姓名:吴琛钧 学号:16010510048
【嵌牛导读】:IEEE发布2017年编程语言排行榜:Python高居首位
【嵌牛鼻子】:Python,爬虫,如何快速上手新语言?
【嵌牛提问】:如何从0开始学习一门语言?
【嵌牛正文】:
作为21世纪的大学生,在这个瞬息万变的时代,各种高级汇编语言陆续出现,作为正在学习的大学生我们应该学会快速的入门一门语言,我们都有学习C语言的基础和经历。对于一门新语言我们应注重语言的应用,通过实际的运用来学习语言的本身。
首先我们我们先安装Python环境
在Windows上安装Python
首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Python 3.5对应的64位安装程序或32位安装程序
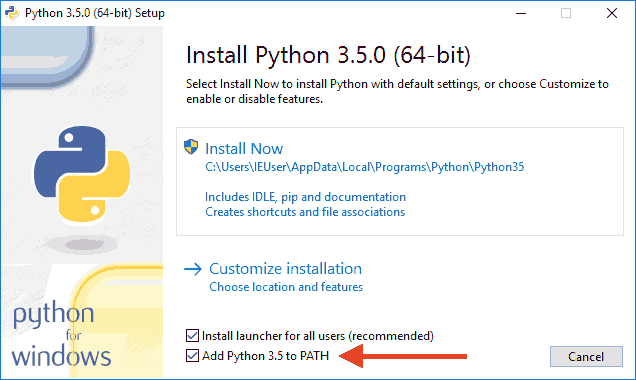
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。这里推荐大家使用pycharm。
一、网络爬虫的定义
网络爬虫,即Web Spider,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页的。
从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,
然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序。
网络爬虫的基本操作是抓取网页。
那么如何才能随心所欲地获得自己想要的页面?
我们先从URL开始。
二、浏览网页的过程
抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。
比如说你在浏览器的地址栏中输入 www.baidu.com 这个地址。
打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。
HTML是一种标记语言,用标签标记内容并加以解析和区分。
浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。