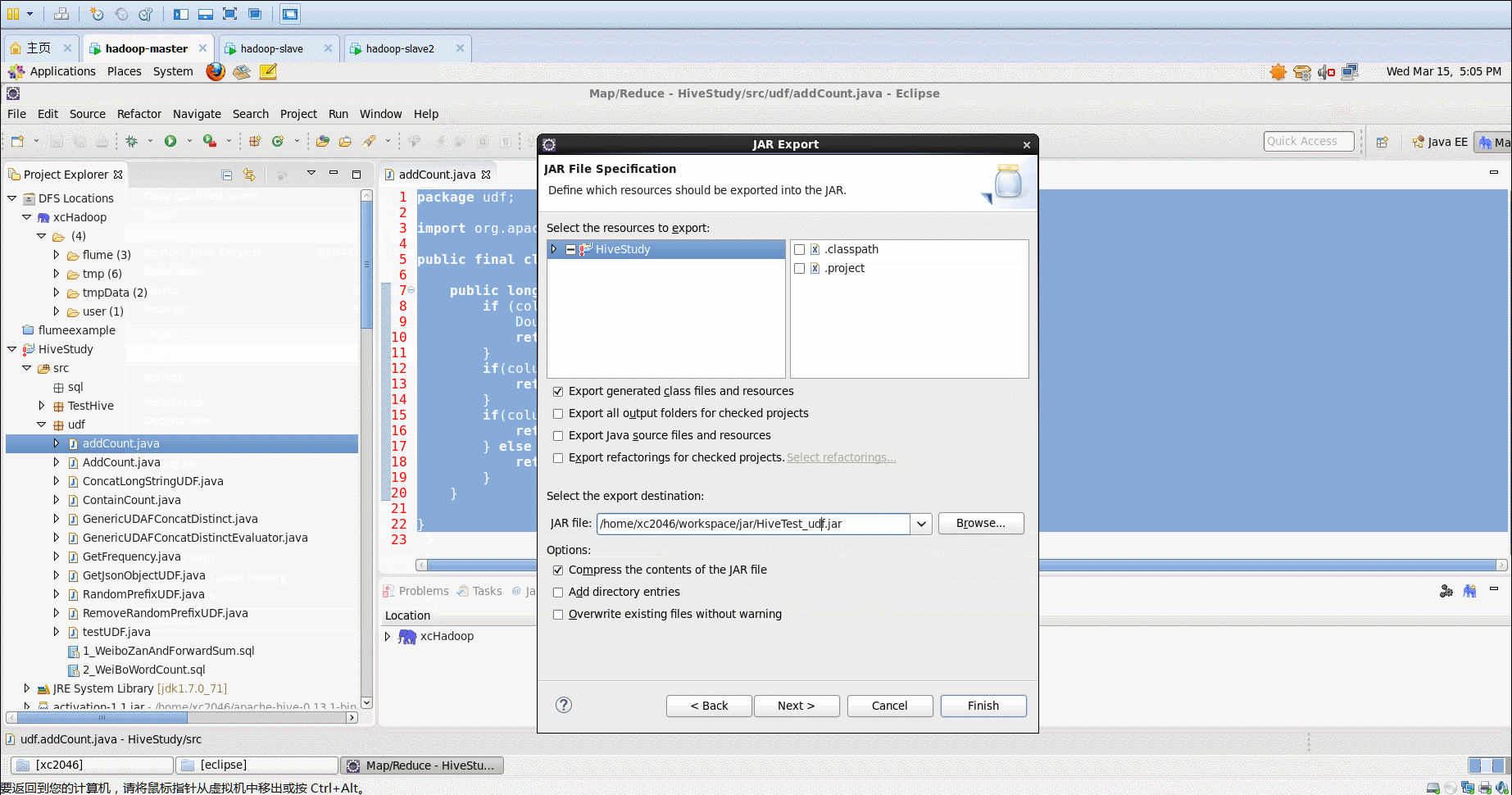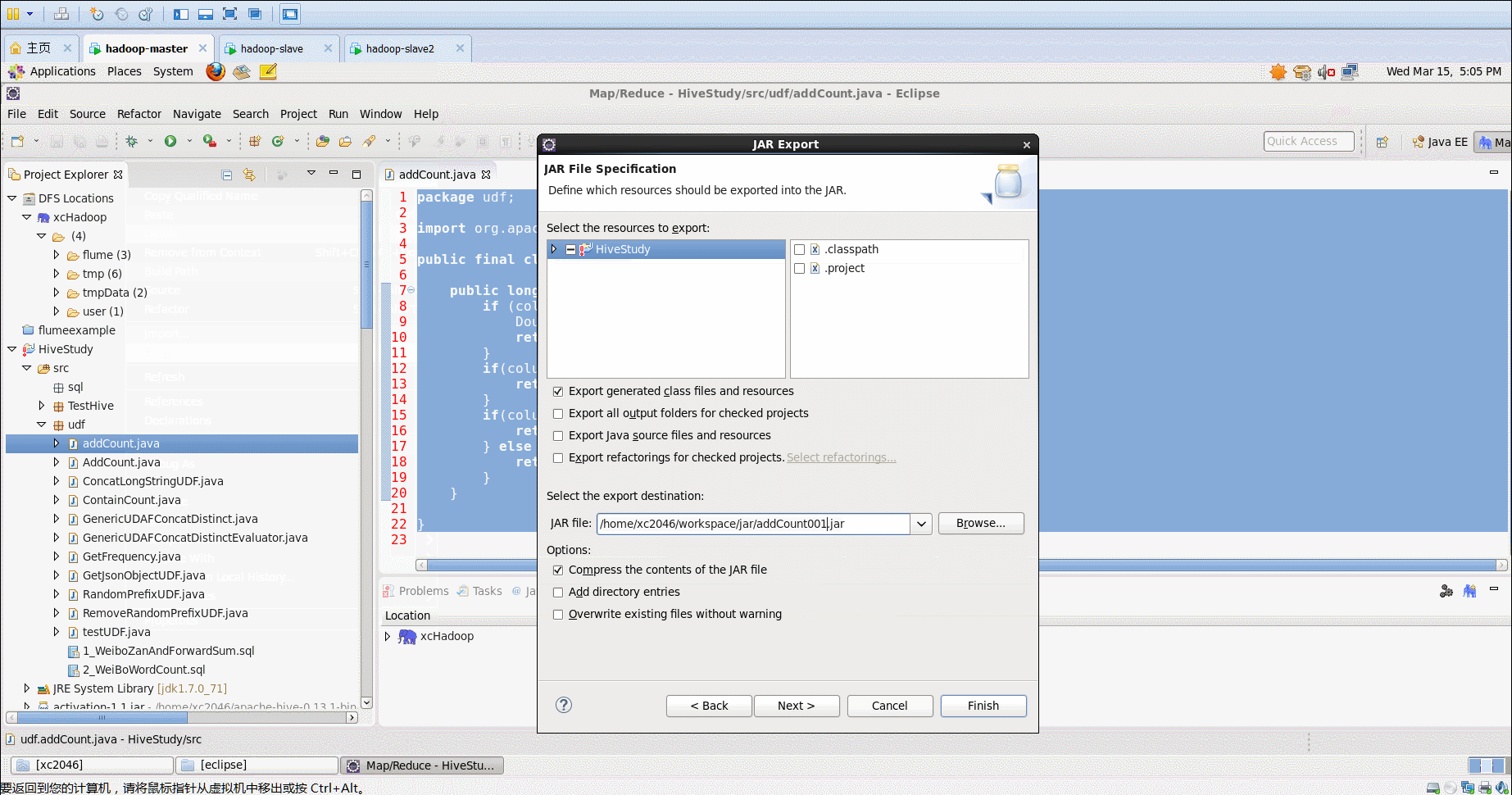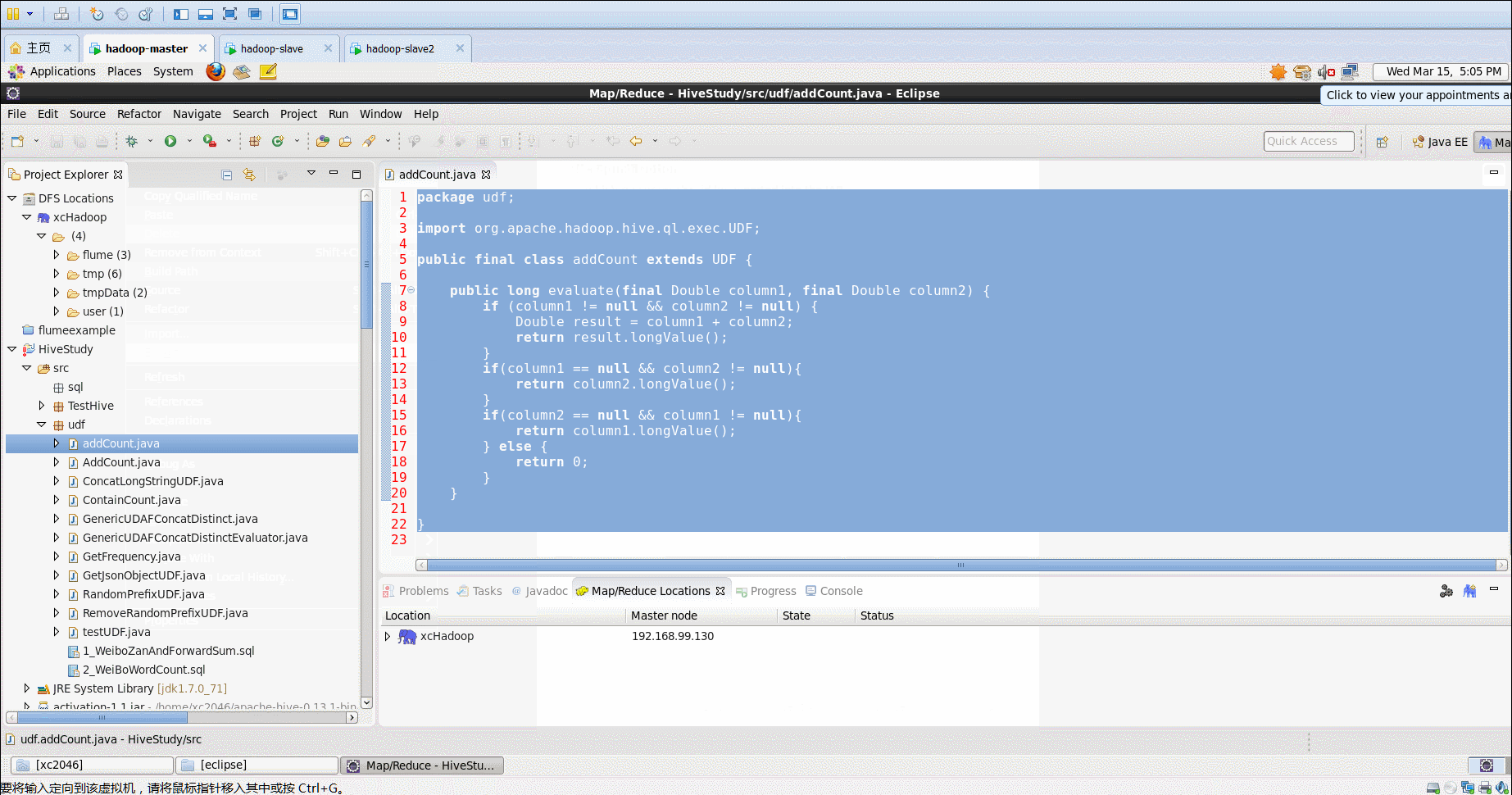
eclipse下将udf函数打包
** 2.**

在linux中找到刚刚打好的jar包
- 执行hql语句
引入udf的jar:
hive> add jar /home/xc2046/workspace/jar/addCount001.jar;
Added /home/xc2046/workspace/jar/addCount001.jar to class path
Added resource: /home/xc2046/workspace/jar/addCount001.jar
创建临时udf函数:
hive> create temporary function addcount as 'udf.addCount';
OK
Time taken: 0.048 seconds
执行带有自定义udf的查询hql:
hive> SELECT weiboId,addcount(SUM(praiseCount),SUM(reportCount)) `count` FROM(
SELECT
get_json_object(w.json,'$.weiboId') weiboId,
get_json_object(w.json,'$.praiseCount') praiseCount,
get_json_object(w.json,'$.reportCount') reportCount
FROM (SELECT SUBSTRING(json,2,LENGTH(json)-2) AS json FROM weibo) w
)w1 GROUP BY weiboId ORDER BY `count` DESC LIMIT 10;
- 最终结果:
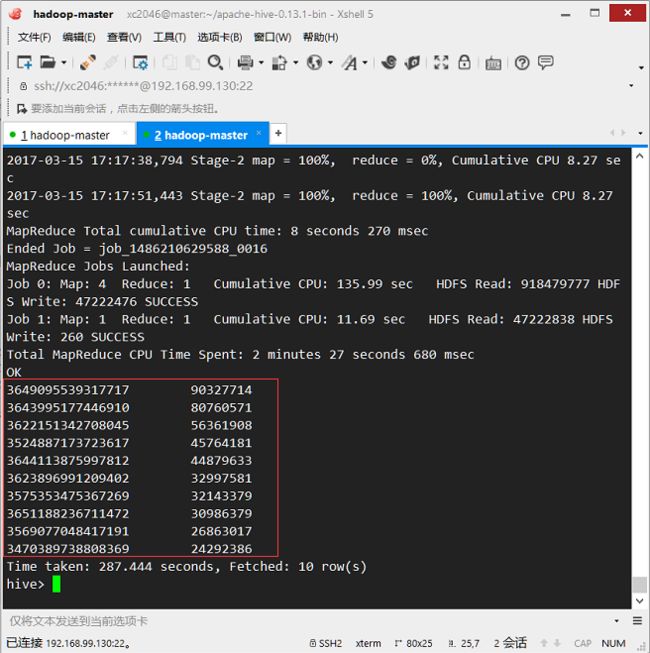
Paste_Image.png