说明
作业并不是完全按照老师的要求实现的,一方面是因为58同城改版后很少有普通商品,另一方面是想多做一些基础语法的练习,但整体上还是抓取网页并解析商品信息的思路。
程序当中注释比较多,这里就不在整体描述编程思路。
代码
#coding=utf-8
'''提取58同城二手市场中的板块商品信息(包括格式严格的推广和转转商品,以及格式不规范的普通商品(粗粒度)),按照板块保存到本地文件'''
from bs4 import BeautifulSoup
import requests,os,time
#############################################################################
def get_block_info(host):
'''从首页中提取二手市场下板块信息'''
resp = requests.get(host)
soup = BeautifulSoup(resp.text,'lxml')
#二手市场下分类板块,如果使用' div > div > em > a' 路径的话可以提取所有二级板块信息
blocks = soup.select(' div.fl.cbp2.cbhg > div > em > a')
#存放二手市场下区块的列表,每个区块为一个字典
blocklist = []
for block in blocks:
href = block['href']
if href.startswith('/') and href.endswith('/'):
href = href.split('/')[1]
data ={
'name' : block.string, #区块中文名称
'block' : href, #区块命名
'block_url' : host+href #拼接区块url
}
blocklist.append(data)
return blocklist
#############################################################################
def get_goods_infos(pageurl):
'''传入一个列表页面url,提取页面当中所有商品信息
由于转转,推广商品的信息格式规范,可以分类提取
普通商品格式不一致,无法详细提取各类信息,且会和转转,推广商品重复,故这里只有在获取不到以上两类商品时,按粗粒度获取所有商品信息'''
resp = requests.get(pageurl)
soup = BeautifulSoup(resp.text, 'lxml')
time.sleep(1) # 停顿一秒,降低访问频率
#一个存储区块单个页面商品信息的数据结构:{[推广商品信息列表],[转转商品信息列表],{前两者获取不到时获取所有商品信息}}
info_of_single_page = {}
#获取正规格式的推广商品信息
jz_infos = [] # 存储单个页面推广商品信息的列表
jz_titles = soup.select(' tr.jztr > td.t > a.t')
jz_times = soup.select('tr.jztr > td.t > span.fl')
jz_prices = soup.select('tr.jztr > td.tc > b')
jz_descs = soup.select('tr.jztr > td.t > span.red_adinfo')
jz_areas = soup.select(' tr.jztr > td.t > span.fl > a')
for jz_title,jz_time,jz_price,jz_desc,jz_area in zip(jz_titles,jz_times,jz_prices,jz_descs,jz_areas):
jzdata = { #单条推广商品信息字典
'商品名称' : jz_title.get_text(),
'商品链接': jz_title.get('href'),
'发布时间' : jz_time.get_text().split('/')[1].strip(),
'价格' : jz_price.get_text(),
'描述' : jz_desc.get_text(),
'区域' : jz_area.get_text()
}
jz_infos.append(jzdata)
info_of_single_page['jzgoods'] = jz_infos
#获取正规格式的转转商品信息
zz_infos = [] # 存储单个页面转转商品信息的列表
zz_titles = soup.select(' tr.zzinfo > td.t > a.t')
zz_prices = soup.select(' tr.zzinfo > td.t > span.pricebiao > span')
zz_descs = soup.select(' tr.zzinfo > td.t > span.desc')
zz_areas = soup.select(' tr.zzinfo > td.t > span.fl ')
zz_posters = soup.select('tr.zzinfo > td.tc > div > p:nth-of-type(2)')
for zz_title, zz_price, zz_desc, zz_area,zz_poster in zip(zz_titles, zz_prices, zz_descs, zz_areas,zz_posters):
zzdata = { #单条转转商品信息字典
'商品名称': zz_title.get_text(),
'商品链接': zz_title.get('href'),
'价格': zz_price.get_text(),
'描述': zz_desc.get_text(),
'区域': ''.join(list(zz_area.stripped_strings)),
'发布者' : zz_poster.get_text()
}
zz_infos.append(zzdata)
info_of_single_page['zzgoods'] = zz_infos
#由于部分板块记录格式不规范,无法区分推广和转转商品,故在以上两个列表未获取数据时,使用粗粒度获取记录普通商品信息
goods_infos = []
if len(jz_infos) == 0 and len(zz_infos) == 0:
titles = soup.select(' tr > td.t > a.t')
prices = soup.select(' b.pri')
for title,price in zip(titles,prices):
data ={
'商品名称' : title.get_text(),
'商品链接' : title.get('href'),
'商品价格' : price.string
}
goods_infos.append(data)
info_of_single_page['goods'] = goods_infos
return info_of_single_page #返回存放商品信息的列表
#############################################################################
def save_goods_infos2files(filepath,goodsinfolist):
'''传入一个文件名及一个列表,将商品信息按照区块创建不同文件续写到对应文件中
filepath为要创建的文件路径
goodsinfo是单个页面获取到的商品信息列表'''
#列表为空则跳出函数(部分页面没有推广信息)
if len(goodsinfolist) == 0:
return
#如果没有区块目录则创建之
blockpath = os.path.split(filepath)[0]
if not os.path.exists(blockpath):
os.makedirs(blockpath)
#创建商品文件并写入数据
with open(filepath,'a',encoding='utf-8') as f:
for item in goodsinfolist:
f.write(str(item)+'\n')
#############################################################################
if __name__ == '__main__':
host = 'http://bj.58.com/'
blocklist = get_block_info(host)
for block in blocklist:
#由于58同城只给用户访问前70页的内容,因此这里生成70个页面的url进行访问(测试程序可将可访问页数设小一些)
invaid_page_num = 5
for pageurl in [block['block_url']+'/pn{}'.format(str(idx + 1)) for idx in range(invaid_page_num)]:
#解析每个页面的商品信息
info = get_goods_infos(pageurl)
for k,v in info.items():
filepath = './{}/{}.txt'.format(block['name'], k)
#讲每个页面的商品信息分类续写到对应目录及文件中
save_goods_infos2files(filepath, v)
执行结果
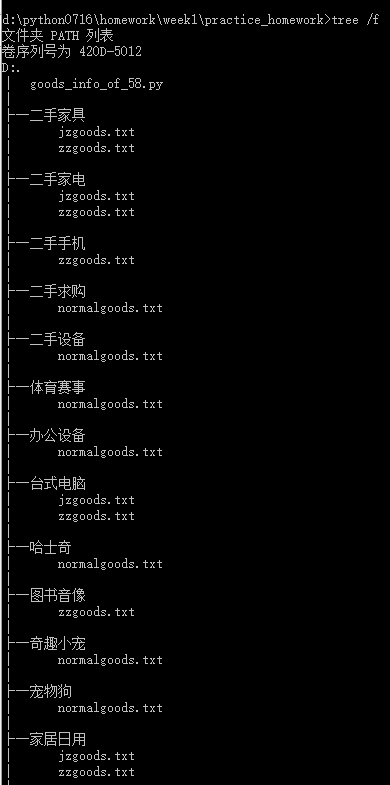
Paste_Image.png
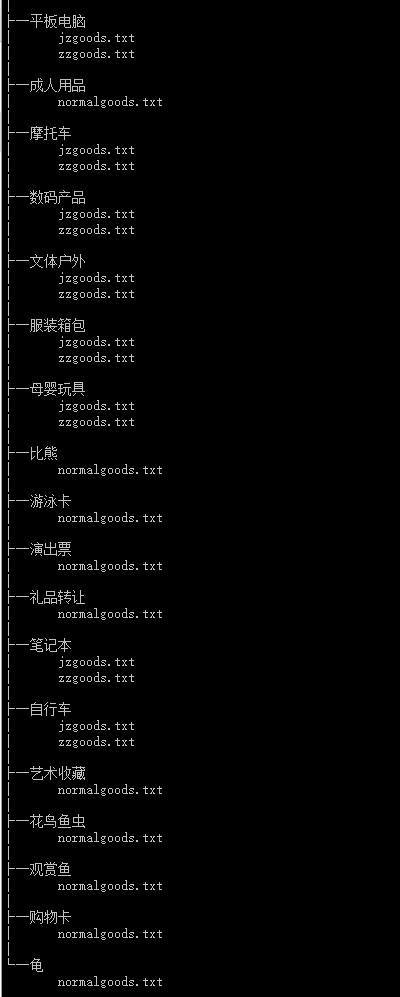
Paste_Image.png
小结
1.css path是否是全路径没有关系,只要能唯一定位目标tag即可。-done
2.当前的网页信息获取属于定制模板,网站稍作改版或者被解析数据项不规范即会造成解析失败,有没有更加通用的解析方式?-learning
a.通用解析可能只适用于粗粒度信息获取,譬如网页标题,文本等?
b.想要获取精细结构化数据必须得针对网站进行模板解析?
ps:以上问题后续学习继续探索
3.编码中变量命名要简单明了,格式统一,目前这点做的不好,很多变量名称指示性不强,且格式不太统一,后续编码要注意。-learning
4.关于函数的设置,要注意通用性,切忌为了将代码划分为多个函数而设计出只有当前需求可以使用函数。故函数的参数要尽量是基本数据类型。-learning
5.pycharm代码直接拷贝到编辑器时,由于换行编码不一样,不会显示换行。可以使用其他文本编辑器中转一下,譬如notepad。-done
6.BeautifulSoup集中解析模式的异同需要花时间看看。-leaning
7.