冲突的普遍性 ⎯ ⎯ 生日悖论
我们可以考虑这样一个实际问题:某课堂上的所有学生中,是否由某两位在同一天过生日(称作生日巧合)?
不妨将一年当作一个容量为 365 的桶数组,以生日作为关键码将所有学生组织为一个散列表。于是,上述关于生日巧合的问题就可以严格地转化并表述为:
对于这样的散列表,关键码之间至少发生一次冲突的可能性有多大呢?我们将 n 个学生在场时对应的这一概率记作 P 365 (n)。
- 若学生总数 n > 365,则根据鸽巢原理,冲突将注定出现,即 P 365 (n) = 100%。
- 对于 n ≤ 365,运用排列组合的知识不难证明:
P 365 (n) = 1 -365!/((365-n)! × 365 n)
这一概率与我们的知觉相差很大。实际上,哪怕只有 23 个学生在场,你也值得打赌认定存在生日的巧合⎯ ⎯因为 ** P 365 (23) = 50.7%。**
随着学生的增多,这一概率会急剧上升。
解决冲突
由上面的分析可知,冲突是普遍存在的,我们可以设法降低冲突发生的可能性,但最终都无法彻底回避冲突。那么,一旦发生冲突,有什么有效的方法可以解决冲突呢?
(1)分离链(Separate chaining)
解决冲突最直截了当的一种办法,就是将所有相互冲突的条目组成一个(小规模的)映射结构,存放在它们共同对应的桶单元中。
也就是说,桶单元 A [ i ] 对应于映射结构 ** M ** * i * ,其中存放所有满足h(key) = i 的条目(key, value)。
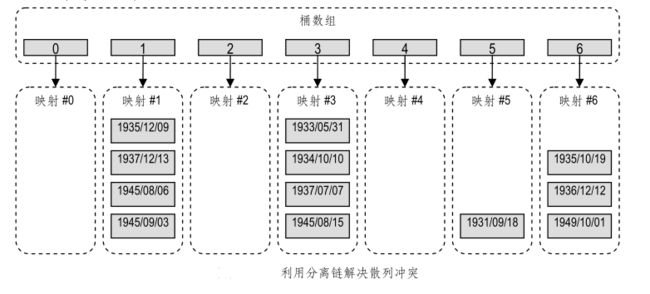
按照这一思路,针对关键码key的任何操作,都将转化为对一个与之相对应的映射结构 M h(key) 的操作。比如put(key, value)操作,将首先在 M h(key) 中查找关键码等于key的条目。若存在这样的条目,则将其中的数据对象替换为value;否则,生成一个新条目(key, value),并将其插入 M h(key) 中。get(key)操作和remove(key)操作的过程也与此类似,都要首先在 M h(key) 中查找关键码key。
实际上,既然好的散列函数能够将所有关键码尽可能均匀地分布到桶数组的各个单元,所以通常 M h(key) 的规模的确都不大,其中相当多的桶中只含有单个条目,有些甚至是空的。
因此,完全可以直接通过链表结构来实现每个** M ** * i * ⎯ ⎯这种解决冲突的策略也由此得名。
(2)冲突池(Collision pool)
解决冲突的另一种办法,就是在散列表 A [ ] 之外另设一个映射结构P,一旦(在插入条目时)发生冲突,就将冲突的条目存入P中。从效果来看,这相当于将所有冲突的条目存入一个缓冲池,该方法也因此得名。
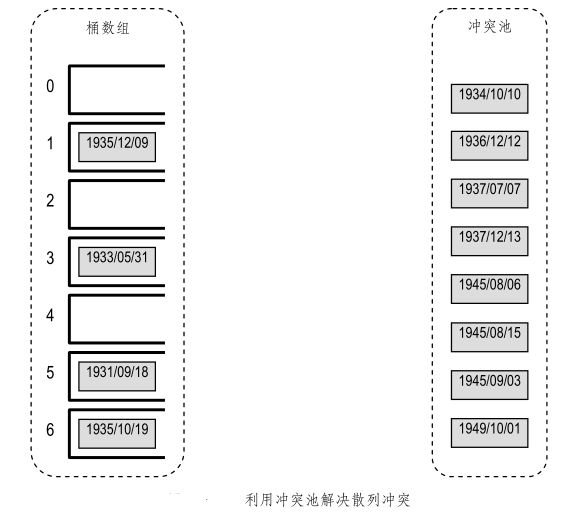
为此,get(key)、put(key, value)和 remove(key)操作中的查找算法都需做相应的调整:
- 如果桶单元 A[h(key)]为空且不带记号,则报告“查找失败”;否则,若该桶中存放的不是所需的条目,则转到 P 中继续查找。
remove(key)算法也需做相应的调整:
- 如果找不到待删除的条目,则操作可以立即完成;若在冲突池 P 中找到该条目,则可利用映射结构 ADT 提供的操作来实施删除;若待删除条目出现在散列表的桶 A[h(key)]中,则不仅需要删除该条目,还要继续给该桶做个标记⎯⎯否则,在冲突池中与 key冲突的那些关键码都将会“丢失”掉。
冲突池法的构思简单,易于实现,在冲突不甚频繁的场合,仍不失为一种较好的选择。
其实,由于冲突池本身也是一个映射结构,故这种结构也可以理解为散列表的递归形式。
(3)开放定址(Open addressing)
分离链策略可以非常便捷地实现映射结构的各种操作算法,但也不是尽善尽美。比如,就数据结构本身而论,这一策略需要借助列表作为附加结构,将相互冲突的条目分组存放。这不仅会增加代码出错的可能,而且也需要占用更多的空间。
在这类情况下,我们只能在不借助附加结构的条件下解决散列的冲突。开放定址就是这样一种策略,实际上,由这一策略可以导出一系列的
变型,比如线性探测法、平方探测法以及双散列法等等。由于不能使用附加空间,所以开放定址策略要求装填因子λ ≤ 1,通常都要保证λ ≤ 0.5。
** 线性探测(Linear probing)**
采用开放定址策略,最简单的一种形式就是线性探测法。
也就是说,在执行 put(key, value )操作时,倘若发现桶单元 A[h(key)]已经被占用,则转而尝试桶单元 A[h(key)+1]。要是 A[h(key)+1]也被占用了,就继续尝试 A[h(key)+2]。如果还有冲突,则继续尝试 A[h(key)+3]。如此不断地进行尝试,直到发现一个可以利用的桶单元。当然,为了保证桶地址的合法性,第 i 次尝试的桶单元应该为:
A[(h(key)+i) mod N],i = 1, 2, 3, …。
按照这种办法,被尝试的桶单元地址构成一个线性等差数列,故由此得名。
相应地,get(key)和 remove(key)操作中的查找算法也需要有所调整。此时,若首次对 A[h(key)]的查找失败,并不意味着关键码 key 未在映射中出现。实际上,我们还需要依次扫描 A[h(key)]后续的各个桶单元 A[h(key)+1]、A[h(key)+2]、A[h(key)+3]、…,直到发现关键码为 key 的条目(查找成功),或者到达一个空桶(查找失败)。
若 H 是基于线性探测法实现的,则对于任一条目 e ∈ C i ,e 的 查找前驱桶单元均非空。
只有如此,才能保证线性探测式查找的顺利进行,因此也称之为线性探测法的“桶地址连续条件”。
这一条件不仅需要在各种操作进行之前得到满足,而且在每一操作完成之后也应继续保持,以便进行后续的操作。不难看出,对于 get(key)和 put(key, value)操作而言,这一点都不成问题。
然而,对于remove(key)操作,在每次将目标条目 e 移除之后,还需要将以 e 为查找前驱单元的所有条目依次前移一个单元,填补删除 e 后留出的空桶,以保持查找前驱桶非空条件。不过,这一解决办法无疑会增加 remove(key)操作的时间复杂度。
在强调删除效率的场合,可以采用另一种变通的解决办法,以避免大量条目的移动。每次移除条目 e 之后,可以为 e 原先占用的空桶做个特殊的记号。如此一来,查找算法只需稍做修改:每次遇到标有这种记号的桶单元,都直接转向后继。另外,put(key, value)操作中的查找算法也需要有所改动:在查找的过程中,需要记录下最靠前的带有记号的桶单元⎯⎯若最终查找失败,则将新条目存放到其中。
尽管线性探测法可以节约空间,但各操作的相应实现却要复杂得多。
线性探测法的最大缺陷在于,基于这一策略的散列表中往往会存在大量的条目堆积(Clustering)。实际上,因为不能使用任何附加的空间,所以线性探测法每解决一次冲突都必然占用一个空桶,于是未来发生冲突的可能性也随之增加。
实验统计表明,在一般情况下条目堆积现象也很普遍,当装填因子超过 0.5 时,这一问题更为突出。
平方探测(Quadratic probing)
平方探测法是对线性探测法的改进。具体来说,就是在发生冲突时,依次对桶单元:
A[(h(key) + j 2 ) mod N], j = 0, 1, 2, …
进行探测,直到发现一个可用的空闲桶。
这一策略可以很好地解决条目堆积的问题。这里充分利用了二次函数的特点,随着冲突次数的增加,其探测的步长将以线性的速度增长,而不是像线性探测法那样始终采用固定步长(=1)。因此,一旦发生冲突,这一办法可以使待插入条目快速地“跳”离条目聚集的区段。
不过,这一方法也存在一些不足。首先,与线性探测法一样,基于平方探测法的 remove(key)操作实现非常复杂。
其次,尽管这一策略可以有效回避条目堆积的现象,但还是会出现所谓的二阶聚集(Secondary clustering)现象⎯⎯条目虽然不会连续地聚集成片,却会在多个(间断的)位置多次“反弹”。
最后,如果散列表容量 N 不是素数,则有可能会出现循环反弹,以至于无法插入的情况。即使 N 选为素数,也必须保证装填因子λ < 0.5,否则即便存在空桶,仍有可能无法找不到插入位置。
双散列(Double hashing)
双散列也是克服条目堆积现象的一种有效办法。为此我们需要选取一个二级散列函数 g(),一旦在插入 e = (key, value)时发现 A[h(key)]已被占用,则不断尝试:
A[h(key) + j×g(key)],j = 1, 2, …。
显然,对任何关键码 key,函数值 g(key)都不能为零⎯⎯否则就会在“原地踏步”。
通常,若散列表长度为素数 N,则取另一素数 q < N,并取
g(key) = q - (key mod q)
为了尽可能地使关键码均匀分布,可以通过实验统计确定最佳的 q 值。
综合比较
相比而言,分离链策略的算法简单,但需要耗费更多空间。开放定址策略正好相反,可以尽可能地节省空间,但算法需做较复杂的调整。理论分析和实验统计都表明,就通常的桶数组容量 N 与装填因子λ而言,分离链策略的时间效率要远远高于其它的方法。因此,除非在存储空间非常紧张的场合,我们都建议采用分离链策略解决冲突。