OCR(Optical Character Recognition,光学字符识别),用于识别图片中的文字。本文测试,百度OCR文字识别的接口,默认文字识别次数是每天500次,网址。
源码参考:
https://github.com/SpikeKing/MachineLearningTutorial/blob/master/tests/ocr_test.py

OCR
创建应用,在应用中,百度提供默认的API Key和Secret Key,API接口文档。
方法:get_access_token的参数是应用的API Key和Secret Key,获取特定的access_token。
def get_access_token(app_key, secret_key):
api_key_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s'
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = (api_key_url % (app_key, secret_key))
request = urllib2.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
content = response.read()
keys = json.loads(content)
access_token = keys['access_token']
return access_token
方法recognize_image_words识别图片中的文字,数据源可选网络图片或本地图片。
def recognize_image_words(access_token, img):
ocr_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic/?access_token=%s'
url = (ocr_url % access_token)
# 上传的参数
data = dict()
data['languagetype'] = "CHN_ENG" # 识别中文
# 图片数据源,网络图片或本地图片
if img.startswith('http://'):
data['url'] = img
else:
image_data = open(img, 'rb').read()
data['image'] = image_data.encode('base64').replace('\n', '')
# 发送请求
decoded_data = urllib.urlencode(data)
req = urllib2.Request(url, data=decoded_data)
req.add_header("Content-Type", "application/x-www-form-urlencoded")
# 获取请求的数据,并读取内容
resp = urllib2.urlopen(req)
content = resp.read()
# 识别出的图片数据
words_result = json.loads(content)['words_result']
words_list = list()
for words in words_result:
words_list.append(words['words'])
return words_list
main函数,将两个函数连接在一起。
if __name__ == '__main__':
img = './data/text_img2.jpeg'
online_img = "http://www.zhaoniupai.com/hbv/upload/20150714_LiangDuiBan.jpg"
access_token = get_access_token(app_key=app_key, secret_key=secret_key)
print 'access_token: %s' % access_token
print '\nwords_list:'
words_list = recognize_image_words(access_token, online_img)
for x in batch(words_list, 5): # 每次打印5个数据
show_string(x)
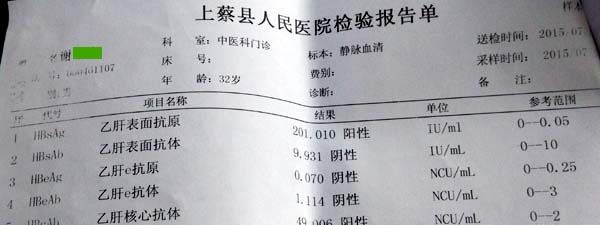
数据结果,网络图片1次速度大约0.43秒,本地图片(47KB)大约1.27秒。
words_list:
["上蔡县人民医院检验报告单", "科室:中医手科门诊", "送检时间:2015", "采样时间:2015", "费别"]
["B4x乙肝表面抗原", "201.010阳性", "乙肝表面抗体", "0-10", "31阴性"]
["BeAg乙肝e抗原", "70阴性", "0-0.25", "BeAb乙肝e抗体", "1.114阴性"]
["Bk=Al乙肝核心抗体", "49.006阳性", " cu / .", "0-2"]
time elapsed: 00:00:00.43
测试图片:
测试图片
OK, that's all! Enjoy it!