
什么是数据
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,
是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
这里我们来认真的看看数据,什么是数据呢?
多维数据模型是为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型,其基本的应用是为了实现OLAP(Online Analytical Processing)
- 数据立方体(data cube):
我们来看看什么是经典书籍《数据挖掘:概念与技术》的相关介绍:

我想大家都或多或少了解过数据库吧,传统的mysql,postgresql,sql server等。
大家可以想想这个立方体以传统的sql语句建表会是怎么样的呢?
CREATE TABLE `NewTable` (
`id` int(12) NOT NULL AUTO_INCREMENT ,
`address_id` int(12) NULL COMMENT '城市地址的id' ,
`Qtime` enum('4','3','2','1') NULL COMMENT '季度' ,
`item_id` int(5) NULL COMMENT '领域的id' ,
`val` int(10) NULL COMMENT '值' ,
PRIMARY KEY (`id`),
INDEX `address_id` (`address_id`) ,
INDEX `item_id` (`item_id`)
)
;
然后我们还要分别建立城市地址的id和领域的id的表,是不很繁琐~
然而我们如果用mongodb呢?
我们一条语句是不是就是
["address":"温哥华","Qtime":"Q1","item":"安全","val":400]
这是典型的文档存储,一般是json格式
对于这种 data cube还有key-value和xml和列储存
前两者大家肯定接触过,对于列存储我这里已hbase来大概写一下建表语句:
hbase(main):001:0>create 'address-value','Qtime','item',{VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>'ROW',COMPRESSION=>'SNAPPY'}
hbase(main):002:0>put 'address-value','温哥华','Qtime:','Q1'
hbase(main):003:0>put 'address-value','温哥华','item:safe','400'
hbase(main):004:0>put 'address-value','温哥华','item:phone','14'
这个图只展示了基本的两种OLAP操作还有其他操作有时间大家研究下
- 上卷(roll-up):汇总数据
通过一个维的概念分层向上攀升或者通过维规约 - 下钻(drill-down):上卷的逆操作
由不太详细的数据到更详细的数据,可以通过沿维的概念分层向下或引入新的维来实现
上卷和下钻如图所示。 - 切片和切块(slice and dice)
投影和选择操作 - 转轴(pivot)
立方体的重定位,可视化,或将一个3维立方体转化为一个2维平面序列 - 钻过(drill_across):执行涉及多个事实表的查询
- 钻透(drill_through):钻到数据立方体的底层,到后端关系表
标准的sql语句是入门大数据的必修课,好多常用的架构也是以sql作为主的,比如hive
可能有点夸张,对于一个sql的掌握的熟练程度决定于我们的起薪,但sql的确重要,这里分享一个sql语句的执行顺序
sql的执行顺序:
(8)SELECT(9)DISTINCT(11)
(1)FROM[left_table]
(3)
(2)ON
(4)WHERE
(5)GROUP BY
(6)WITH
(7)HAVING
(10)ORDER BY
具体的大数据工具选择
这里我们要做的事就是所有刚入职的大数据rd为之奋斗的ETL
ETL(ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程)
恩,刚才我们提到hive,我们先说说这个
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
hive -e "select * from XXX "这样一句sql,在后端转换为MR程序,使用起来极为方便的
对于具体的架构选择其实选择很多,spark,hadoop等(后面进阶的还有storm等)
这里我们来实现下hello,world级的程序Wordcount,就是统计一个文件中的单词数,十分经典,我们用py,mapreduce,spark来分别实现。
- py
# -*- coding: utf-8 -*-
import sys
import os
from collections import Counter
from hdfs.hfile import Hfile
hfile = Hfile(hostname, port, path, mode='r')
try:
all_the_text = hfile.read()
finally:
exit(1)
count = Counter(word.lower()
for line in all_the_text
for word in line.strip().split()
if word)
for word,count in count.items():
sys.stdout.write(word)
sys.stdout.write("\t")
sys.stdout.write(str(count))
sys.stdout.write("\n")
py处理简单的ETL显得游刃有余,配合supervise和crontab,也可以基本实现各种任务(同理其他脚本语言)
- mapreduce:
import .....
public class WordCount
{
public static class Map extends MapReduceBase implements
Mapper
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector output, Reporter reporter)
throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer
{
public void reduce(Text key, Iterator values,
OutputCollector output, Reporter reporter)
throws IOException
{
int sum = 0;
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception
{
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount"); //设置一个用户定义的job名称
conf.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
conf.setOutputValueClass(IntWritable.class); //为job输出设置value类
conf.setMapperClass(Map.class); //为job设置Mapper类
conf.setCombinerClass(Reduce.class); //为job设置Combiner类
conf.setReducerClass(Reduce.class); //为job设置Reduce类
conf.setInputFormat(TextInputFormat.class); //为map-reduce任务设置InputFormat实现类
conf.setOutputFormat(TextOutputFormat.class); //为map-reduce任务设置OutputFormat实现类
/**
* InputFormat描述map-reduce中对job的输入定义
* setInputPaths():为map-reduce job设置路径数组作为输入列表
* setInputPath():为map-reduce job设置路径数组作为输出列表
*/
FileInputFormat.setInputPaths(conf, hdfs://XXX/XXX);
FileOutputFormat.setOutputPath(conf, new Path(hdfs://XXX/XXX));
JobClient.runJob(conf);
}
}
我在百度实习的时候,Hadoop在百度主要用于如下场景:
- 搜索日志的存储和统计(如百度自身视屏的点击量,阿拉丁的和普通结果的分布);
- 分行业业务的维度聚合和分析;
- 用户网页的聚类,分析用户的推荐度及用户之间的关联度。
大家总说spark是未来,但百度还是以hadoop为主,说明hadoop还是有一定的市场
hadoop适用于
数据密集型并行计算:数据量极大,但是计算相对简单的并行处理
如:大规模Web信息搜索
计算密集型并行计算:数据量相对不是很大,但是计算较为复杂的并行计算
如:3-D建模与渲染,气象预报,科学计算
但hadoop不适用于流式数据的计算,也不适用于小而重复的数据(需要状态缓存等)
- spark
spark:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
//载入sparkconf
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val inputFile = "hdfs://XXX/XXX"
val textFile = sc.textFile(inputFile)
//读取文件
val result = textFile.flatMap(line => line.split(",")).map(word => (word,1)).reduceByKey(_+_)
result.collect().foreach(println)
sc.stop()
}
}
可以看到我们的spark的代码十分简单。由于scala是函数试编程的语言(当然也是OOP的),
saprk的核心是rdd,可以说所有的操作都基于rdd(Resilient Distributed Datasets,弹性分布式数据集)分为transformations 和 actions两类操作
当用户对一个RDD执行action(如count 或save)操作时, 调度器会根据该RDD的lineage,来构建一个由若干阶段(stage) 组成的一个DAG(有向无环图)以执行程序

在配着spark强大的模块,如spark sql,spark streaming,MLlib,graphX等,spark如虎添翼
大家有兴趣想真正了解spark,我这有个pdf,讲的十分详细,也比较适合入门,下来记得向我要哈
可以看到一个需求是有很多种解决方案的呢,那么我们接到一个需求我们应该怎样选择一个合适的架构来实现呢?
这个讲起来太复杂,我推荐两篇文章
http://blog.csdn.net/poisions/article/details/51120172
http://developer.51cto.com/art/201601/504722.htm
我这里再介绍下ELK:
- ELK:
E:Elasticsearch是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析,java语言编写
L:Logstash 是一个具有实时渠道能力的数据收集引擎。使用 Ruby 语言编写
K:Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写,为 Elasticsearch 提供分析和可视化的 Web 平台
大家可以看看我的另一篇blog,这是我简单在自己PC上搭建的,开箱即用,搭建十分简单,目前这个美团酒店,机票监控,360手游大厅监控,stackoverflow基础服务监控,facebook等中外公司监控都在使用哦
我再推荐自然语言处理最基本的分词工具
对于中文的分词,我还是推荐py的jieba
- 模式多,全模式,精确模式,搜索引擎模式,新词模式
- 添加自定义词典
- 词性标注
- 并行分词
- 等等。。
当然分布式的架构还原不止这些,我们要做的就是找符合公司,业务需求的就好~
机器学习
下面我们进行一个比较烧脑的话题,机器学习,深度学习,神经网络(主要介绍机器学习)这个现在是互联网后半场的灵魂所在,好不夸张的说这是互联网的核心竞争力,这个我也是摸着石头过河,各位我们一起讨论下,作为学弟学妹,你们的概率论,线性代数,高等数学一定比我好的多,恭喜你们成功了一半
那个我们来看个大家最关心的东西:
https://m.lagou.com/jobs/2805052.html
这个是腾讯OMG的spark工程师招聘,我们看看这段话
精通Scala语言,对Scala原理、底层技术有深入研究者优先; 有MLlib/mahout开发经验者优先; 熟悉聚类、分类、回归,LR,SVM等机器学习算法者优先
这里的聚类、分类、回归,LR,SVM都是机器学习的不同分类
为什么说这个烧脑呢,我们先讲讲machine learning的基础,最小二乘法,这里基本是数学的世界了,由于实在不好写公式,我们分享一篇文章
http://blog.csdn.net/lotus___/article/details/20546259
这篇文章讲的还比较通俗易懂,真心的,这个的确抽象,不过代码是c++,对于ML,我还是极力推荐py(当然spark的MLlib还是要用scala)因为什么呢,py中的scipy和numpy不吹不黑,可以和matlab一战,最小二乘法最简单粗暴的应用就是线性回归曲线的拟合了,下面我给出一段(数据来源高中女生的身高和体重,别问我怎么来的)
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from scipy.optimize import leastsq
from sklearn.linear_model import LinearRegression
from scipy import sparse
import numpy as np
def func(a, x):
k, b = a
return k * x + b
# 残差
def err(a, x, y,s):
print s
return func(a, x) - y
font = FontProperties()
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.figure()
plt.title(u' the girls data ')
plt.xlabel(u'wight')
plt.ylabel(u'height ')
plt.axis([40, 80, 140, 200])
plt.grid(True)
x = np.array([48.0, 57.0, 50.0,54.0, 64.0, 61.0, 43.0, 59.0])
y = np.array([165.0, 165.0,157.0, 170.0, 175.0, 165.0, 155.0, 170.0])
plt.plot(x, y, 'k.')
param = [0, 0]
s = "the number of use function err "
var= leastsq(err, param, args=(x, y,s))
k, b = var[0]
print k, b
plt.plot(x, k*x+b, 'o-')
plt.show()
这段代码安装过import的所有依赖即可直接执行,效果一目了然,这里我给出结果吧
linear_regression.png
这里重点来了(敲黑板~),机器学习的架构,框架很多如
python :sklearn
spark :MLlib
google:TensoFlow等
但这些框架都是高度封装,上面代码就一句话管用
var= leastsq(err, param, args=(x, y,s))
还有一个py代码是不借助sklearn.linear_model import LinearRegression的,感兴趣的记得下来向我要,是我自己摸着石头过河写的~但不一定直观,代码也不优雅。
这是二阶的,往往现实数据都是多阶的,这里我们就要搬出来矩阵了
我们分享一个这个blog,讲的比较好~
http://blog.csdn.net/jairuschan/article/details/7517773/
所以我们要做的绝对不是套框架,而是了解这个模型,理解其中的核心算法和数学原理,这还是很难度的
我们在分享一个朴素贝叶斯的spark MLlib实现,看看概率论的重要性
在我的blog中:
http://www.jianshu.com/p/f73286b2e7f0
还有很多算法,聚类,SVM,决策树等,这里时间关系,等我研究差不多我们再讨论哈~接下来我们补补理论,究竟机器学习是什么
机器学习分为两种
监督学习:
再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,
也就具有了对未知数据进行分类的能力。
在人对事物的认识中,我们从孩子开始就被大人们教授这是鸟啊、那是猫啊、那是房子啊等等。
我们所见到的景物就是输入数据,而大人们对这些景物的判断结果(是房子还是鸟啊)就是相应的输出。
当我们见识多了以后,脑子里就慢慢地得到了一些泛化的模型,这就是训练得到的那个(或者那些)函数,
从而不需要大人在旁边指点的时候,我们也能分辨的出来哪些是房子,哪些是鸟。
而无监督学习:
在于我们事先没有任何训练样本,而需要直接对数据进行建模,
比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,
我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,
什么叫做写实派,但是至少我们能把他们分为两个类)。
还有半监督学习:
半监督学习的基本设置是给定一个来自某未知分布的有标记示例集 L={(x1, y1), (x2, y2), ..., (x|L|,y|L|)}以及一个未标记示例集U = {x1’, x2’, ... , x |U|’},期望学得函数f: X→Y可以准确地对示例x 预测其标记y
无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。
因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了
监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),
如果预测的变量是连续的,我们称其为回归(线性回归,逻辑回归等)
深度学习:
sigmoid函数,
f(z) = 1/1+exp(-z);
这是深度学习的基础。具体让大家头疼数学推导,理论什么的我这里不展开了(关键我也不熟,计算机中深度学习的工资最高,难度也随之上来了)
大家可以参考http://www.cnblogs.com/cherler/p/3604720.html
机器学习能做什么
- 预测一封邮件是否是垃圾邮件
- 预测一笔信用卡交易是否是欺诈行为
- 预测哪种广告最有可能被购物者点击
- 预测哪支球队会赢得NBA大赛总冠军
好多人问机器学习究竟是在公司中如何应用的呢,我说句实话,在刚入职1,2年的阶段,,没用,,但我们慢慢发现有些事情是我们的PM一开始想不到的,比如如何判断一个用户玩游戏是小号刷机还是普通用户,这个是一般的逻辑程序无法判断的,这是机器学习登场的时候了
还有个例子就是Alpha go的围棋奇迹了,它本身并不懂围棋规则,也并没有输入围棋的规则(比如打吃,托退定式等),它做的就是先学习200w份高手棋谱,然后自己和自己对决7000w盘(以上数据是google的一篇对外文章),然后你们说它谁下不过呢~
然后我想给出两个大数据中经典的问题(有的依然待解决)
- 数据倾斜
数据倾斜带来的直接后果就是
1.OOM(内存溢出)
2.运行速度慢,特别慢,非常慢,极端的慢
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜
数据倾斜分为两种
1.一些null 和没有用的数据,直接过滤就行
2.有效数据,业务导致的正常数据分布
- 隔离执行,将异常的key过滤出来单独处理,最后与正常数据的处理结果进行union操作。
- 对key先添加随机值,进行操作后,去掉随机值,再进行一次操作。
- 使用reduceByKey 代替 groupByKey
-
使用map join。
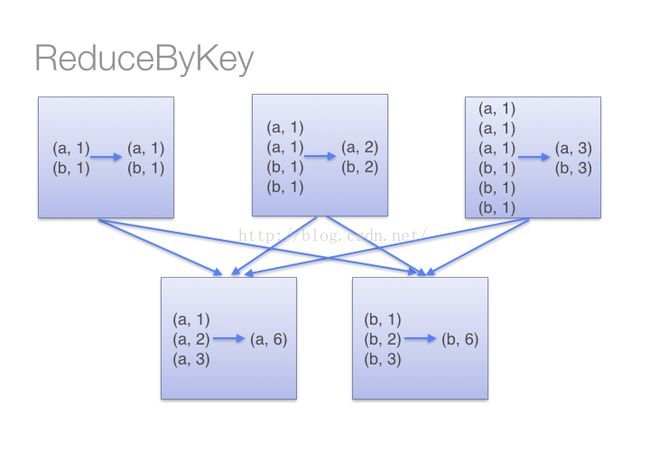

这就看出来groupByKey会导致一个task有过多的相同的key需要处理,因为groupByKey接口不接收自定义函数,所以无法在第一个rdd上做action操作,导致只能全部到下一个stage处理
在机器学习中也存在一个头疼的问题(主要是在深度学习中),梯度消失问题,这个太深了,这里我就不展开说了,有兴趣的同学可以看看这个
http://www.cnblogs.com/tsiangleo/p/6151560.html
然后有兴趣深挖下
这里我再分享下前10大数据挖掘算法
- C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法
- k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均 方误差总和最小。
- SVM(Support Vector Machine)支持向量机
- priori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法
- EM:在统计计算中,最大期望(EM)算法是在概率模型中寻找参数最大似然 估计的算法
- PageRank这里的page不是网页是拉里·佩奇,google的专利算法,具体可以搜一下
- Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)
- K最近邻(KNN算法)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一
- NBC(朴素贝叶斯模型)是一种决策树算法,发源于古典数学理论,对缺失数据不太敏感
- CART: 分类与回归树,在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝
这里好多算法是值得我们好好研究的,说实话这些算法你们要我详细讲解还是力不从心的,留给大家自己研究
这天也不早了,下面说说我在"自学"大数据的心得吧
首先我们给出一个技术栈,我是从PHP起步的,所以我们的root节点是PHP,左边的为找工作或者说是PHP rd的基本素养,右边为不同方向的拓展
由于本人是从PHPrd(rd即研发)起步,所以py,java等后端语言同理
http://naotu.baidu.com/file/b6dad81eac8e0856ac251cf482b2a38e?token=04e85fa9c42d0ae8
大数据我自己把它分为两种,ETL和Machine Learning
前者我推荐大家的学习方法是,搞个spark,hadoop(伪分布式)懒得话,里面有demo程序,勤快的话多看看别人blog,这里书没什么用。