BlockBasedTable
RocksDB用SST文件(Sorted Sequence Table)来存储用户写入的数据. 文件中key是排好序的, 所以对key的查找操作可以用二分查找完成.
BlockBasedTable是SST文件的默认格式.
SST文件结构
[data block 1]
[data block 2]
...
[data block N]
[meta block 1: filter block] (see section: "filter" Meta Block)
[meta block 2: stats block] (see section: "properties" Meta Block)
[meta block 3: compression dictionary block] (see section: "compression dictionary" Meta Block)
...
[meta block K: future extended block] (we may add more meta blocks in the future)
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
- SST文件的开头是key/value对按序排列, 分配在连续的block中.默认的block大小为4k.
- 在data block后面是一些meta block.
- meta index block记录了每个meta block的偏移和长度. key是meta block的名字, value的类型是 BlockHandle, 其定义如下
class BlockHandle {
public:
BlockHandle();
BlockHandle(uint64_t offset, uint64_t size);
...
private:
uint64_t offset_;
uint64_t size_;
}
- index block记录了每个data block的索引. key是一个string, 它的值大于或等于被索引的block的最后一个key, 小于下一个data block的第一个key.
value是data block对应的BlockHandle. - 文件的末尾写入了一个固定长度的footer,其格式如下
metaindex_handle: char[p]; // Block handle for metaindex
index_handle: char[q]; // Block handle for index
padding: char[40-p-q]; // zeroed bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // 0x88e241b785f4cff7 (little-endian)
类结构分析
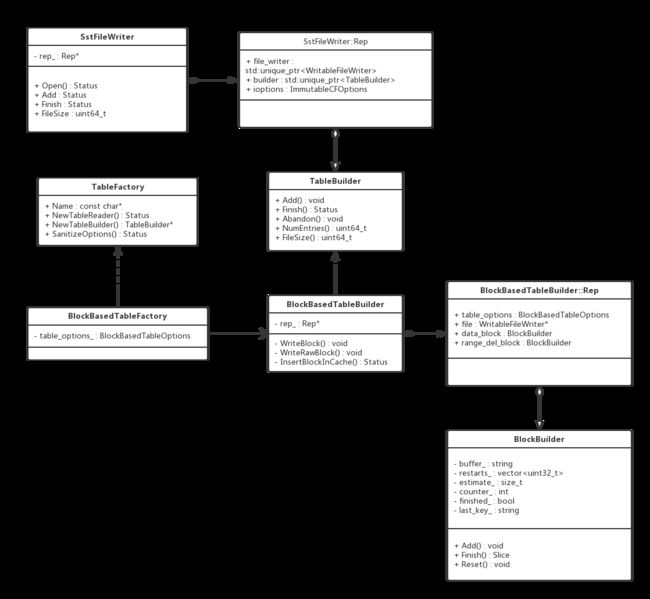
类职责说明
- TableBuilder
可以认为, 一个Table就是一个SST文件, 只不过Table并不会把整个SST文件的内容持有, 而是当写满一个block, 就会flush到SST文件中.
TableBuilder就定义了构建一个Table(SST File)的结构, 主要是Add接口, 接收调用者传进来的kv. Finish接口在数据写完之后, 将后续的meta block, index block等写入在data block后面. - BlockBasedTableBuilder
实现了TableBuilder接口. 并定义了如何写下block的方法, 同时实现了将block插入到压缩cache中的私有方法. - TableFactory
工厂类接口, 用来创建指定的TableReader和TableBuilder对象. - BlockBasedTableFactory
创建BlockBasedTableReader和BlockBasedTableBuilder. - BlockBuilder
用来构造Block的对象, 可复用. 当一个block构造完成, flush到sst文件中, 九调用Reset方法, 清空buffer和成员变量, 继续构造下一个Block.
类图中, SstFileWriter只是使用TableBuilder的一个调用者, 还有其他依赖TableBuilder的调用这没有画出. 并不是本篇重点介绍的对象.
Block的构造过程分析
用户在打开DB时,传入table相关选项,由table_factory持有。
std::vector cf_descs;
cf_descs.push_back({kDefaultColumnFamilyName, ColumnFamilyOptions()});
// initialize column families options
std::unique_ptr compaction_filter;
compaction_filter.reset(new DummyCompactionFilter());
cf_descs[0].options.table_factory.reset(NewBlockBasedTableFactory(bbt_opts));
cf_descs[0].options.compaction_filter = compaction_filter.get();
s = DB::Open(Options(db_opt, cf_descs[0].options), kDBPath, &db);
assert(s.ok());
NewBlockBasedTableFactory函数,创建一个BlockBasedTableFactory对象
TableFactory* NewBlockBasedTableFactory(
const BlockBasedTableOptions& _table_options) {
return new BlockBasedTableFactory(_table_options);
}
BlockBasedTableFactory实现了TableFactory接口,作为一个工厂类,对用户提供了创建TableReader和TableBuilder等接口。我们以TableBuilder举例。
TableBuilder* BlockBasedTableFactory::NewTableBuilder(
const TableBuilderOptions& table_builder_options, uint32_t column_family_id,
WritableFileWriter* file) const {
auto table_builder = new BlockBasedTableBuilder(
table_builder_options.ioptions, table_options_,
table_builder_options.internal_comparator,
table_builder_options.int_tbl_prop_collector_factories, column_family_id,
file, table_builder_options.compression_type,
table_builder_options.compression_opts,
table_builder_options.compression_dict,
table_builder_options.skip_filters,
table_builder_options.column_family_name);
return table_builder;
}
TableBuilder主要用于写sst files,使用该接口有四个地方
- When flushing memtable to a level-0 output file, it creates a table
builder (In DBImpl::WriteLevel0Table(), by calling BuildTable())
- During compaction, it gets the builder for writing compaction output
files in DBImpl::OpenCompactionOutputFile().
- When recovering from transaction logs, it creates a table builder to
write to a level-0 output file (In DBImpl::WriteLevel0TableForRecovery,
by calling BuildTable()) - When running Repairer, it creates a table builder to convert logs to
SST files (In Repairer::ConvertLogToTable() by calling BuildTable())
类图中SSTFileWriter对TableBuilder的引用就是其中一个场景。这里直接引用了该接口的注释。
如类图所示,BlockBasedTableBuilder继承了TableBuilder接口,对外提供了Add、Finish、Abandon等接口,并持有一个Rep内部类,包装了一些选项,目标文件指针,和另外一个主要的结构BlockBuilder。
BlockBasedTableBuilder的Add方法实现:
- 判断key的类型,不同类型有不同的处理方法
- 判断当前的key是否比上一个key大,保证有序
- 判断是否需要flush当前的block到文件中,并清空data block
- 插入到data block中
部分实现代码如下:
void BlockBasedTableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
...
if (r->props.num_entries > 0) {
assert(r->internal_comparator.Compare(key, Slice(r->last_key)) > 0);
}
...
auto should_flush = r->flush_block_policy->Update(key, value);
if (should_flush) {
assert(!r->data_block.empty());
Flush();
...
r->last_key.assign(key.data(), key.size());
r->data_block.Add(key, value);
r->props.num_entries++;
r->props.raw_key_size += key.size();
...
r->data_block 成员类型为BlockBuilder,这一层就是"BlockBasedTable"的底层,即负责构造block的类。
- 前缀压缩:BlockBuilder使用前缀压缩来保存数据,以节省空间。
- restart point:并不是所有的kv都使用前缀压缩,而是有一个分界点,每当使用前缀压缩保存了K个key,下一个kv就不适用前缀压缩,而是保存整个key,它的offset就是一个restart point。restart point保存在一个数组中,写在block的尾部,用来做二分查找。
- value的保存紧跟在对应的key的后面。
一个典型的block的结构如下:
| shared_bytes (varint32) | unshared_bytes(varint32) | value_length(varint32) | key_delta(unshared_bytes) 差异部分key | value(char[value_length]) |
... // n个上面的结构
| restarts(uint32[num_restarts]) | num_restarts(uint32) | // block尾部
// 当shared_bytes = 0 时,代表一个restart point。
BlockBuilder持有一个成员last_key_,保存上一个Add的key,用来与当前的key计算相同的前缀长度。
BlockBuilder的Add逻辑如下:
- 判断是否需要restart point
- 如果不需要restart point,将当前插入的key与前一个key比较前缀,得到可以压缩的前缀长度。
- 得到所有需要的数据后,按照一个entry的格式,append到buffer中。
计算相同前缀的长度为Slice的一个成员方法,Slice是key和value的类型,是对string的一层封装。实现如下
inline size_t Slice::difference_offset(const Slice& b) const {
size_t off = 0;
const size_t len = (size_ < b.size_) ? size_ : b.size_;
for (; off < len; off++) {
if (data_[off] != b.data_[off]) break;
}
return off;
}
Add方法的主要逻辑实现如下
void BlockBuilder::Add(const Slice& key, const Slice& value) {
...
size_t shared = 0; // number of bytes shared with prev key
if (counter_ >= block_restart_interval_) {
// Restart compression
restarts_.push_back(static_cast(buffer_.size()));
estimate_ += sizeof(uint32_t);
counter_ = 0;
if (use_delta_encoding_) {
// Update state
last_key_.assign(key.data(), key.size());
}
} else if (use_delta_encoding_) {
shared = key.difference_offset(last_key_piece);
...
last_key_.assign(key.data(), key.size());
}
const size_t non_shared = key.size() - shared;
const size_t curr_size = buffer_.size();
// Add "" to buffer_
PutVarint32Varint32Varint32(&buffer_, static_cast(shared),
static_cast(non_shared),
static_cast(value.size()));
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
}
当向一个block中加入了若干个kv,由r->flush_block_policy来决定是否调用BlockBasedTableBuilder的Flush方法将当前的block写入到文件中,并清空block,重新再用。
默认的fush block策略定义在FlushBlockBySizePolicy中,即根据block的已写入大小来决定刷盘,接口为Update,默认的block大小为4K。
virtual bool Update(const Slice& key,
const Slice& value) override {
// it makes no sense to flush when the data block is empty
if (data_block_builder_.empty()) {
return false;
}
auto curr_size = data_block_builder_.CurrentSizeEstimate();
// Do flush if one of the below two conditions is true:
// 1) if the current estimated size already exceeds the block size,
// 2) block_size_deviation is set and the estimated size after appending
// the kv will exceed the block size and the current size is under the
// the deviation.
return curr_size >= block_size_ || BlockAlmostFull(key, value);
}
当需要flush block时,调用Flush方法,Flush方法调用了WriteBlock方法。
void BlockBasedTableBuilder::Flush() {
...
WriteBlock(&r->data_block, &r->pending_handle, true /* is_data_block */);
...
}
WriteBlock会首先调用data_block的Finish()方法,将start points append到buffer_中,设置block的标志位finished_ = true
WriteBlock(block->Finish(), handle, is_data_block);
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, static_cast(restarts_.size()));
finished_ = true;
return Slice(buffer_);
}
然后会按下面的格式将一个block写入目标文件中
| block_data(uint8[n]) | type(uint8) | crc(uint32)|
- 对block中的数据进行压缩,如果打开了校验功能,这时会立刻进行一次解压,和原始数据进行一次比较,查看压缩算法是否出错。
- 将压缩(或者由于data太大而没有压缩)的数据写入到文件中。
- 计算checksum
- 插入到压缩cache中
部分实现如下
void BlockBasedTableBuilder::WriteBlock(const Slice& raw_block_contents,
BlockHandle* handle,
bool is_data_block) {
...
block_contents = CompressBlock(raw_block_contents, r->compression_opts,
&type, r->table_options.format_version,
compression_dict, &r->compressed_output);
...
WriteRawBlock(block_contents, type, handle);
}
void BlockBasedTableBuilder::WriteRawBlock(const Slice& block_contents,
CompressionType type,
BlockHandle* handle) {
...
r->status = r->file->Append(block_contents);
...
auto crc = crc32c::Value(block_contents.data(), block_contents.size());
crc = crc32c::Extend(crc, trailer, 1); // Extend to cover block type
EncodeFixed32(trailer_without_type, crc32c::Mask(crc));
...
r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));
if (r->status.ok()) {
r->status = InsertBlockInCache(block_contents, type, handle);
}
...
}
在data block写完之后, 会在BlockBasedTableBuilder的Finish方法中,将后续的meta blocks, meta index block, index block和footer等写入到文件中.
以上就是block的构建过程.
小结
通过对BlockBasedTable的类图分析, 和block构建过程, 对RocksDB的数据存储方式有了一个清楚的认识. 其中一些meta blocks和TableReader等更多的内容随着我们对RocksDB更多的分析, 也会逐个分析到.
参考资料:
https://github.com/facebook/rocksdb/wiki/Rocksdb-BlockBasedTable-Format