智能决策上手系列教程索引
继续上一篇:数据处理-招聘信息-中文分词与词频统计
我们得到了很多的关键词,'算法', '学习', 'python', '熟悉', '人工智能', '经验', '优先', '职位', '机器', '相关',...,其中明显的,'熟悉'、'职位'、'优先'、'相关'这些词是绝对没有意义的。我们可以把它过滤掉。
如果您还没有抓取,请从这里直接下载100个json搁置职位文件 密码:tfdv
全部代码如下(注意文件目录需要修改):
#cell-1
import jieba
def readDetail(fileName):
with open(fileName, 'r') as f:
job = json.load(f)
details = job['details'].lower()
details = details.replace(' ', '').replace('\xa0', '')
return details
import os
#cell-2
text = ''
files = os.listdir('./data/lagou_ai/jobs1000/')
jobCount = 0
for n in range(0, 1000):
if not files[n].find('.json')==-1:
details = readDetail('./data/lagou_ai/jobs1000/' + files[n])
if details.find('python') != -1 or details.find('tensorflow') != -1:
jobCount += 1
text += details
print('>>Got jobs:', jobCount)
#cell-3
import jieba.analyse
import pandas as pd
result=[]
for word, weight in jieba.analyse.extract_tags(text, topK=100, withWeight=True):
result.append(word)
print(result)
去掉冗余单词
上面代码可以输出所有的关键词数组。我们复制它,把多余的单词删除。比如我选了28个:
mylist = [ '算法', 'python', '经验', '机器', '深度', 'java', 'c++', '数据挖掘', '自然语言', '编程','数据分析', '数学', 'linux', 'nlp', 'tensorflow', 'spark', '文本', '硕士', 'hadoop', 'caffe', '视觉', '本科', '语音', '语义', '问题', '神经网络', '数据结构', '图像']
我们添加两个列表用于存放words和weights,修改cell-3代码如下:
import jieba.analyse
import pandas as pd
keywords = []
weights=[]
mylist = [
'算法', 'python', '经验', '机器', '深度', 'java', 'c++', '数据挖掘', '自然语言', '编程',
'数据分析', '数学', 'linux', 'nlp', 'tensorflow', 'spark', '文本', '硕士', 'hadoop',
'caffe', '视觉', '本科', '语音', '语义', '问题', '神经网络', '数据结构', '图像'
]
for word, weight in jieba.analyse.extract_tags(
text, topK=100, withWeight=True):
if word in mylist:
keywords.append(word)
weights.append(weight)
print(keywords,weights)
运行后可以输出两个列表['算法', 'python', '经验', '机器', ...] [0.16280807037359346, 0.09640941534596774, ...
使用图表展示
我们使用图形化插件plotly,plot英文是绘制图表的意思,官方站点帮助文档点这里。
命令行安装:
conda install -f plotly
然后我们增加一个cell-4,使用下面代码:
#cell-4
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode(connected=False)
plotly.offline.iplot({
"data": [go.Scatter(x=keywords, y=weights)],
"layout": go.Layout(title="拉勾网人工智能职业关键词分布")
})
几点说明:
- 我们使用的是offline版本,plotly默认是online在线版本,你需要到它的官网注册账号进行设置等等,麻烦一些,但也可以获得更强大功能。
- 另外,这里使用的是
iplot(...)而不是很多教程中看到的plot(...),这是因为我们需要在Jupyter Notebook中直接显示图表。 - go是graph object绘图对象的意思,go.Scatter是绘制折线图,x和y是横向和竖向的坐标list列表。
运行后得到下图(如果你的没有出现图而是出现一块空白,请尝试刷新页面再试):
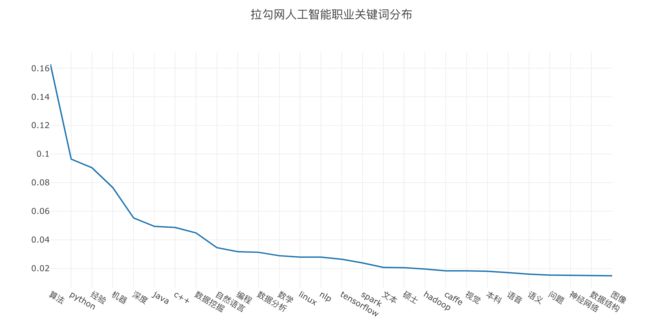
改为柱状图
稍微调整一下,用go.Bar我们就可以换为更容易理解的柱状图:
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode(connected=False)
plotly.offline.iplot({
"data": [go.Bar(x=keywords, y=weights)],
"layout": go.Layout(title="拉勾网人工智能职业关键词分布")
})
输出得到:

合并同类词义
我们注意到自然语言和nlp其实是一回事, 文本、语义也和它们直接相关;另外深度(学习)和神经网络也基本一个意思,同样的还有数据分析和数据挖掘,图像和视觉,我们把它们合并一下。
在上面添加一个新的cell-3.5,代码如下:
def mergeItem(wd1,wd2):
newkey=wd1+'+'+wd2
n1=keywords.index(wd1)
keywords[n1]=newkey
n2=keywords.index(wd2)
weights[n1]=weights[n1]+weights[n2]
del weights[n2]
del keywords[n2]
return newkey
mergeItem('神经网络','深度')
mergeItem('数据分析','数据挖掘')
mergeItem('图像','视觉')
a=mergeItem('自然语言','nlp')
a=mergeItem(a,'文本')
a=mergeItem(a,'语义')
mergeItem的思路是先找到两个单词在列表中的位置n1,n2,然后做单词拼合或者数字加法,最后再把第二个单词删除。
从cell-3开始往下运行(或者全部运行),得到如下图:

重新排序
上这个图的顺序有些乱,我们需要重新拍了一下。
在图表cell-4前面添加cell-3.8
comb=zip(keywords,weights)
def comp(item):
return item[1]
comb=sorted(comb,reverse=True,key=comp)
keywords=[v for v,_ in comb]
weights=[v for _,v in comb]
这个代码虽然少但是比较难说明:
- 首先我们有keywords和weights两个数组,顺序一一对应,我们不能随便的把它们单独排序,那就乱掉了。
-
zip方法是把两个数组合并成一个由元组构成的新数组,举个例子就是comb=zip(['a','b'],[1,2])就得到了comb是[('a',1),('b',2)],可以用下面代码测试这个效果:a=['a','b'] b=[1,2] c=zip(a,b) for m in c: print(m) -
sorted(...)可以对元组构成的列表进行排序,它不仅可以把[('a',10),('b',8)]排成[('b',8),('a',10)],甚至能排[('a',9,100),('b',2,300)]这样的三维元组数组。 - 那么问题来了,两维元组或者三维元组要排序,先参照第一个元素排呢?第一个a或b,第二个9或10,第三个100或300?能不能直接按照第二个排呢?
-
sorted(...,key=...)这个key就是优先参照的元素,但要用一个函数comb来表示,这个函数接受一个参数def comb(item),返回一个元素return item[1]。 - 排完序还要把
[('a',1),('b',2)]拆解成['a','b'],[1,2],我们用了一个简写的for循环[v for v,_ in comb]直接返回了comb中每个元组的第一个元素。v,_是只取第一个,忽略第二个,同理,_,v是只取第二个,忽略第一个。[关于下划线更多用法看这里](Python中下划线的作用-_.
从cell-3重新往下运行所有代码,得到如下图:
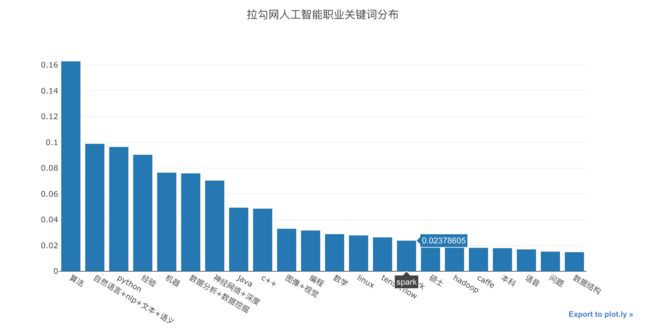
关于lambada
单独定义的函数def comb(...)还可以用lambada简写
def comp(item):
return item[1]
comb=sorted(comb,reverse=True,key=comp)
合并为
comb=sorted(comb,reverse=True,key=lambda k:k[1])
从上面看出,lambda 参数:返回值,对应于def hanshu(参数):return 返回值这样的格式。
全部代码
下面是全部代码:
#cell-1 定义读取文件方法
import jieba
def readDetail(fileName):
with open(fileName, 'r') as f:
job = json.load(f)
details = job['details'].lower()
details = details.replace(' ', '').replace('\xa0', '')
return details
#cell-2 读取全部文件
import os
text = ''
files = os.listdir('./data/lagou_ai/jobs1000/')
jobCount = 0
for n in range(0, 1000):
if not files[n].find('.json')==-1:
details = readDetail('./data/lagou_ai/jobs1000/' + files[n])
if details.find('python') != -1 or details.find('tensorflow') != -1:
jobCount += 1
text += details
print('>>Got jobs:', jobCount)
#cell-3 关键词提取和去除冗余
import jieba.analyse
import pandas as pd
keywords = []
weights=[]
mylist = [
'算法', 'python', '经验', '机器', '深度', 'java', 'c++', '数据挖掘', '自然语言', '编程',
'数据分析', '数学', 'linux', 'nlp', 'tensorflow', 'spark', '文本', '硕士', 'hadoop',
'caffe', '视觉', '本科', '语音', '语义', '问题', '神经网络', '数据结构', '图像'
]
for word, weight in jieba.analyse.extract_tags(
text, topK=100, withWeight=True):
if word in mylist:
keywords.append(word)
weights.append(weight)
print(keywords,weights)
#cell-3.5 合并同类词
def mergeItem(wd1,wd2):
newkey=wd1+'+'+wd2
n1=keywords.index(wd1)
keywords[n1]=newkey
n2=keywords.index(wd2)
weights[n1]=weights[n1]+weights[n2]
del weights[n2]
del keywords[n2]
return newkey
mergeItem('神经网络','深度')
mergeItem('数据分析','数据挖掘')
mergeItem('图像','视觉')
a=mergeItem('自然语言','nlp')
a=mergeItem(a,'文本')
a=mergeItem(a,'语义')
#cell-3.8 重新排序
comb=zip(keywords,weights)
comb=sorted(comb,reverse=True,key=lambda k:k[1])
keywords=[v for v,_ in comb]
weights=[v for _,v in comb]
#cell-4 绘图视觉化
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode(connected=False)
plotly.offline.iplot({
"data": [go.Bar(x=keywords, y=weights)],
"layout": go.Layout(title="拉勾网人工智能职业关键词分布")
})
智能决策上手系列教程索引
每个人的智能决策新时代
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~
END