一、k-means
k-means算法并没有显示的学习过程,而且很简单,给定一个训练数据集,其中的实例类别已定,分类时,对新的输入实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。k-means实际上利用训练数据集对特征向量空间进行划分,并作为其对分类的“模型”。
k-means主要是在对k值的选择,距离的度量以及分类决策规则的调控。
K-means方法寻找的是球形或超球面形类,所以并不适用以下几种类型的分类:
注意不要混淆K-近邻算法和K均值聚类。 K-近邻算法是一种分类算法,也是监督学习的一个子集。 K-means是一种聚类算法,也是非监督学习的一个子集。
那么就引入了其他的聚类方法:
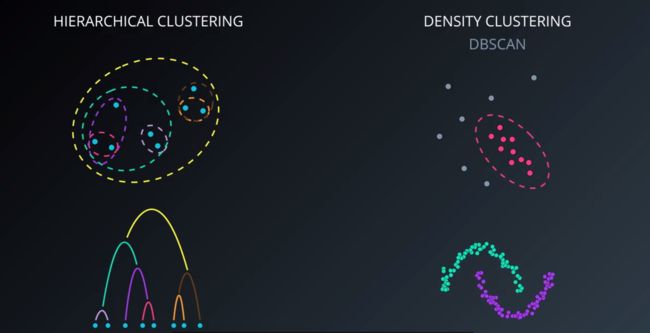
二、层次聚类Hierarchical Clustering
部分内容出自这里
层次聚类能让人直观的了解到类之间的关系。
层次聚类( Hierarchical Clustering )是聚类算法的一种,通过计算不同类别的相似度类创建一个有层次的嵌套的树。
假设有 n 个待聚类的样本,对于层次聚类算法,它的步骤是:
- 步骤一:(初始化)将每个样本都视为一个聚类;
- 步骤二:计算各个聚类之间的相似度;
- 步骤三:寻找最近的两个聚类,将他们归为一类;
- 步骤四:重复步骤二,步骤三;直到所有样本归好类。
整个过程就是建立一棵树,在建立的过程中,可以在步骤四设置所需分类的类别个数,作为迭代的终止条件,毕竟都归为一类并不实际。
sklearn的层次聚类
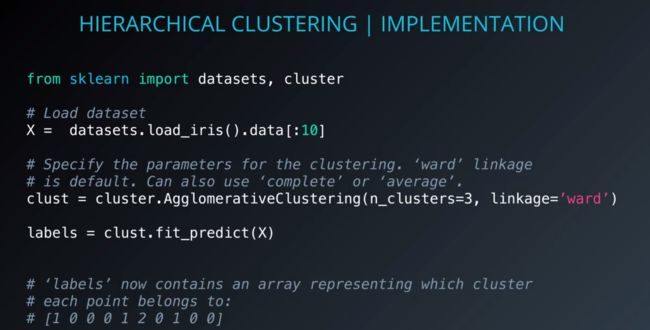
scipy画系统树图

层次聚类的优缺点
优点:
- 一次性得到聚类树,后期再分类无需重新计算;
- 相似度规则容易定义;
- 可以发现类别的层次关系,而且层次信息非常丰富;
- 可以将数据集的聚类结构视觉化
缺点:
- 计算复杂度高,不适合数据量大的;
- 算法很可能形成链状。
- 对噪音和离群值很敏感
下面是层次聚类的几种分类:
1、单连接聚类法Single Linkage
又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离。这种计算方式容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。单连接是查看与聚类最近的点,这可能导致形成各种形状的聚类。
跟上面的步骤一样,我们分解来看:
-
步骤一:(初始化)将每个样本都视为一个聚类;
 层次聚类1.png
层次聚类1.png -
步骤二:计算各个聚类之间的相似度,简单来说就是计算任意两点之间的距离
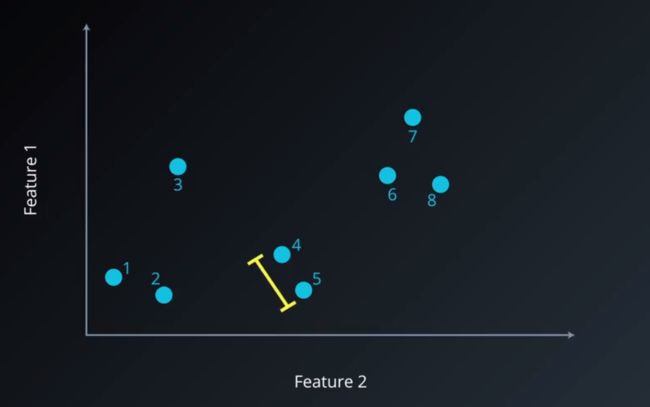 层次聚类2.png
层次聚类2.png -
步骤三:寻找最近的两个聚类,将他们归为一类,就是选择两个类之间的最短距离,然后将这两个点作为一个聚类,在旁边就能画出第一个节点的层次。
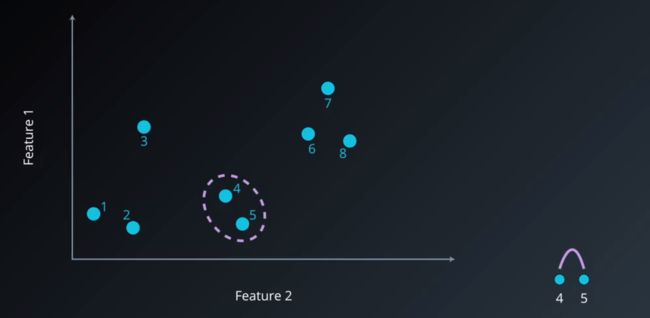 层次聚类3.png
层次聚类3.png
-
步骤四:重复步骤二和步骤三,当不再有单独的点作为一个类,而是要判断多个类和多个类之间的距离的地方(这是个关键的地方,这一步是区分不同层次聚类的方法的标准,究竟是看单个类,还是类的平均距离等等。)单连接聚类法关乎的是两类间的最短距离,所以他衡量的依然是单个类与另一个类节点的最短距离,以图例来说就是6和7是最短距离
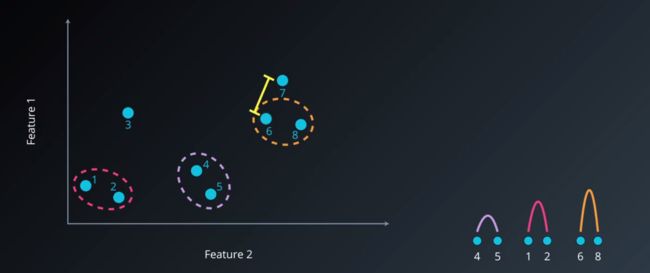 层次聚类4.png
层次聚类4.png
判断好最短距离后,将这个单独节点再归到整体聚类中,成为了一个新的类,这个新的类中含有另外一个类作为子类
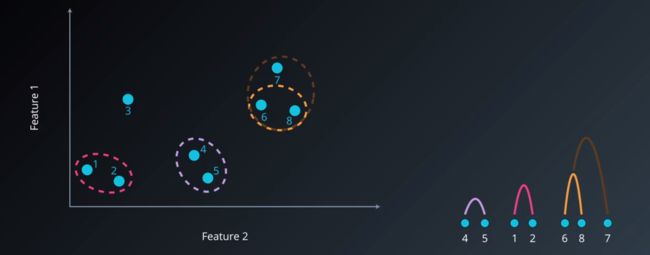 层次聚类5.png
层次聚类5.png
如此循环规整完毕后,就生成了系统树图
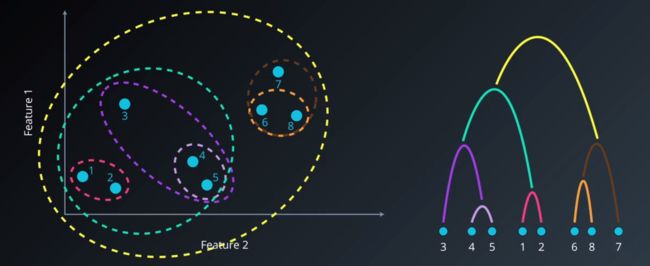 层次聚类6.png
层次聚类6.png
就像上面说的,归为一个类是不切实际的,所以我们会给层次聚类一个输入,那就是有多少个类,通过有多少个类,来在系统树图上进行切割划分,比如我们分两个聚类,那么如图,截掉不必要的层次即可:
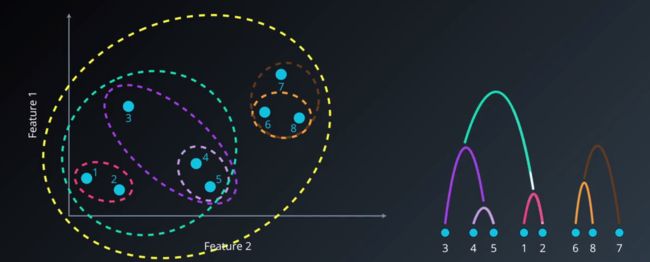 层次聚类7.png
层次聚类7.png
所以 单连接聚类法 或广义上的层次聚类法能帮我们得到一个类 或者样本数量等等。
与k-means的区别
下图是同样的数据,使用k-means和使用单连接层次聚类法的区别
同样我们通过单连接层次聚类能画出系统树图来看数据的规律
虽然我们不一定能通过单连接聚类法得出最好的分类结果,但是系统树图还是能让我们看出来规律,再使用其他的聚类方法来得到划分。
2、全连接聚类Complete Linkage
这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。全连接聚类法中 这样的距离衡量方法使得产生的类比较紧凑,比单连接聚类法产生的类更紧凑 更好,但毕竟也是只考虑单个点的存在,其效果也是刚好相反的,限制也很大。Single Linkage和Complete Linkage这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
来看具体步骤,它整体的步骤跟单连接聚类很接近,只是在步骤四时有区分
- 步骤四:之前也有说过,判断距离方式的不同造就了不同的聚类方法,全连接聚类不再是判断两个类最近的距离,而是将一个类与另一个类中节点最远的那个点作为最小距离的判断依据(全连接聚类法关注的是两个类中两点之间的最远距离作为最小距离),有点绕,看图:
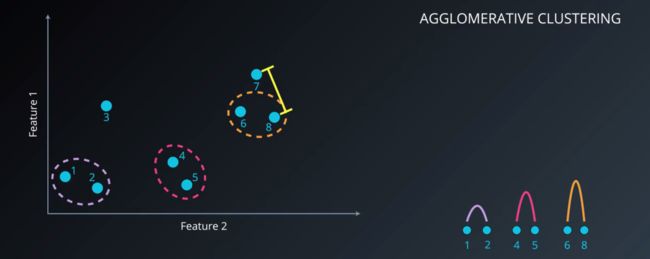 层次聚类10.png
层次聚类10.png
3、组平均聚类average link
这种方法跟上两个其实也很相似,就是把两个集合中的点两两的距离全部放在一起求均值,相对也能得到合适一点的结果(详细来说,它计算的是任意两类中任意两点之间的距离,然后取平均值 即为两类之间的距离,然后判断最小类距离作为聚类标准)。有时异常点的存在会影响均值,平常人和富豪平均一下收入会被拉高是吧,因此这种计算方法的一个变种就是取两两距离的中位数。
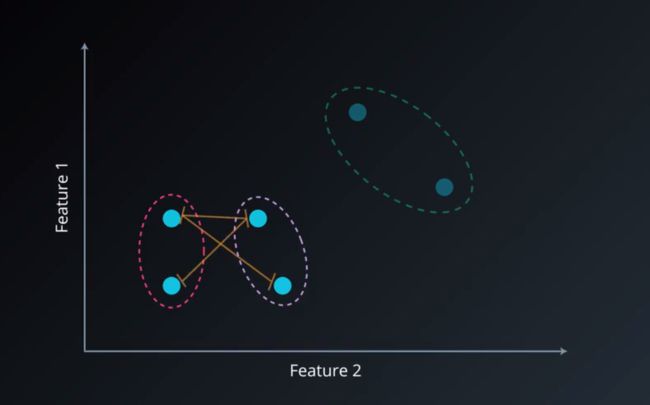
上图举例两类距离求平均。
4、Ward's method离差平方和法
这种方法是 Scikit-learn 框架中一种预设的层次聚类法,它的目的是把合并类时的变量最小化,离差平方和法计算两类间的距离的方法是:先找出这两个聚类总体的中心位置O,然后计算每个节点和中心位置的距离记做C,分别计算这些距离C的平方,并且相加记为delta,然后找出这两个聚类分别的中心位置O1,O2,比如第一个类的中心是O1,那么第一类的节点与O1的距离记做A,那么之前求出来的平方和delta减去所有A的平方,这样循环得出来各个类之间的最小距离,将最小距离的类化为一类。这样离差平方和法会最小化在每个合并步骤中的方差。
整体流程如图:
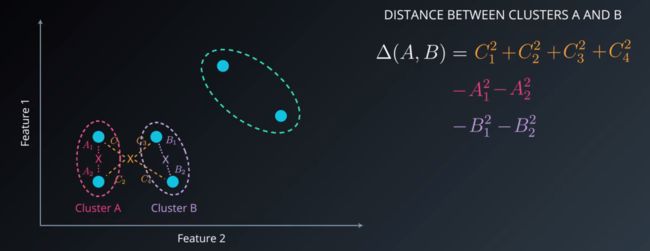
离差平方和法和平均连接算法一般倾向于导致紧凑的聚类。
三、密度聚类Density-based Clustering
最主要的算法叫DBScan,指的是 具有噪声的基于密度的聚类方法,对有噪声的数据集具有很强的适用性,它并不要求我们具体说明一系列的类,一般把一些密集分布的点聚类,再将其他剩余的点标记为噪音。
具体步骤如下:
步骤一:设置最小距离,用来决定在某个范围内是否有其他点的这个范围,设置点的个数,即在这个范围内是否有这么多的点存在,如果存在设置为Core point,如果不存在设置为Noise point,如果不存在,但是在之前设置的core point范围内,那么就为border point。
步骤二:随机找到一个数据点,看是否有足够数量的点在范围内
步骤三:重复步骤二
以下图为例,可以将数据点划为下面几种:
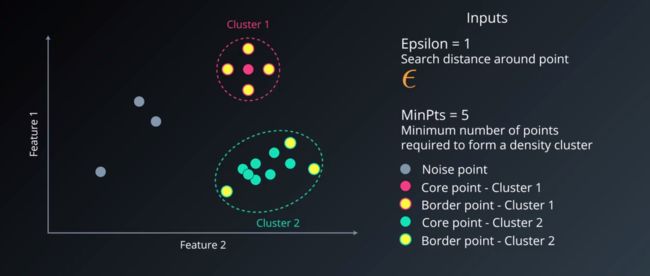
DBSCAN优缺点
优点:
- 不需要指明类数量,而是通过举例和点数量来分的,即点的密度
- 能够找到并分离各种形状和大小的聚类,不局限于外形
- 能够处理噪声和离群值
缺点: - 边界点很有可能在多次运行时不会被划分为同一个类,因为运行算法时的点是随机选取的
- 在找到不同密度的聚类方面有一定的困难,毕竟只能设置一个密度(所以我们可以用 DBSCAN 的变体 HDBSCAN 即具有噪声的基于密度的高层次空间聚类算法)
DBSCAN和Kmeans的对比

sklearn实现DBSCAN
因为可控参数不太多,那么有一些基本的规律在里面:
- 如果聚类后有很多小的聚类。超出了数据集的预期数量。
措施:增大 min_samples 和 ε - 很多点都属于一个聚类
措施:降低 ε 并增大 min_samples - 大部分/所有数据点都标记为噪点
措施:增大 ε 并降低 min_sample - 除了非常密集的区域之外,大部分/所有数据点都标记为噪点(或者所有点都标记为噪点)。
措施:降低 min_samples 和 ε
四、高斯混合模型聚类Gaussian Mixture Model Clustering
部分参考这里和这里
统计的先修知识也可以先查看我以前写过的文章。
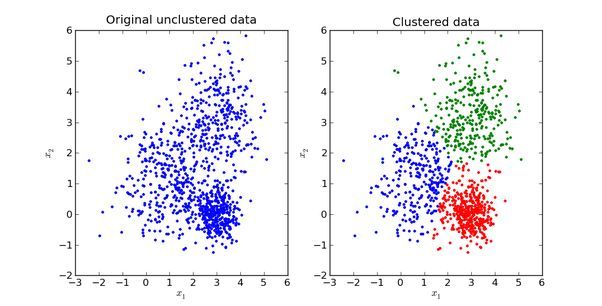
GMM和k-means其实是十分相似的,区别仅仅在于对GMM来说,我们引入了概率,这种聚类算法假定每个类都遵循特定的统计分布,它大量使用概率和统计学知识来找出这些类。说到这里,我想先补充一点东西。统计学习的模型有两种,一种是概率模型,一种是非概率模型。所谓概率模型,就是指我们要学习的模型的形式是P(Y|X),这样在分类的过程中,我们通过未知数据X可以获得Y取值的一个概率分布,也就是训练后模型得到的输出不是一个具体的值,而是一系列值的概率(对应于分类问题来说,就是对应于各个不同的类的概率),然后我们可以选取概率最大的那个类作为判决对象(算软分类soft assignment)。而非概率模型,就是指我们学习的模型是一个决策函数Y=f(X),输入数据X是多少就可以投影得到唯一的一个Y,就是判决结果(算硬分类hard assignment)。回到GMM,学习的过程就是训练出几个概率分布,所谓混合高斯模型就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
如图:
单高斯模型
要理解高斯混合模型,首先要知道最基本的高斯模型是什么,下面是找到的定义:

高斯混合模型(GMM)
那么再回到高斯混合模型,高斯混合模型可以看作是由 K 个单高斯模型组合而成的模型,这 K 个子模型是混合模型的隐变量(Hidden variable)。一般来说,一个混合模型可以使用任何概率分布,这里使用高斯混合模型是因为高斯分布具备很好的数学性质以及良好的计算性能。
举个不是特别稳妥的例子,比如我们现在有一组狗的样本数据,不同种类的狗,体型、颜色、长相各不相同,但都属于狗这个种类,此时单高斯模型可能不能很好的来描述这个分布,因为样本数据分布并不是一个单一的椭圆,所以用混合高斯分布可以更好的描述这个问题,如下图所示:

模型参数学习
对于单高斯模型,我们可以用最大似然法(Maximum likelihood)估算参数θ的值,
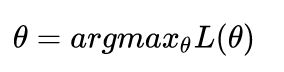
这里我们假设了每个数据点都是独立的(Independent),似然函数由概率密度函数(PDF)给出。
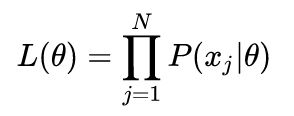
由于每个点发生的概率都很小,乘积会变得极其小,不利于计算和观察,因此通常我们用 Maximum Log-Likelihood 来计算(因为 Log 函数具备单调性,不会改变极值的位置,同时在 0-1 之间输入值很小的变化可以引起输出值相对较大的变动):
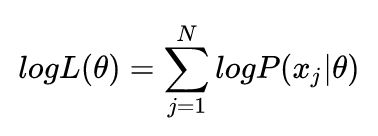
对于高斯混合模型,Log-Likelihood 函数是:
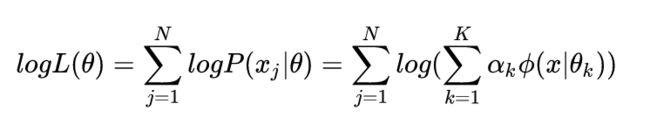
如何计算高斯混合模型的参数呢?这里我们无法像单高斯模型那样使用最大似然法来求导求得使 likelihood 最大的参数,因为对于每个观测数据点来说,事先并不知道它是属于哪个子分布的(hidden variable),因此 log 里面还有求和, K 个高斯模型的和不是一个高斯模型,对于每个子模型都有未知的α,μ,σ ,直接求导无法计算。需要通过迭代的方法求解。
这就引出了下面这个算法EM算法:
期望最大化算法(EM算法)概述
先来看下整体的步骤的定义:

那么拆解下来详细看:
第一步 初始化 K 个高斯分布
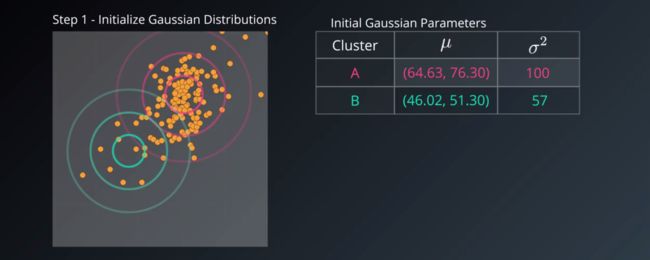
那么需要设置这几个高斯分布的均值和标准差,最简单的方法是设定为数据集本身的均值和标准差,另一种方法是在数据集使用k-means,然后使用由 k means生成的聚类来初始化这K个高斯分布。
下面的例子假设为2个高斯分布,随机初始化了两个分布的均值和标准差:
第二步 假设参数已知,去估计隐藏变量的期望,即将数据软聚类成我们初始化的两个高斯,这一步称为期望步骤 或 E-step
公式如图,中间N()是正态分布的概率密度函数,那么N(A)是指属于A正太的概率密度是多少,同理N(B)是指属于B正太的概率密度是多少,那么E(Z_1A)中,1是指某一个点,A是指属于A正太分布,Z是所谓的隐藏变量或潜在变量,那么通过公式和具体的点和正态分布的均值标准差,就能计算出所有点的期望值。

第三步 利用E步求得的隐藏变量的期望,根据最大似然估计求得参数,然后新得到的参数值重新被用于E步,即基于软聚类重新估计高斯,即求极大,计算新一轮迭代的模型参数,这一步称为最大化步骤 或 M-step
这一步就是用第二步的结果作为输入,来生成新的均值和标准差。
那么新均值,怎么出来的呢?是所有属于这一类的点的加权平均值,权值就是上面的期望值,如图:
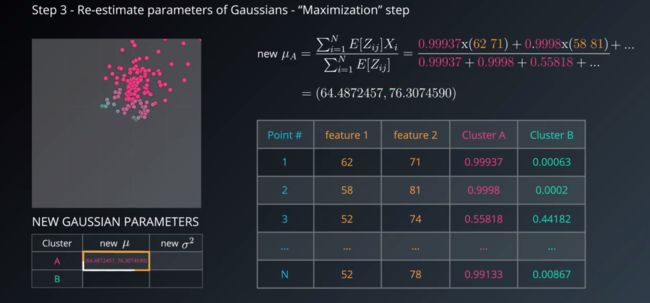
这样就得出了聚类A的新均值。
接着计算新标准差的平方即方差,整体思路差不多,套公式(跟传统计算方差的公式很像)带进去算属于该类的所有点加权平均的方差即可,同样E是之前第二步计算出的期望值:

第四步 我们评估对数似然来检查收敛,如果它收敛,则认为一切正常,返回结果,如果它不收敛 我们回到第二步直到它收敛

这个计算出来的结果越高,我们越能确定生成的混合模型适合我们有的数据集,所以我们的目的就是通过改变合适的混合系数π,均值μ,方差σ^2,从而来最大化这个值,即达到最大值或每一步开始增加一小部分,这样就停止运算,然后选择那些计算好的模型作为高斯混合模型的组成部分。
上面例子是使用方差来,只能衡量一维数据的离散程度,对于二维数据,就用到了协方差(最上面提过的那个式子),那么就不单单是方差的圆形范围而可以是椭圆范围了。
使用协方差来进行运算,上面那些数据点就可以分成这样:
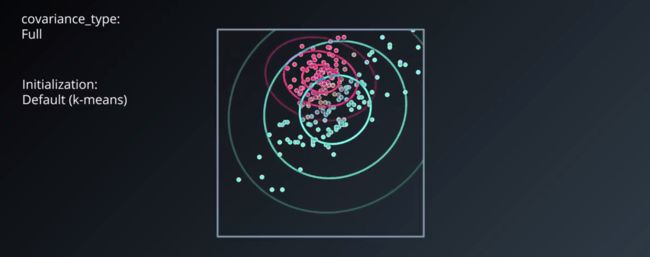
具体的公式与推导可以看这里.
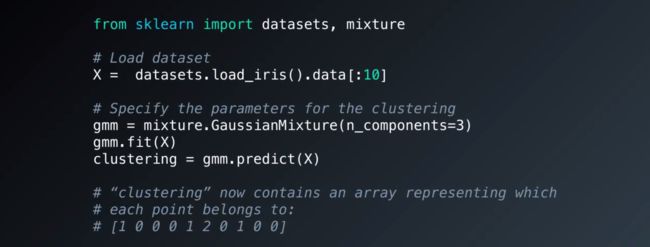
sklearn实现GMM
GMM优缺点
优点:
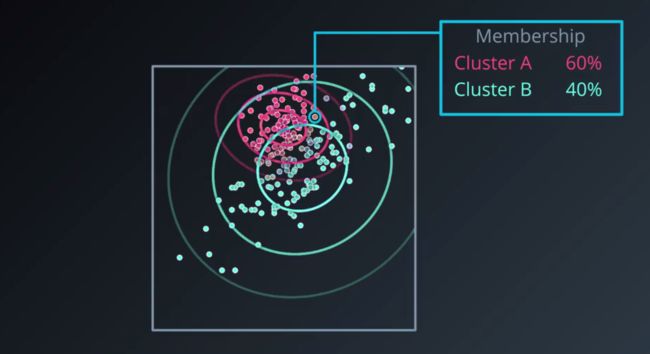
- 为我们提供软聚类,软聚类是多个聚类的示例性隶属度。
- 在聚类外观方面很有灵活性
缺点: - 对初始化值很敏感
- 有可能收敛到局部最优
- 收敛速度慢
五、聚类分析过程
1、总体流程
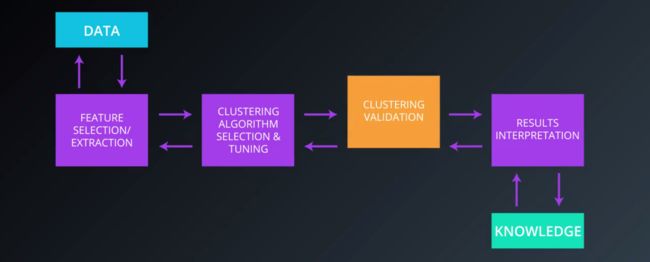
第一步 特征选择和特征提取
特征选择是从一组候选特征中选择特征,我们不必对所有的数据集都使用聚类方法,毕竟运算量非常大,进行选择并提取后,留下与所需数据强相关的数据从而来进行运算即可,特征提取是对数据进行转换,以生成新的有用特征(例如PCA)
sklearn实现特征缩放
>>> from sklearn.preprocessing import MinMaxScaler
>>>
>>> data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
>>> scaler = MinMaxScaler()
>>> print(scaler.fit(data))
MinMaxScaler(copy=True, feature_range=(0, 1))
>>> print(scaler.data_max_)
[ 1. 18.]
>>> print(scaler.transform(data))
[[0. 0. ]
[0.25 0.25]
[0.5 0.5 ]
[1. 1. ]]
>>> print(scaler.transform([[2, 2]]))
[[1.5 0. ]]
第二步 选择一个聚类算法
根据需要做什么和数据的外观,试验哪一个算法可以给你更好的结果,没有任何算法可以普遍地适用于我们可能面临的问题,在这一步,我们必须选择一个邻近度度量,比如欧几里得距离,余弦距离,Pearson 相关系数等等。
第三步 聚类评价
评估一个聚类的效果如何,除了在可能的情况下对聚类结果进行可视化以外,我们还可以使用一些评分方法来评估,基于特定标准的聚类结构的质量,这些评分方法被称为指数,每一个指数称为聚类有效性指标
第四步 聚类结果解释
可以从最终的聚类结构中学习到什么样的见解,这一步骤需要领域专业知识为集群提供标签,并试图从中推断出一些见解
2、详解聚类评价
聚类评价是客观和定量评估聚类结果的过程,大多数评价指标是通过紧凑性和可分性来定义的,紧凑性是衡量一个聚类中的元素彼此之间的距离,可分性是表示不同聚类之间的距离,聚类方法通常希望产生一个聚类中的元素彼此最相似,而聚类之间最不相同的聚类,聚类评价方法总共有三种:
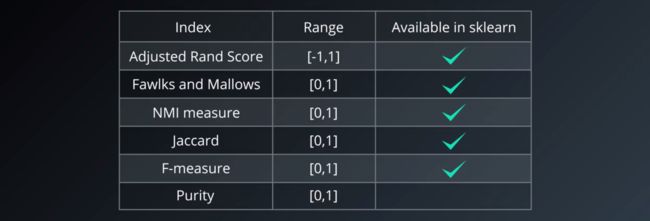
2.1、外部指标
处理有标签数据时使用的评分
调整兰德系数定义

调整兰德系数优缺点
优点:
- 对任意数量的聚类中心和样本数,随机聚类的ARI都非常接近于0;
- 取值在[-1,1]之间,负数代表结果不好,越接近于1越好;
- 可用于聚类算法之间的比较。
缺点:
- 需要真实标签
举例调整兰德系数求解过程:

Sklearn实现
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24
2.2、内部指标
大部分非监督学习是没有评分,所以一般用内部指标比较合理,内部指标仅使用数据来衡量数据和结构之间的吻合度
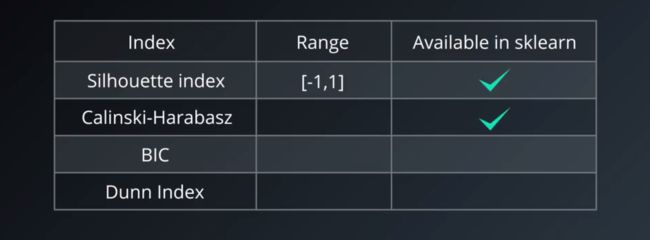
轮廓系数定义

另外提示下:处理 DBSCAN 时,不要使用轮廓系数,而使用DBCV评价指标。
举例轮廓系数求解过程:

Sklearn实现
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.silhouette_score(X, labels, metric='euclidean')
...
0.55
...
2.3、相对指标
这个指标表明两个聚类结构中哪一个在某种意义上更好,基本上所有的外部指标都能作为相对指标
更多指标详解可以看这里