移步数据结构--容器汇总(java & Android)
内容:
-
- LinkedList 的概述
-
- LinkedList 的构造方法
-
- LinkedList 的增删改查。
-
- LinkedList 作为队列(Queue)使用的时候增删改查。
-
- LinkedList 的遍历方法
1 LinkedList 的概述
LinkedList 的继承体系图
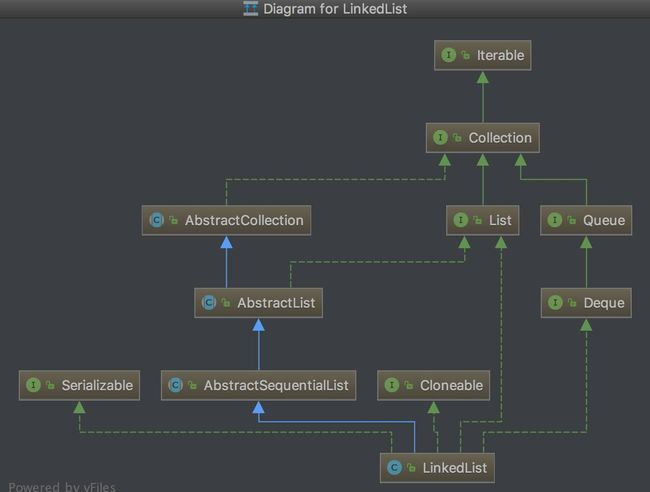
图中蓝色实线箭头是指继承关系 ,绿色虚线箭头是指接口实现关系。
-
- LinkedList 继承自 AbstrackSequentialList 并实现了** List 接口**以及 Deque 双向队列接口,因此 LinkedList 不但拥有 List 相关的操作方法,也有队列的相关操作方法。
-
- LinkedList 和 ArrayList 一样实现了序列化接口 Serializable 和 Cloneable 接口使其拥有了序列化和克隆的特性。
LinkedList 一些主要特性:
-
- LinkedList 集合底层实现的数据结构为双向链表
-
- LinkedList 集合中元素允许为 null
-
- LinkedList 允许存入重复的数据
-
- LinkedList 中元素存放顺序为存入顺序。
- LinkedList 是非线程安全的,如果想保证线程安全的前提下操作 LinkedList,可以使用 List list = Collections.synchronizedList(new LinkedList(...)); 来生成一个线程安全的 LinkedList
链表是一种不同于数组的数据结构,双向链表是链表的一种子数据结构,它具有以下的特点:
- 每个节点上有三个字段:当前节点的数据字段(data),指向上一个节点的字段(prev),和指向下一个节点的字段(next)。
2 LinkedList 双向链表实现
数据结构--链表(java)
3 LinkedList 的构造函数
3.1 无参构造
/**
* 空参数的构造由于生成一个空链表 first = last = null
*/
public LinkedList() {
}
3.2 传入一个集合类
/**
* 传入一个集合类,来构造一个具有一定元素的 LinkedList 集合
* @param c 其内部的元素将按顺序作为 LinkedList 节点
* @throws NullPointerException 如果 参数 collection 为空将抛出空指针异常
*/
public LinkedList(Collection c) {
this();
addAll(c);
}
带参数的构造方法,调用 addAll(c) 这个方法,实际上这方法调用了 addAll(size, c) 方法,在外部单独调用时,将指定集合的元素作为节点,添加到 LinkedList 链表尾部:
而 addAll(size, c) 可以将集合元素插入到指定索引节点。
3.2.1 addAll(Collection c)
public boolean addAll(Collection c) {
return addAll(size, c);
}
3.2.2 addAll(int index, Collection c)
/**
* 在 index 节点前插入包含所有 c 集合元素的节点。
* 返回值表示是否成功添加了对应的元素.
*/
public boolean addAll(int index, Collection c) {
// 查看索引是否满足 0 =< index =< size 的要求
checkPositionIndex(index);
// 调用对应 Collection 实现类的 toArray 方法将集合转为数组
Object[] a = c.toArray();
//检查数组长度,如果为 0 则直接返回 false 表示没有添加任何元素
int numNew = a.length;
if (numNew == 0)
return false;
// 保存 index 当前的节点为 succ,当前节点的上一个节点为 pred
Node pred, succ;
// 如果 index = size 表示在链表尾部插入
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
// 遍历数组将对应的元素包装成节点添加到链表中
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node newNode = new Node<>(pred, e, null);
//如果 pred 为空表示 LinkedList 集合中还没有元素
//生成的第一个节点将作为头节点 赋值给 first 成员变量
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
// 如果 index 位置的元素为 null 则遍历数组后 pred 所指向的节点即为新链表的末节点,赋值给 last 成员变量
if (succ == null) {
last = pred;
} else {
// 否则将 pred 的 next 索引指向 succ ,succ 的 prev 索引指向 pred
pred.next = succ;
succ.prev = pred;
}
// 更新当前链表的长度 size 并返回 true 表示添加成功
size += numNew;
modCount++;
return true;
}
经过上边的代码注释可以了解到,LinkedList 批量添加节点的方法实现了。大体分下面几个步骤:
-
- 检查索引值是否合法,不合法将抛出角标越界异常
-
- 保存 index 位置的节点,和 index-1 位置的节点,对于单链表熟悉的同学一定清楚对于链表的增删操作都需要两个指针变量完成
-
- 将参数集合转化为数组,循环将数组中的元素封装为节点添加到链表中。
-
- 更新链表长度并返回添加 true 表示添加成功。
3.2.3 checkPositionIndex
对于 checkPositionIndex方法这里想顺带分析了,LinkedList 中有两个方法用于检查角标越界,内部实现一样,都是通过判断 index >= 0 && index < size 是否满足条件。
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Tells if the argument is the index of an existing element.
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
/**
* Tells if the argument is the index of a valid position for an
* iterator or an add operation.
*/
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
4 LinkedList 的增删改查
4.1 LinkedList 添加节点的方法
LinkedList 作为链表数据结构的实现,不同于数组,它可以方便的在头尾插入一个节点,而 add 方法默认在链表尾部添加节点:
4.1.1 addXXX
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
4.1.2 linkXXX
/**
* 添加一个元素在链表的头节点位置
*/
private void linkFirst(E e) {
// 添加元素之前的头节点
final Node f = first;
//以添加的元素为节点值构建新的头节点 并将 next 指针指向 之前的头节点
final Node newNode = new Node<>(null, e, f);
// first 索引指向将新的节点
first = newNode;
// 如果添加之前链表空则新的节点也作为未节点
if (f == null)
last = newNode;
else
f.prev = newNode;//否则之前头节点的 prev 指针指向新节点
size++;
modCount++;//操作数++
}
/**
* 在链表末尾添加一个节点
*/
void linkLast(E e) {
final Node l = last;//保存之前的未节点
//构建新的未节点,并将新节点 prev 指针指向 之前的未节点
final Node newNode = new Node<>(l, e, null);
//last 索引指向末节点
last = newNode;
if (l == null)//如果之前链表为空则新节点也作为头节点
first = newNode;
else//否则将之前的未节点的 next 指针指向新节点
l.next = newNode;
size++;
modCount++;//操作数++
}
除了上述几种添加元素的方法,以及之前在将构造的时候说明的 addAll 方法,LinkedList 还提供了 add(int index, E element); 方法,下面我们来看在这个方法:
4.1.3 add(int index, E element)
/**
* 在指定 index 位置插入节点
*/
public void add(int index, E element) {
// 检查角标是否越界
checkPositionIndex(index);
// 如果 index = size 代表是在尾部插入节点
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
可以先看到当 0 =< index LinkedList 查询节点的方法,可分为根据指定的索引查询,获取头节点,获取未节点三种。值得注意的是,根据索引去获取节点内容的效率并不高。 LinkedList 只提供了 set(int index, E element) 一个方法。 LinkedList提供根据角标查询节点的方法,LinkedList 还提供了一系列判断元素在链表中的位置的方法 分析完 LinkedList 作为 List 集合的增删改查操作,我们看下 LinkedList 是如何实现 Deque 接口的方法的: 我们来看下 Queue 给我们提供了的方法: 由于 Deque 接口继承 Queue 接口,当 Deque 当做队列使用时(FIFO),只需要在头部删除,尾部添加即可。 上述方法的区别对于 Queue 对应的实现类的对应方法,是一种规定,自己在实现 Queue 队列的时候也要遵循此规则。 我们通过下边的表格来对照下双端队列是如何实现队列操作的,值得注意的是 Deque 实现了 Queue,所以 Queue 所有的方法 Deque 都有,下面比较的是Deque区别 Queue 的方法: Queue的 offer 和 add 的区别针对容量有限制的实现,很明显 LinkedList 的大小并没有限制,所以在 LinkedList 中他们的实现并没有实质性不同。 上述我们分析了,双端队列作为队列使用的时候的各个方法的区别,也可是看出 LinkedList 对对应方法的实现,遵循了队列设计原则。 Stack 本身就是实现类,他拥有 FILO 的原则, Stack 的入栈操作通过 push 方法进行,出栈操作通过 pop 方法进行,查询操作通过 peek 操作进行。 由于分析队列的时候已经分析了addFist 和 removeFirst,peekFirst操作的方法了,下边我们来显 push 和 pop 的实现: 来看下 ListItr 的源码: Java容器类框架分析(1)ArrayList源码分析 可以看出 LinkedList 没有实现 RandomAccess 接口,我们知道RandomAccess 是一个空的标记接口,标志着实现类具有随机快速访问的特点。那么我们有必要重新认识下这个接口,根据 RandomAccess 的 Java API 说明: 公共接口 RandomAccess 标记接口用于List实现,以表明它们支持快速(通常是恒定时间)的随机访问。该接口的主要目的是允许通用算法改变其行为,以便在应用于随机或顺序访问列表时提供良好的性能。 我们可以意识到,随机访问和顺序访问之间的区别往往是模糊的。例如,如果列表很大时,某些 List 实现提供渐进的访问时间,但实际上是固定的访问时间,这样的 List 实现通常应该实现这个接口。作为一个经验法则, 如果对于典型的类实例,List实现应该实现这个接口: 比这个循环运行得更快: 我们来看下输出结果: 可以看出 LinkedList 的 for循环的确耗费时间很长,其实这并不难理解,结合上一篇我们分析 LinkedList 的源码的时候,看到的 get(int index)方法 : 搞懂 Java LinkedList 源码4.1.4 node(index)
/**
* 返回一个非空节点,这个非空节点位于 index 位置
*/
Node4.1.5 linkBefore(E e, Node
void linkBefore(E e, Node
4.2 LinkedList 删除节点的方法
4.2.1 removeXXX
/**
* 删除头节点
* @return 删除的节点的值 即 节点的 element
* @throws NoSuchElementException 如果链表为空则抛出异常
*/
public E removeFirst() {
final Node4.2.2 unlinkXXX
/**
* 移除头节点
*/
private E unlinkFirst(Node4.2.3 clear
/**
* Removes all of the elements from this list.
* The list will be empty after this call returns.
*/
public void clear() {
// 依次清除节点,帮助释放内存空间
for (Node4.3 LinkedList 查询节点的方法
/**
* 根据索引查询
*
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* 返回 first 索引指向的节点的内容
*
* @return the first element in this list
* @throws NoSuchElementException 如果链表为空则抛出异常
*/
public E getFirst() {
final Node4.4 LinkedList 的修改节点方法
public E set(int index, E element) {
// 判断角标是否越界
checkElementIndex(index);
// 采用 node 方法查找对应索引的节点
Node4.5 LinkedList 的元素查询方法
/*
* 返回参数元素在链表的节点索引,如果有重复元素,那么返回值为从**头节点**起的第一相同的元素节点索引,
* 如果没有值为该元素的节点,则返回 -1;
*
* @param o element to search for
* @return
*/
public int indexOf(Object o) {
int index = 0;
// 区别对待 null 元素,用 == 判断,非空元素用 equels 方法判断
if (o == null) {
for (Node
public boolean contains(Object o) {
return indexOf(o) != -1;
}
5 LinkedList 作为双向队列的增删改查
5.1 Deque 双端队列
头部
头部
尾部
尾部
插入
addFirst(e)
offerFirst(e)
addLast(e)
offerLast(e)
移除
removeFirst()
pollFirst()
remveLast()
pollLast
获取
getFirst()
peekFirst()
getLast()
peekLast
Queue
Deque
add(e)
addLast()
offer(e)
offerLast()
remove()
removeFirst()
poll()
pollFirst()
element()
getFirst()
peek()
peekFirst()
5.1 Deque 和 Queue 添加元素的方法
// queue 的添加方法实现,
public boolean add(E e) {
linkLast(e);
return true;
}
// Deque 的添加方法实现,
public void addLast(E e) {
linkLast(e);
}
// queue 的添加方法实现,
public boolean offer(E e) {
return add(e);
}
// Deque 的添加方法实现,
public boolean offerLast(E e) {
addLast(e);
return true;
}
5.2 Deque 和 Queue 获取队列头部元素的实现
// Queue 获取队列头部的实现 队列为空的时候回抛出异常
public E element() {
return getFirst();
}
// Deque 获取队列头部的实现 队列为空的时候回抛出异常
public E getFirst() {
final Node5.3 Deque 和 Queue 删除元素的方法
// Queue 删除元素的实现 removeFirst 会抛出 NoSuchElement 异常
public E remove() {
return removeFirst();
}
// Deque 的删除方法实现
public E removeFirst() {
final Node6 双端队列作为栈 Stack使用的时候方法对应关系
Deque作为栈使用的时候,也遵循 FILO 准则,入栈和出栈是通过添加和移除头节点实现的。
Stack
Deque
push(e)
addFist(e)
pop()
removeFirst()
peek()
peekFirst()
public void push(E e) {
addFirst(e);
}
public E pop() {
return removeFirst();
}
7 LinkedList 的遍历
private class ListItr implements ListIterator8 ArrayList 与 LinkedList 的区别
我们先回过头来看下,这两个 List 的继承体系有什么不同:public class ArrayListpublic class LinkedList
for(int i = 0,n = list.size(); i for(Iterator i = list.iterator(); i.hasNext();)
i.next();
8.1 测试一下
private static void loopList(ListArrayList使用普通for循环遍历时间为6ms
ArrayList使用iterator 循环遍历时间为4ms
LinkedList使用普通for循环遍历时间为133ms
LinkedList使用iterator 循环遍历时间为2ms
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
参考