前言
在前面的文章中,笔者有对编辑距离以及Levenshtein距离进行详细的说明,其实levenshtein距离是编辑距离的其中一种定义,本文所说的Jaro距离是编辑距离的另外一种定义,它也是对两个字符串的相似度进行衡量,以得出两字符串的相似程度。下面我们一起来学习这个算法的原理以及实现吧。
算法定义
下面先说说Jaro distance(又称Jaro similarity),这是由Matthew A. Jaro在1989年提出的算法,而Jaro-Winkler distance是由William E. Winkler在Jaro distance的基础上进一步改进的算法。
1、Jaro distance/similarity
对于两个字符串s1和s2,它们的Jaro 相似度由下面公式给出:
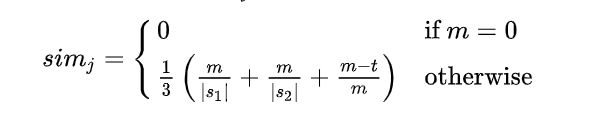
其中:
①|s1|和|s2|表示字符串s1和s2的长度。
②m表示两字符串的匹配字符数。
③t表示换位数目transpositions的一半。
这里的m和t是满足一定条件下得出来的,在理解m和t的含义之前,我们先来认识匹配窗口(记为matching window,mw)的概念。Jaro算法的字符之间的比较是限定在一个范围内的,如果在这个范围内两个字符相等,那么表示匹配成功,如果超出了这个范围,表示匹配失败。而这个范围就是匹配窗口,在Jaro算法中,它被定义为不超过下面表达式的值:

比如说字符串A("bacde")和B("abed"),它的匹配窗口大小为1,在匹配的过程中,字符'a'、'b'、'd'都是匹配的,indexInA('d') = 3,indexInB('d') = 3,二者的距离是0,小于匹配窗口大小。但对于'e',虽然两字符串都有'e'这个字符,但它们却是不匹配的,因为'e'的下标分别为4和2,距离为2 > mw,所以'e'是不匹配的。在这个例子中,由于有3个字符匹配,因此m = 3。换位数目表示不同顺序的匹配字符的个数。同样看这个例子,'a'和'b'都是匹配的,但'a'和'b'在两个字符串的表示为"ba.."和"ab..",它们的顺序不同,因此这里换位数目transpositions = 2,而t = transpositions / 2 = 1。
对于匹配窗口的含义,笔者的理解是:匹配窗口是一个阈值,在这个阈值之内两个字符相等,可以认为是匹配的;超过了这个阈值,即使存在另一个字符与该字符相等,但由于它们的距离太远了,二者的相关性太低了,不能认为它们是匹配的。从上面的公式可以看出,该算法强调的是局部相似度。
对于任意字符串A和B,能求出它们的length、m和t,这样便能代入公式求得二者的相似度(Jaro similarity)。从刚才的例子得到,|s1|=5,|s2|=4,m=3,t=1,代入公式可得:simj = (3/5 + 3/4 + (3-1)/3)/3 = 0.672
2、Jaro-Winkler distance/similarity
Jaro-Winkler similarity是在Jaro similarity的基础上,做的进一步修改,在该算法中,更加突出了前缀相同的重要性,即如果两个字符串在前几个字符都相同的情况下,它们会获得更高的相似性。该算法的公式如下:

其中:
①simj 就是刚才求得的Jaro similarity。
②l表示两个字符串的共同前缀字符的个数,最大不超过4个。
③p是缩放因子常量,它描述的是共同前缀对于相似度的贡献,p越大,表示共同前缀权重越大,最大不超过0.25。p默认取值是0.1。
图解Jaro-Winkler similarity求解过程
下面以字符串A("abcdefgh")和字符串B("abehc")为例来介绍整个算法的流程。这里以短字符串为行元素,长字符串为列元素,建立(|s1|+1)×(|s2|+1)的矩阵,这里匹配窗口的大小为3(注意包括距离为0的匹配),然后根据公式不断运算:
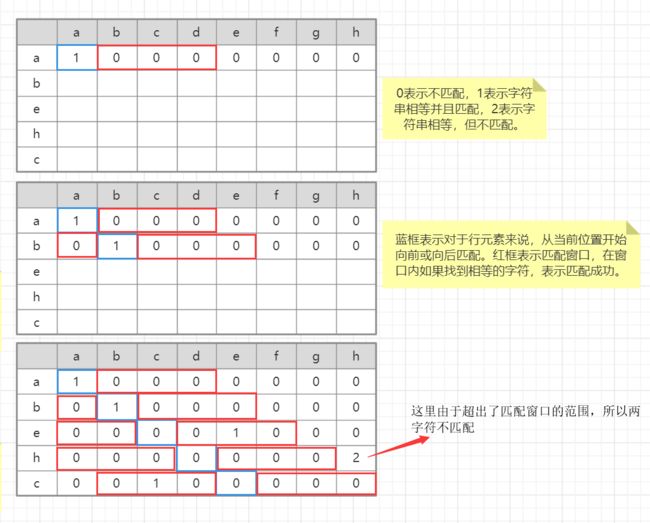
从上面的图以及公式,我们可以 总结出求解的过程:字符串s1作为行元素,字符串s2作为列元素,窗口大小为mw,同时建立两个布尔型数组,大小分别为s1和s2的长度,布尔型数组对应下标的值True表示已匹配,false表示不匹配。
对于行元素的每一个字符c1,根据c1在该字符串s1中的下标k,定位到s2的k位置,然后在该位置往前遍历mw个单位,往后遍历mw个单位,如果寻找到相等的字符,记在s2中的下标为p。经过这样的一次遍历,找到了k和p,我们分别标记布尔型数组s1的k和布尔型数组s2的p为已匹配(true),下次遍历时就跳过该已匹配的字符。当对s1的所有元素都遍历完毕时,就找到了所有已匹配的字符,我们统计已匹配的字符便能得到m,然后对两个布尔型数组同时按照顺序比较,如果出现了true,但二者对应字符串相应位置的字符不相等,表示这是非顺序的匹配,这样就可以得到t。这样就能根据m和t求出Jaro similarity了。至于Jaro-Winkler similarity,需要p参数,也不难,求出俩字符串最大共同前缀的大小即可。
如果读者对上面的过程还有疑问,笔者再提一点,关键就在于判断来自俩字符串的相等字符的距离是不是超过了阈值(即匹配窗口长度)。这里的判断方法是在某个位置进行前后的搜索,包括当前位置。
代码实现
根据上面的实现思路以及图解过程,我们能很容易写出下面的代码:
public class JaroWinklerDistance {
private float p = 0.1f;
private final float MAX_P = 0.25f;
private final int MAX_L = 4;
/**
* 用户可以修改p参数,以提高共同前缀的权重
* @param p
*/
private void setP(float p){
this.p = p;
}
public float getJaroDistance(CharSequence s1,CharSequence s2){
if (s1 == null || s2 == null) return 0f;
int result[] = matches(s1,s2);
float m = result[0];
if (m == 0f)
return 0f;
float j = ((m / s1.length() + m / s2.length() + (m - result[1]) / m)) / 3;
return j;
}
public float getJaroWinklerDistance(CharSequence s1,CharSequence s2){
if (s1 == null || s2 == null) return 0f;
int result[] = matches(s1,s2);
float m = result[0];
if (m == 0f)
return 0f;
float j = ((m / s1.length() + m / s2.length() + (m - result[1]) / m)) / 3;
float jw = j + Math.min(p,MAX_P) * result[2] * (1 - j);
return jw;
}
private int[] matches(CharSequence s1,CharSequence s2){
//用max来保存较长的字符串,min保存较短的字符串
//这是为了以短字符串为行元素遍历,长字符串为列元素遍历。
CharSequence max,min;
if (s1.length() > s2.length()){
max = s1;
min = s2;
}else{
max = s2;
min = s1;
}
//匹配窗口的大小,对于每一行i,列j只在(i-matchedwindow,i+matchedwindow)内移动,
//在该范围内遇到相等的字符,表示匹配成功
int matchedWindow = Math.max(max.length() / 2 - 1,0);
//记录字符串的匹配状态,true表示已经匹配成功
boolean[] minMatchFlag = new boolean[min.length()];
boolean[] maxMatchFlag = new boolean[max.length()];
int matches = 0;
for (int i = 0;i < min.length();i++){
char minChar = min.charAt(i);
//列元素的搜索:j的变化包括i往前搜索窗口长度和i往后搜索窗口长度。
for (int j = Math.max(i - matchedWindow,0);
j < Math.min(i + matchedWindow + 1,max.length());j++){
if (!maxMatchFlag[j] && minChar == max.charAt(j)){
maxMatchFlag[j] = true;
minMatchFlag[i] = true;
matches++;
break;
}
}
}
//求转换次数和相同前缀长度
int transpositions = 0;
int prefix = 0;
int j = 0;
for (int i = 0;i < min.length();i++){
if (minMatchFlag[i]){
while (!maxMatchFlag[j]) j++;
if (min.charAt(i) != max.charAt(j)){
transpositions++;
}
j++;
}
}
for(int i = 0;i < min.length();i++){
if (s1.charAt(i) == s2.charAt(i)){
prefix++;
}else {
break;
}
}
return new int[]{matches,transpositions / 2,prefix > MAX_L ? MAX_L : prefix};
}
public static void main(String args[]){
String s1 = "abcdefgh";
String s2 = "abehc";
JaroWinklerDistance distance = new JaroWinklerDistance();
System.out.println("字符串A(\"" + s1 +"\")"+"和字符串B(\"" + s2 + "\"):");
System.out.println("Jaro similarity:" + distance.getJaroDistance(s1,s2));
System.out.println("Jaro-Winkler similarity:" + distance.getJaroWinklerDistance(s1,s2));
}
}
我们运行上面的代码,可以得到下面的输出:

这与我们图解过程得到的结果手工计算出来的是一致的。
进一步探究
经过上面的学习,我们已经掌握了这个算法的原理以及实现方法,下面我们接着来探究它的特性以及适用场景。
我们来看下面的一组实验结果:

关键字是fox,另外的字符串是包含有fox几个字符的字符串,可以看出最高相似度的是"fox"在开始几位的情况下,而"afoxbcd"反而比"foaxbcd"更低,虽然前者含有完整的"fox"而后者是分开的。同时"abcdfox"的相似度为0,即使它末尾含有"fox"。上面这几个例子说明了jaro-winkler相似度对于前缀匹配更友好,并且越往前面匹配成功带来的权重更大。由此可以看出,该算法可以用在单词的匹配上,比如对于一个单词"appropriate",找出数据库中与它最匹配的一个词语,可以是"appropriation",也可以是"appropriately"等。但是,该算法不适用在句子匹配上,因为如果关键字在句子的后面部分,相似度会急剧下降,甚至为0。
好了,这篇文章到这里就结束了~喜欢的不要忘记点个赞哟,谢谢阅读!