blog.csdn.net/jesse_mx/article/details/53925356
blog.csdn.net/hysteric314/article/details/53909408 (主要看了这个)
YOLO一代确实回归出的是中心点的坐标以及宽高(x,y,w,h)
端到端(End-to-End)的目标检测方法,这些方法无需区域提名,包括YOLO和SSD。
V1原理:YOLO的全拼是You Only Look Once,顾名思义就是只看一次,进一步把目标判定和目标识别合二为一,所以识别性能有了很大提升,达到每秒45帧,而在快速版YOLO(Fast YOLO,卷积层更少)中,可以达到每秒155帧。
网络的整体结构如图14所示,针对一张图片,YOLO的处理步骤为(其实算是测试步骤啦):
(1) 把输入图片缩放到448×448大小;
(2) 运行卷积网络(将图片切成S × S 的网格,最后预测的结果就是 S × S×(5*B+20),每个格子只去预测一个物体位置以及类别);
(3) 对模型置信度卡阈值,得到目标位置与类别(位置就是(x,y,w,h),(x, y)代表与格子相关的box的中心。(w, h)为与全图信息相关的box的宽和高)。

网络的模型如图15所示,将448×448大小的图切成 S × S 的网格,目标中心点所在的格子负责该目标的相关检测,每个网格预测 B 个边框及其置信度,以及 C 种类别的概率。YOLO中 S =7, B =2, C 取决于数据集中物体类别数量,比如VOC数据集就是 C =20。对VOC数据集来说,YOLO就是把图片统一缩放到448×448,然后每张图平均划分为7×7=49个小格子,每个格子预测2个矩形框及其置信度,以及20种类别的概率。

优点:
(1)YOLO简化了整个目标检测流程,速度的提升也很大
(2)YOLO采用全图信息来进行预测。与滑动窗口方法和region proposal-based方法不同,YOLO在训练和预测过程中可以利用全图信息。Fast R-CNN检测方法会错误的将背景中的斑块检测为目标,原因在于Fast R-CNN在检测中无法看到全局图像。相对于Fast R-CNN,YOLO背景预测错误率低一半。
(3)YOLO可以学习到目标的概括信息(generalizable representation),具有一定普适性。我们采用自然图片训练YOLO,然后采用艺术图像来预测。YOLO比其它目标检测方法(DPM和R-CNN)准确率高很多。
但是YOLO还是有不少可以改进的地方,比如 S × S 的网格就是一个比较启发式的策略,如果两个小目标同时落入一个格子中,模型也只能预测一个;另一个问题是Loss函数对不同大小的bbox未做区分。
注意:该网络的训练,应该是训练样本输入也是对应测试样本那样,划分成SxS的网格,每个网格预测B个框,巴拉巴拉,之类的
补充:blog.csdn.net/hx921123/article/details/55802795(写的还行)以及
zhuanlan.zhihu.com/p/25045711 中的训练方法
V2原理(这是我曾经讲过的论文turn4,见PPT即可)
效果:VOC 2007 of 78.6%, 48.1% on COCO test-dev
实践:/home/echo/darknet
/pjreddie.com/darknet/yolo/
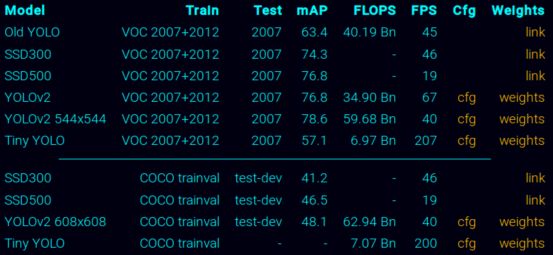
由上到下的模型:
用md5sum + 文件名发现:YOLOv2的weights的文件与YOLOv2 544x544的weights文件一样的(都是yolo-voc.weights),果真!!他们的cfg都是yolo-voc .cfg
Tiny YOLO 对应的weights是tiny-yolo-voc .weights(暂时不知与上面的区别,也罢)
YOLOv2 608x608对应的weights是yolo.weights,对应cfg是yolo .cfg,与VOC的不一样(因为输出就是不一样的)
命令:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
./darknet detector test cfg/coco.data cfg/yolo.cfg yolo.weights data/dog.jpg
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg -thresh 0
Tiny YOLO is based off of the Darknet reference network and is much faster but less accurate than the normal YOLO model. To use the version trained on VOC:
GPU上面>200帧
Compiling With CUDA
pjreddie.com/darknet/install/#cuda
Training YOLO on VOC
首先生成训练集与测试集以及训练验证集的图片路径的.txt文件:scripts/voc_label.py
直接按照里面步骤,利用darkNet 即可去检测
一步一步去做,只是我现在还没有必须用到,所以就简单的跟着理解,跟着跑了一下