HBase问题诊断 – RegionServer宕机 – 有态度的HBase/Spark/BigData http://hbasefly.com/2016/04/15/hbase-regionserver-crash/
GC时间长最明显的危害是会造成上层业务的阻塞,通过日志也可以看出些许端倪:
//
经过对整个案件的整理分析,一方面再次锻炼了如何通过监控、日志以及源码定位排查问题的功底,另一方面在HBase运维过程中也需要特别关注如下几点:
- Full GC不仅会严重影响上层业务,造成业务读写请求的卡顿。另外还有可能造成与HDFS之间数据请求的各种异常,这种异常严重的时候甚至会导致RegionServer宕机。
- 上文中提到Full GC基本是由于Concurrent Mode Failure造成,这种Full GC场景比较少见,通常可以通过减小 JVM 参数XX:CMSInitiatingOccupancyFraction来避免,这个参数用来设置CMS垃圾回收时机,假如此时设置为60,表示JVM内已使用内存占到总内存的60%的时候就会进行垃圾回收,减少该值可以使得垃圾回收更早进行。
- 一定要严格限制业务层面的流量。一方面需要和业务方交流,由业务方进行限制,另一方面可以探索HBase业务资源隔离的新方案;
本来静谧的晚上,吃着葡萄干看着球赛,何等惬意。可偏偏一条报警短信如闪电一般打破了夜晚的宁静,线上集群一台RS宕了!于是倏地从床上坐起来,看了看监控,瞬间惊呆了:单台机器的读写吞吐量竟然达到了5w ops/sec!RS宕机是因为这么大的写入量造成的?如果真是这样,它是怎么造成的?如果不是这样,那又是什么原因?各种疑问瞬间从脑子里一一闪过,甭管那么多,先把日志备份一份,再把RS拉起来。接下来还是Bug排查老套路:日志、监控和源码三管齐下,来看看到底发生了什么!
案件现场篇
下图是使用监控工具Ganglia对事发RegionServer当时读写吞吐量的监控曲线,从图中可以看出,大约在19点~21点半的时间段内,这台RS的吞吐量都维持了3w ops/sec左右,峰值更是达到了6w ops/sec。之前我们就线上单台RS能够承受的最大读写吞吐量进行过测定,基本也就维持在2w左右,主要是因为网络带宽瓶颈。而在宕机前这台RS的读写吞吐量超出这么多,直觉告诉我RS宕机原因就是它!
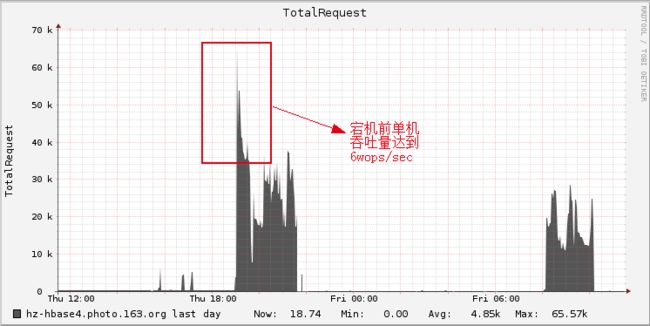
接着就赶紧把日志拉出来看,满屏的responseTooSlow,如下图所示:

很显然,这种异常最大可能原因就是Full GC,果然,经过耐心地排查,可以看到很多如下所示的Full GC日志片段:
2016-04-14 21:27:13,174 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 20542msGC pool 'ParNew' had collection(s): count=1 time=0msGC pool 'ConcurrentMarkSweep' had collection(s): count=2 time=20898ms2016-04-14 21:27:13,174 WARN [regionserver60020.periodicFlusher] util.Sleeper: We slept 20936ms instead of 100ms, this is likely due to a long garbage collecting pause and it's usually bad, see http://hbase.apache.org/book.html#trouble.rs.runtime.zkexpired
可以看出,HBase执行了一次CMS GC,导致整个进程所有线程被挂起了20s。通过对MemStore的监控也可以看出这段时间GC力度之大,如下图所示:
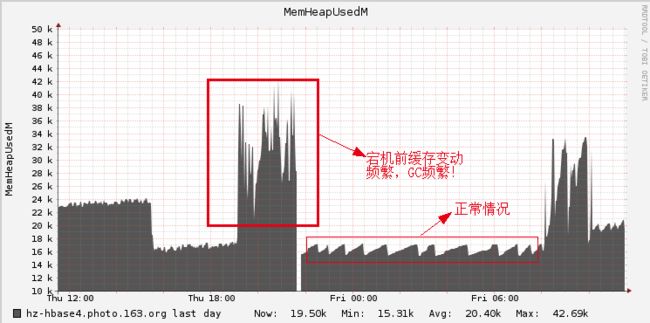
GC时间长最明显的危害是会造成上层业务的阻塞,通过日志也可以看出些许端倪:
java.io.IOException: Connection reset by peer at sun.nio.ch.FileDispatcherImpl.read0(Native Method) at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39) at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) at sun.nio.ch.IOUtil.read(IOUtil.java:197) at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:384) at org.apache.hadoop.hbase.ipc.RpcServer.channelRead(RpcServer.java:2246) at org.apache.hadoop.hbase.ipc.RpcServer$Connection.readAndProcess(RpcServer.java:1496)....2016-04-14 21:32:40,173 WARN [B.DefaultRpcServer.handler=125,queue=5,port=60020] ipc.RpcServer: RpcServer.respondercallId: 7540 service: ClientService methodName: Multi size: 100.2 K connection: 10.160.247.139:56031: output error2016-04-14 21:32:40,173 WARN [B.DefaultRpcServer.handler=125,queue=5,port=60020] ipc.RpcServer: B.DefaultRpcServer.handler=125,queue=5,port=60020: caught a ClosedChannelException, this means that the server was processing a request but the client went away. The error message was: null
上述日志表示HBase服务端因为Full GC导致一直无法响应用户请求,用户客户端程序在一定时间过后就会SocketTimeout并断掉此Connection。连接断掉之后,服务器端就会打印如上日志。然而,这些和我们的终极目标好像并没有太大关系,别忘了我们的目标是找到RS宕机的原因哦!
破案铺垫篇
经过对案件现场的排查,唯一有用的线索就是HBase在宕机前经历了很严重、很频繁的Full GC,从下面日志可以进一步看出,这些Full GC都是在 concurrent mode failure模式下发生的,也就是虚拟机还未执行完本次GC的情况下又来了大量数据导致JVM内存不够,此时虚拟机会将所有用户线程挂起,执行长时间的Full GC!
(concurrent mode failure): 45876255K->21800674K(46137344K), 10.0625300 secs] 48792749K->21800674K(49283072K), [CMS Perm : 43274K->43274K(262144K)], 10.2083040 secs] [Times: user=12.02 sys=0.00, real=10.20 secs]2016-04-14 21:22:43,990 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 10055msGC pool 'ParNew' had collection(s): count=2 time=244msGC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=10062ms
上文提到Full GC会对上层业务产生很严重的影响,那有没有可能会对下层依赖方也产生很大的影响呢?事实是Yes!而且,RS宕机的大部分原因也要归咎于此!
进一步查看日志,发现HBase日志中出现下述异常:
2016-04-14 21:22:44,006 WARN [ResponseProcessor for block BP-632656502-10.160.173.93-1448595094942:blk_1073941840_201226] hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block BP-632656502-10.160.173.93-1448595094942:blk_1073941840_201226
java.io.IOException: Bad response ERROR for block BP-632656502-10.160.173.93-1448595094942:blk_1073941840_201226 from datanode 10.160.173.93:50010at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer$ResponseProcessor.run(DFSOutputStream.java:732)
从日志内容来看应该是hbase调用DFSClient从datanode加载block数据”BP-632656502-10.160.173.93-1448595094942:blk_1073941840_201226″,但是datanode返回失败。具体失败原因需要查看datanode节点日志,如下所示:
2016-04-14 21:22:43,789 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: opWriteBlock BP-632656502-10.160.173.93-1448595094942:blk_1073941840_201226 received exception java.net.SocketTimeoutException: 10000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/10.160.173.94:50010 remote=/10.160.173.94:30110]2016-04-14 21:22:43,779 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: hz-hbase4.photo.163.org:50010:DataXceiver error processing WRITE_BLOCK operation src: /10.160.173.94:30123 dest: /10.160.173.94:50010java.net.SocketTimeoutException: 10000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/10.160.173.94:50010 remote=/10.160.173.94:30123]
很显然,从日志可以看出,datanode一直在等待来自客户端的read请求,但是直至SocketTimeout,请求都没有过来,此时datanode会将该连接断开,导致客户端收到上述”Bad response ERROR ***”的异常。
那这和Full GC有什么关系呢?很简单,就是因为Full GC导致HBase所有内部线程挂起,因此发往datanode的read请求也被挂起了,datanode就等啊等,左等右等都等不到,万不得已才将连接断掉。
查看Hadoop客户端源码可知,如果DFSClient发生上述异常,DFSClient会将一个全局标志errorIndex设为一个非零值。具体可参见DFSOutputStream类中如下代码片段:

破案结局篇
上述铺垫篇最后的结果就是Hadoop客户端会将一个全局标志errorIndex设为一个非零值,那这到底和最终RS宕掉有什么关系呢?来继续往下看。下图HBase日志相关片段截图,记录了比较详细的RS宕机异常信息,我们就以这些异常信息作为切入点进行分析,可以看出至少三条有用的线索,如下图所示:

线索一:RS宕机最直接的原因是因为系统在关闭LogWriter(之后会重新开启一个新的HLog)的时候失败
线索二:执行LogWriter关闭失败的原因是”writing trailer”时发生IOException异常
线索三:而发生IOException异常的原因是”All datanodes *** are bad”
到这里为止,我们能够获得的最靠谱的情报就是RS宕机本质是因为”All datanodes *** are bad”造成的,看字面意思就是这台datanode因为某种原因坏掉了,那我们赶紧去看看datanode的日志,看看那个时间段有没有相关的异常或者错误日志。
然而很遗憾,datanode日志在那个时间点没有打印任何异常或者错误日志,而且显示所有服务都正常,信息如下所示:
2016-04-14 21:32:38,893 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: 127.0.0.1, dest: 127.0.0.1, op: REQUEST_SHORT_CIRCUIT_FDS, blockid: 1073941669, srvID: DS-22834907-10.160.173.94-50010-1448595406972, success: true2016-04-14 21:32:38,894 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: 127.0.0.1, dest: 127.0.0.1, op: REQUEST_SHORT_CIRCUIT_FDS, blockid: 1073941669, srvID: DS-22834907-10.160.173.94-50010-1448595406972, success: true...
看到这里,是不是有点蒙圈:HBase日志里面明明打印说这台datanode坏掉了,但是实际datanode日志显示服务一切正常。这个时候就得翻翻源码了,看看HBase在哪里打印的”All datanodes *** are bad“,通过查看源码,可以看出最终元凶就是上文提到的errorIndex,如下图所示:
终于拨开天日了,再不完结就要晕了!上文铺垫篇铺垫到最后就得出来因为Full GC最终导致DFSClient将一个全局标志errorIndex设为一个非零值,在这里终于碰头了,简直泪流满面!
案件梳理篇
整个流程走下来本人都有点晕晕的,涉及的方方面面太多,因此有必要把整个流程完整的梳理一遍,下面简单画了一个示意图:
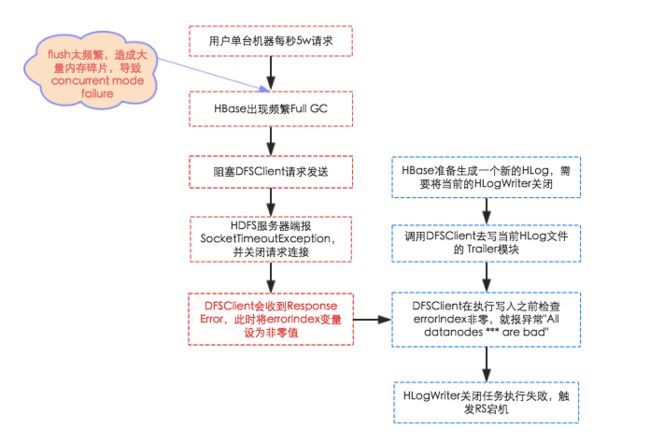
经过对整个案件的整理分析,一方面再次锻炼了如何通过监控、日志以及源码定位排查问题的功底,另一方面在HBase运维过程中也需要特别关注如下几点:
Full GC不仅会严重影响上层业务,造成业务读写请求的卡顿。另外还有可能造成与HDFS之间数据请求的各种异常,这种异常严重的时候甚至会导致RegionServer宕机。
上文中提到Full GC基本是由于Concurrent Mode Failure造成,这种Full GC场景比较少见,通常可以通过减小 JVM 参数XX:CMSInitiatingOccupancyFraction来避免,这个参数用来设置CMS垃圾回收时机,假如此时设置为60,表示JVM内已使用内存占到总内存的60%的时候就会进行垃圾回收,减少该值可以使得垃圾回收更早进行。
一定要严格限制业务层面的流量。一方面需要和业务方交流,由业务方进行限制,另一方面可以探索HBase业务资源隔离的新方案;