一、写在前面
我在以前写过一次12306网站的爬虫,当时实现了模拟登录和查询车票,但是感觉还不太够,所以对之前的代码加以修改,还实现了一个订购车票的功能。
二、主要思路
在使用Selenium做模拟登录12306网站的时候,需要将登录成功后的Cookie保存下来,这个Cookie在后面是必需的。然后就是在12306网站上查票订票,同时使用Fiddler软件进行抓包,通过分析得到订票所需的十多个请求,只要依次发送这些请求,在请求成功之后就能够订到票。
三、模拟登录
之前的代码已经基本实现了模拟登录的功能,但是还没法得到想要的Cookie,所以需要对之前的代码进行改进。虽然Selenium模块提供了get_cookies()方法,但是使用这个方法得到的是当前会话的Cookie,也就是Selenium开启的浏览器中当前页面的Cookie,这个Cookie和本地浏览器中的Cookie是不同的。如下是从本地Chrome中拷贝的Cookie,其中以_jc_save开头的字段都是之前查询车票的记录,而其余字段都是生成的:
JSESSIONID=A318817EEE594DE954CE352761DF4CD7;
_jc_save_fromStation=%u6B66%u6C49%2CWHN;
_jc_save_wfdc_flag=dc;
_jc_save_toStation=%u4E0A%u6D77%2CAOH;
RAIL_EXPIRATION=1560095439082;
RAIL_DEVICEID=P2wunHEkKFe9MgTM56h-NxsWiIGNkK6JLCOVaG0DHzRm-RxYa7YnDwftPoumiZ0wL7GPsQ93YBHRHgMgB_GLWwZ9Vb65tNiVuwaIOytW8lVG7B1KopI4pSyUr1u06RWpKPhvExBg3FA7ed87WxO3E-68Wg-hXZLl;
_jc_save_fromDate=2019-06-30;
_jc_save_toDate=2019-06-06;
_jc_save_showIns=true;
route=495c805987d0f5c8c84b14f60212447d;
BIGipServerotn=300941834.24610.0000;
BIGipServerpool_passport=250413578.50215.0000
下面是使用Selenium模块的get_cookies()方法得到的Cookie,可以看到和浏览器中的Cookie有很大不同,缺少了很多字段:
[{'domain': 'kyfw.12306.cn', 'httpOnly': False, 'name': 'JSESSIONID', 'path': '/otn', 'secure': False, 'value': '672BAF8C694C50C49D3EFFCF9913A745'},
{'domain': 'kyfw.12306.cn', 'httpOnly': False, 'name': 'route', 'path': '/', 'secure': False, 'value': 'c5c62a339e7744272a54643b3be5bf64'},
{'domain': 'kyfw.12306.cn', 'httpOnly': False, 'name': 'BIGipServerotn', 'path': '/', 'secure': False, 'value': '1139802634.24610.0000'}]
解决办法是使用add_cookie()方法向Selenium开启的Chrome中添加Cookie,达到模拟本地浏览器的效果,最终就能登录成功。在登录成功之后,要获取此时的Cookie,除了使用get_cookies()方法或者get_cookie()方法,还可以使用如下语句:
cookie = browser.execute_script("return document.cookie;")
不过为了验证是否真的登录成功了,还需要进行一下测试,验证是否登录成功的方法如下代码,这段代码会发送一个请求,请求的结果中包含了是否登录信息(即is_login)和用户名等信息:
1 def get_name(self):
2 """
3 获取用户姓名
4 :return:
5 """
6 url = "https://kyfw.12306.cn/otn/login/conf"
7 res = requests.post(url, headers=self.headers)
8 is_login = res.json()['data']['is_login']
9 if is_login == 'Y':
10 self.name = res.json()['data']['name']
11 print("欢迎用户:{}".format(self.name))
12 else:
13 print("未登录!请先登录。")
在这推荐下小编创建的Python学习交流群835017344,可以获取Python入门基础教程,送给每一位小伙伴,这里是小白聚集地,每天还会直播和大家交流分享经验哦,欢迎初学和进阶中的小伙伴。

四、订购车票
由于查询车票之前就已经做过了,所以这里就不再赘述。这里就说查询车票之后的操作,首先是在12306网站上查余票,然后选择一个车次点击预订,就会跳转到如下页面:
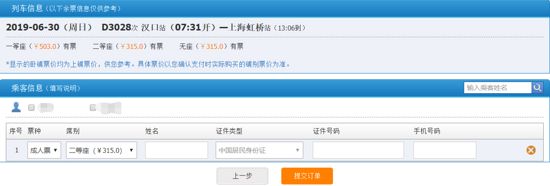
在这个页面上可以选择乘客、选择座位类型,然后再提交订单。这里虽然我们可以使用开发者工具然后刷新页面来抓包,但是为了避免遗漏掉某些请求,所以我选择使用Fiddler软件抓包,最终经过分析实践得到12个请求,其url和对应的含义如下图所示:

这里我并不打算把所有的请求都说一遍,我会将几个重要的请求拿出来描述,这些请求所使用的headers都是一样的,其中包含了登录后的Cookie,如果Cookie失效就会导致订票失败。
1.初始化页面
首先是initDc这个请求,在这个请求的结果中包含了后面请求所必需的一个参数--token(如下图),获取的方法也比较简单,可以直接使用正则表达式进行匹配:
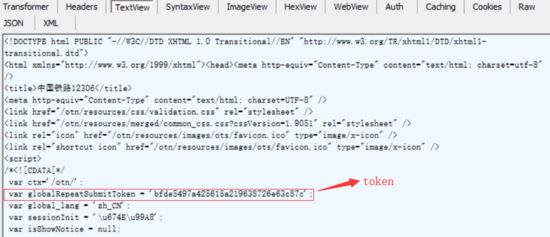
初始化页面获取token的代码如下:
1 # 初始化,获取token值
2 def init_dc():
3 global token
4 url = "https://kyfw.12306.cn/otn/confirmPassenger/initDc"
5 data = {
6 "_json_att": ""
7 }
8 res = requests.post(url, headers=headers, data=data)
9 result = re.findall(" var globalRepeatSubmitToken = '(.*?)';", res.text)
10 # print(result)
11 if len(result):
12 token = result[0]
13 else:
14 raise Exception("Error init")
2.提交车票预订信息
其次是提交车票预订信息,在Fiddler中点击Inspectors,然后选择WebForms,可以看到如下图所示信息,其中包含了出发城市、目的城市、出发日期等:
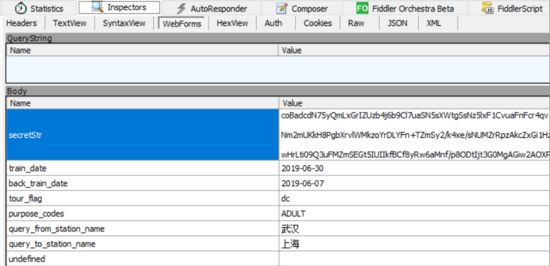
需要注意的是secretStr这个加密字符串,其来源于查询车票时的结果,在结果中每一条车次信息中都包含了一个字符串,不过这两个字符串并不完全一样。如下图所示就是两个字符串的对比,要得到加密字符串只需要使用unquote()方法:

3.确认订单信息
在选择完车次、座位类型、乘客之后会生成一个订单,然后就会发送一个确认订单信息的请求,其中包含了很多重要的信息。这里我放上该部分的代码:
1 # 确认订单信息
2 def check_order_info(name, uid, mobile, type_id):
3 # 商务座,一等座,二等座,软卧,硬卧,硬座
4 type_str = ["9,0,1,", "M,0,1,", "O,0,1,", "4,0,1,", "3,0,1,", "1,0,1,"][type_id]
5 url = "https://kyfw.12306.cn/otn/confirmPassenger/checkOrderInfo"
6 data = {
7 "json_att": "",
8 "bed_level_order_num": "000000000000000000000000000000",
9 "cancel_flag": "2",
10 "oldPassengerStr": name + ",1," + uid + ",1",
11 "passengerTicketStr": type_str + name + ",1," + uid + "," + mobile + ",N",
12 "REPEAT_SUBMIT_TOKEN": token,
13 "randCode": "",
14 "tour_flag": "dc",
15 "whatsSelect": "1"
16 }
17 res = requests.post(url, headers=headers, data=data)
18 # print(res.text)
这个方法包含了四个参数,name、uid和mobile分别表示乘客的姓名、身份证号和电话号码,这三个值都是在获取乘客信息时得到的,第四个参数是座位类别id。在这个请求携带的参数中有一个REPEAT_SUBMIT_TOKEN,这就是前面说过的token,由于我已经将token设置为了全局变量,所以这里就不用作为参数传到方法里了。要注意的是每个座位类别对应的字符是不同的,我通过在页面上选择元素得到了每个座位类型对应的字符,最后生成一个列表,然后通过改变座位类别id就能完成选择座位类别的功能。

4.提交预订请求
在确认订单之后就是提交预订请求,还是在Fiddler软件中找到这个请求,然后查看其携带的参数,如下图所示:
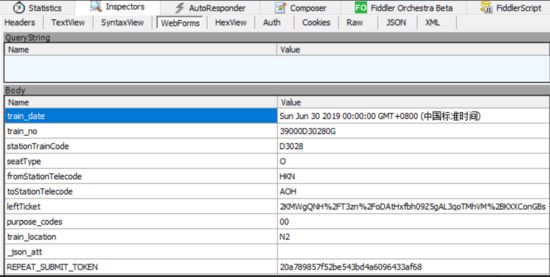
其中包含了车次编码、出发站编码、目的站编码、token等信息,这些编码信息都可以在查询车票的结果中得到,需要注意的是train_date,可以看到这是一个日期信息,而且是一个格林威治标准时间,要得到这个时间可以使用如下方法,这就能将日期转变成格林威治标准时间:
train_date = datetime.datetime.strptime(train_date, "%Y-%m-%d").date()
this_date = train_date.strftime("%a+%b+%d+%Y")
5.检查提交状态
在提交预订请求之后,需要检查提交状态,这个请求包含了很多参数,其中一些参数的值都包含在提交预订请求的结果中,除此之外这些参数还有乘客姓名、身份证号、乘客电话、token等。这个请求返回的结果中有一个submitStatus,需要提取出来,该值表明了提交是否成功。该部分的代码如下所示:
1 # 检查提交状态
2 def confirm(key_check, left_ticket, passenger_name, passenger_id, passenger_mobile, location, type_id):
3 # 商务座,一等座,二等座,软卧,硬卧,硬座
4 type_str = ["9,0,1,", "M,0,1,", "O,0,1,", "4,0,1,", "3,0,1,", "1,0,1,"][type_id]
5 url = "https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue"
6 data = {
7 "choose_seats": "",
8 "dwAll": "N",
9 "key_check_isChange": key_check,
10 "leftTicketStr": left_ticket,
11 "oldPassengerStr": passenger_name + ",1," + passenger_id + ",1_",
12 "passengerTicketStr": type_str + passenger_name + ",1," + passenger_id + "," + passenger_mobile + ",N",
13 "purpose_codes": "00",
14 "randCode": "",
15 "REPEAT_SUBMIT_TOKEN": token,
16 "roomType": "00",
17 "seatDetailType": "000",
18 "train_location": location,
19 "whatsSelect": "1",
20 "_json_att": "", }
21 res = requests.post(url, headers=headers, data=data)
22 try:
23 js = json.loads(res.text)
24 status = js["data"]["submitStatus"]
25 # print(status)
26 return status
27 except Exception as e:
28 print(e)
29 raise Exception("Confirm Error!")
6.排队等待
当我们的订单提交成功之后,就需要排队等待了,此时会发送一个请求,该请求中携带了一个时间戳参数(random),如下图所示:
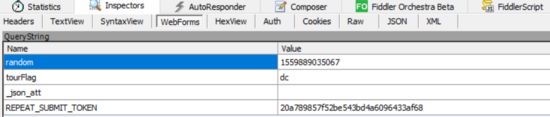
这是一个十三位的时间戳,在Python中可以使用 int(time() * 1000) 得到十三位时间戳。需要注意的是排队等待的结果是不确定的,正确的结果如下图所示:
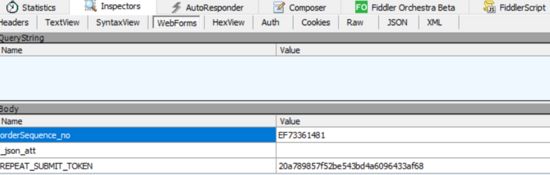
其中有一个orderId,这个值是我们需要的。如果返回的结果中不包含orderId,就需要重新发送请求。
7.请求预订结果
在得到orderId之后,就可以请求预订结果了,请求无误的话就能够成功订到票了。下图是在Fiddler软件中截到的图,其中EF73361481就是前面得到的orderId:
五、运行结果
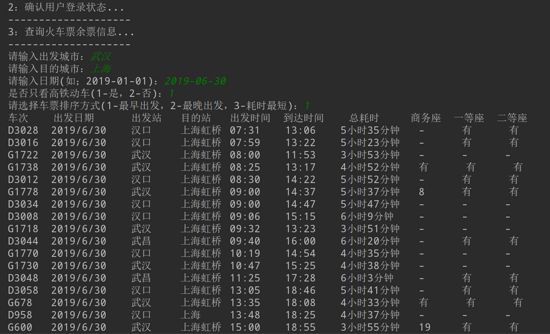
下图是在Pycharm中的运行截图,在登录成功之后查询余票,将查询的结果显示出来:
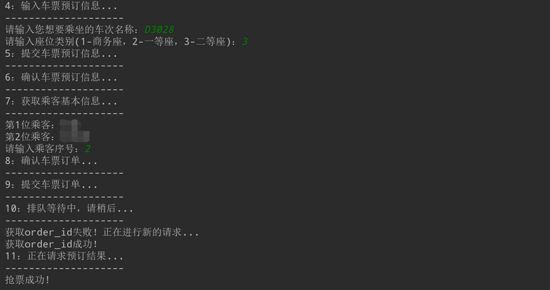
查询车票之后就是预订车票,需要输入车次名称、座位类别和选择乘客,然后提交订单,最终成功订到火车票。
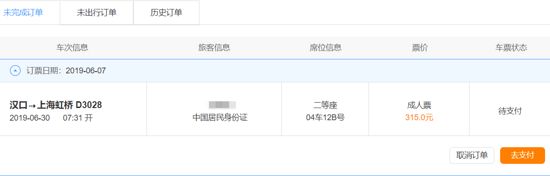
订票成功之后,进入12306网站进行查看,可以看到成功订到票了, 如下图所示:
完整代码已上传到 GitHub !如果觉得有用的话给我点个Star吧!