
内容来源:2017年6月10日,华为电信软件业务云运维开发部软件工程师肖曙旭在“Elastic Meetup 南京”进行《Elastic在华为电信软件运维中的应用简介》演讲分享。IT 大咖说(ID:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:1966 | 4分钟阅读
获取嘉宾演讲视频回放及ppt,请点击:http://t.cn/RkvHOAN

摘要
1. 日志采集代理。提供按正则表达式匹配或者分隔符的逻辑行分割方式;支持逻辑行内按分隔符提取字段,或者按正则表达式提取字段;支持一些简易算子对字段进行处理。
2. 日志汇聚。不同的日志类型通过不同的Topic区分。
3. 流式处理。日志数据二次处理,或者一些实时分析的逻辑处理。
4. 参考kibana开发搜索和可视化能力,同时支持关键词告警,环比告警等告警能力,以及整个日志服务通道的自身监控能力。
系统架构概述
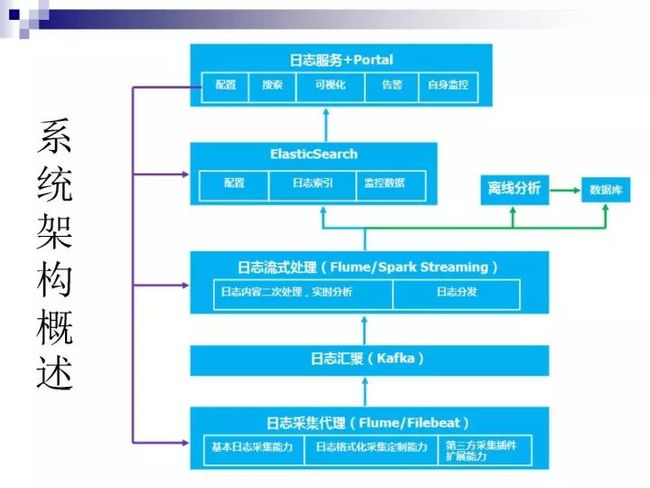
上图是我们的基础架构情况。最底层结合电信场景就是业务的节点,在业务节点上面会布一个采集代理,我们目前用的是Flume,因为资源和其它的一些关系,现在正在切换为Filebeat。
日志采集代理的基本日志采集能力、日志格式化采集定制能力和第三方采集插件扩展能力都是基于Flume来写的。
日志汇聚用的是kafka。
流式处理目前使用的是Flume和Spark Streaming这两者共存,但它们应用于不同的场景。简单的日志采集用的是Flume,需要做一些实时分析的则用Spark Streaming,分析完之后的数据写入数据库。
把数据发送到ElasticSearch分为配置、日志索引和监控数据。配置主要是把要采集什么日志、采集几种日志、如何采集等存入ElasticSearch。日志索引就是正常的日志数据。监控数据是我们做了一个采集通道的监控,在采集端和监控的流式数据端都会有监控的API报到ElasticSearch里,Portal会查监控的API去了解当前采集通道的状况。
日志采集格式化定制
日志采集代理使用Flume实现,通过Flume的Source和Sink的定制能力实现日志采集格式化定制。
支持采集目录,文件的黑白名单;支持正则表达式或者分隔符匹配逻辑行,且支持逻辑行的黑白名单;可以按分隔符或者正则表达式将逻辑行分割为格式化字段列表;还可以直接使用正则表达式从日志中提取字符串作为独立字段;支持一些简易的算子对字段做初步处理,比如数值运算、字段串截取等。
日志采集监控
依赖Flume自身的metric数据,定制计算逻辑,获取我们需要的信息,比如每条通道采集的日志总数,采集速率,数据发送的成功率,异常问题列表等。将这些信息以单独的日志类型通过数据通道入ElasticSearch保存,最终监控微服务定时查询相关索引获取采集状态并在界面呈现。
基于日志的告警
日志中体现了一个系统的运行状态,通过对日志的分析,我们能够了解系统是否正常。当日志中出现一些确定的关键词或者某项指标超出阈值的情况下,我们希望运维能够以告警的方式上报风险。出于上述考虑,并结合ES的搜索能力,我们构建了相关能力:
统计最近一个周期内某个关键词出现的次数,满足一定条件则告警;
统计最近一个周期内某个关键词出现的次数,两者的差异超过阈值设置则告警;
统计最近两个周期内某个数值指标的和/平均值/最大值/最小值,比较两者差异超过阈值则告警。
电信领域应用实例——某省移动BES
业务规模有1000+节点,日志平均5W+条/秒。ES的规模目前是10个节点,每个节点6C56G的虚拟机。
应用场景
故障定界定位:通过界面异常信息,业务节点监控等可以了解问题出现的业务集群甚至节点,以及导致问题的关键词,从业务监控直接下钻到日志搜索,根据相关信息过滤得到错误日志,再结合日志钻取功能获得错误日志的上下文,从而定位出问题根因;
状态监控:通过ES的搜索和聚合能力配置分析图表或者告警,比如配置Nginx平均时延趋势图来监控Nginx响应状态,配置最近5分钟内Nginx的error日志中出现time out的次数超过一定阈值就告警;
统计分析:基于ES的聚合能力针对采集提取的字段进行有效的分析,比如从业务日志中提取错误码字段,配置TopN表格统计出现频率最高的10种错误码;分析调用链日志,统计服务调用延时,找到系统耗时瓶颈等,作为后续系统优化的有效输入。
实践过程中的优化经验(二)
通过设置字段的doc_values属性解决聚合查询容易导致OOM的问题。ES在排序和聚合查询的时候会将fielddata全部写入内存,大量占用heap空间,从而可能引起OOM。将所有不分词的字段(包括数值型字段)的doc_values属性设置成true,该字段的fielddata就会被写入磁盘,从而降低对内存的压力,避免OOM。同时,实测其对检索的影响也不大,相同条件下,检索速度大概慢了10%左右。
检索性能优化。按照时间段创建索引,搜索的时候可以基于时间条件指定范围内的索引名搜索,减少了搜索范围,对搜索性能有一定的提升,同时减小了索引分片的大小,能够防止分片过大导致索引效率降低;
默认按时间排序,禁止相关度分值计算;
使用最新的ES版本。实测相同条件下,所有字段均指定格式的情况下5.X版本比1.X版本的索引性能提升50%左右。
实践过程中的优化经验(三)
使用Beats替代Flume作为采集代理,降低资源占用。Flume的Channel会占用大量的内存,特别是日志类型较多的情况下,需要配置更多的采集通道,会导致内存占用大幅增加。使用Elastic Stack中的Beats替代Flume能够大幅降低内存占用。Beats中能够定制Processor,之前在Flume上定制的逻辑基本都可以迁移到processor中。当然使用过程中也遇到一些问题,比如Beats的metric信息没有Flume丰富,也无法针对不同的日志类型区分,集成的Kafka Output默认不支持kerberos鉴权等,需要自己定制开发。
我今天的分享就到这里,谢谢大家!