
以上每一种方法都可能需要大量的时间来完成,而且你并不能保证采用的而方法是否真的有效,因此,就要利用机器学习诊断,机器学习诊断也可排除以上大部分的bug原因。

评估假设
如何评估我们的假设是否合适?通过误差最小我们可以证明假设较好,但是误差较小并不能说明假设的好坏,因为可能存在过拟合。对于过拟合,我们可以通过绘制模型图像来判断,但是当存在很多特征的时候,不太可能绘制出图像。
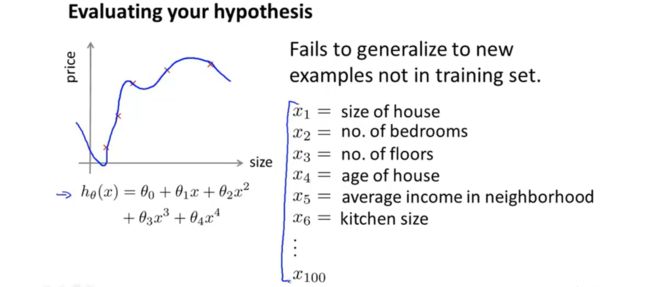
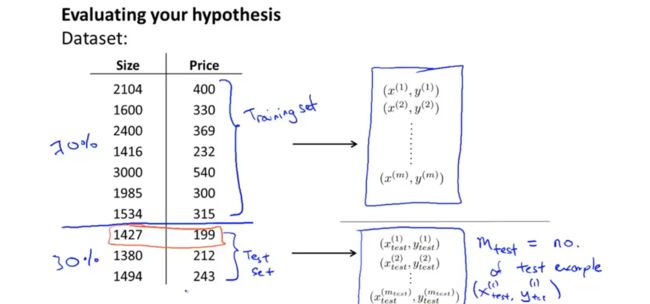
将数据随机分为两部分,通常划分为7:3,70%的数据作为训练集,30%的数据作为测试集。

通过计算测试集中的误差,即预测值与真实值之间的误差平方和来评估假说的优劣。

在logistic回归中,同样可以使用损失函数来评估假说的好坏。也可以利用错误分类误差来判断,error=1时,表示,标签为在很大概率上为0但却被错误的判断为1,或者,标签在很大概率上为1但却错判为0。当error等于0使表示分类正确。通过对测试错误的数量进行加权求和,可以得到testerror值,据此对假说进行评估。
模型选择与训练、验证、测试集

在模型选择时,我们并不能事先知道哪种多项式更适合,因此需要进行评估和选择,我们用d表示多项式的次数,不同多项式的效果不同,我们可以通过在不同多项式模型上进行训练,求出参数,然后在测试机上进行计算,求出测试误差,最后通过测试误差判断模型的好坏,选择模型。对于模型的泛化能力如何,我们仍然是在测试机上进行验证。 这种模型选择方法可能会存在问题,因为我们通过训练集得到参数以后,模型的选择是在测试集上进行的,选择的是testerror最小的模型,然后再进行泛化的时候仍然是在测试集上进行的,这样求出的泛化误差肯定是最小的,很可能与之前的测试误差相同或相近。因此,在进行模型验证和选择的时候通常采用下面的方法:
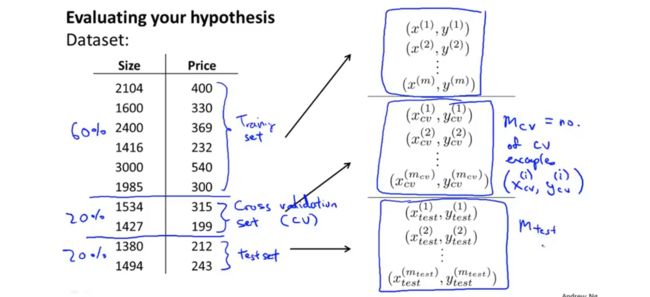
在对数据集进行分类的时候,将数据分为三类,训练集,交叉验证集和测试集。通常的比例为60%,20%,20%。在进行模型评估时,首先通过训练集得到参数值,然后通过验证集验证模型的好坏,找到误差最小的模型,最后通过测试集检测模型的泛化能力。下图表示不同数据集下的误差表示:


因此,在进行模型选择时,首先求得不同模型下的损失函数,根据损失函数最小化求得参数向量,训练街求得不同模型下的参数,然后通过交叉验证集来测试,通过计算,来验证模型在交叉验证集上的效果如何,然后选择交叉验证误差最小的模型作为我们的模型,假设这里的d=4时(参数d表示多项式的次数)的交叉验证误差最小,那我们就选择4次多项式为我们的模型。最后,留下的测试集可以用来测量模型的泛化误差。
诊断偏误与误差
模型是欠拟合还是过拟合?是偏差问题还是方差问题?
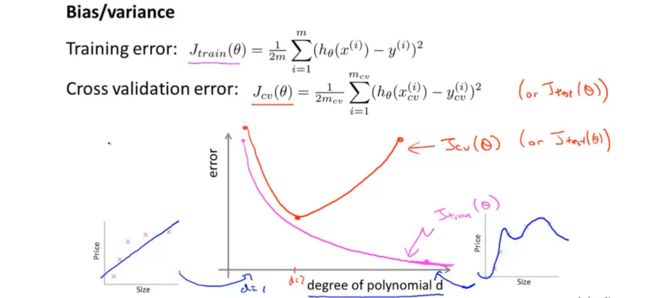

当模型多项式次数较低的时候,会产生欠拟合的情况,此时,训练误差和验证误差都会比较大,这种情况成为偏差;当模型多项式次数过高,会出现过拟合的情况,此时训练误差较小而验证误差较大且远远大于训练误差,这种情况成为高方差。通过分析训练误差和测试误差的相对大小,我们可以判断模型到底是出现高偏差还是高方差,即是欠拟合还是过拟合。
正则化与偏差、方差
之前我们讲到,正则化可以防止模型出现过拟合的情况,即降低偏差,那么正则化与方差又有什么关系呢?
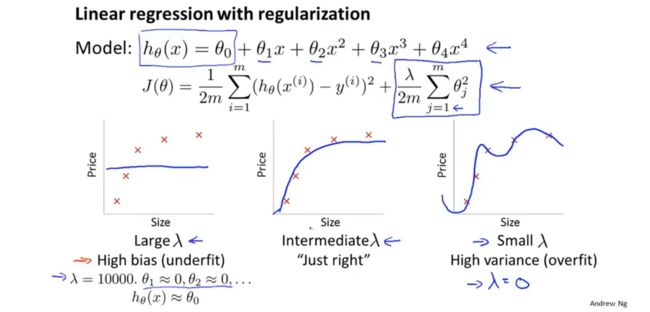
当正则参数较大的时候,对所有参数的惩罚都比较大,此时假设模型约等于常数项,结果如上图最左边的图所示,此时会出现欠拟合。当正则参数选择的合适时,模型表现最好,如上中间图所示,当正则参数较小,对欠拟合起不到惩罚作用,则模型依旧会出现欠拟合问题,如上面右图所示。 那么,如何自动选择一个合适的正则参数呢?
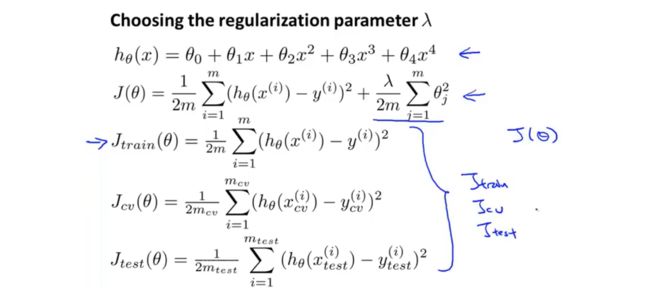
首先将训练集,验证集,测试集中的损失函数设为不加正则项的形式。

在建立模型之后,尝试不同的正则参数,在不同正则参数下计算训练集数据最小化损失函数之后得到的参数,并根据参数在验证集中求验证误差,选择验证误差最小的正则参数。
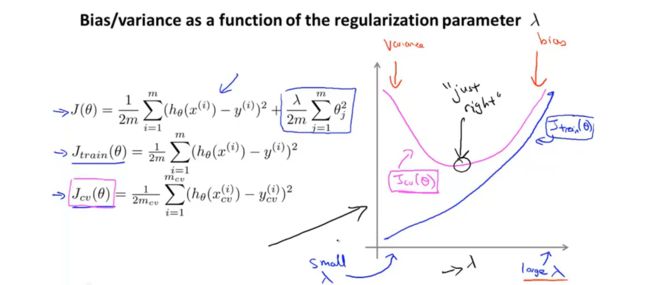
当正则参数较小的时候,对于训练误差来说,会存在过拟合现象,此时模型对训练数据拟合效果较好训练误差较小,但是泛化能力差,所以在测试数据上的误差较大。当正则参数较大的时候,对模型中所有的参数惩罚较大,模型趋向于一条直线,存在欠拟合现象,此时训练误差和测试误差都会比较大。
在进行正则参数选择的时候,画出上图这样的曲线能更好的的帮助我们分析在正则参数不同的情况下的偏差与方差的情况,帮助我们更好的做出选择。
学习曲线
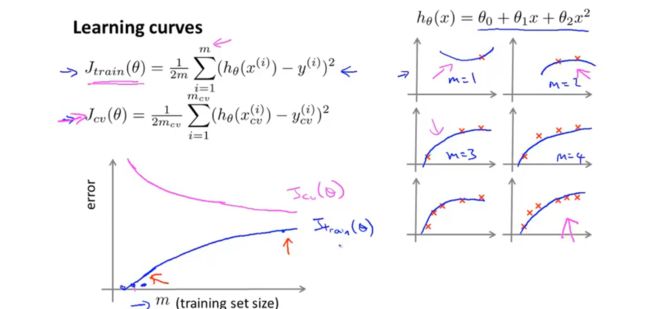
当样本量较少的时候,二次曲线就能较好的拟合数据,因此训练误差很小,随着数据量的增加,二次曲线不足以拟合数据,训练误差就会增大。对于交叉验证机来说,当数据较少时,拟合出的模型泛化能力差,不能适合新的样本,因此验证误差较大,当数据量较多的时候拟合效果较好,泛化能力好。因此,验证模型曲线如图所示。

当出现高偏差,即欠拟合的情况时,数据量较少的条件下测试误差较大,但随着样本样的增加,模型几乎没有发生改变,因此测试误差在超过某个数据量以后保持不变。对于训练集来说,数据量较少的时候拟合效果较好,随着样本量的增加,模型没有改变,因此误差增加,最后趋于常数。在欠拟合的条件下,增加数据量对与提高模型没有太大影响。因此,知道模型是否处于欠拟合状态是非常有用的,他可以避免让你话太多的时间在增加样本数量上。因为再多的数据量也是没有用的。
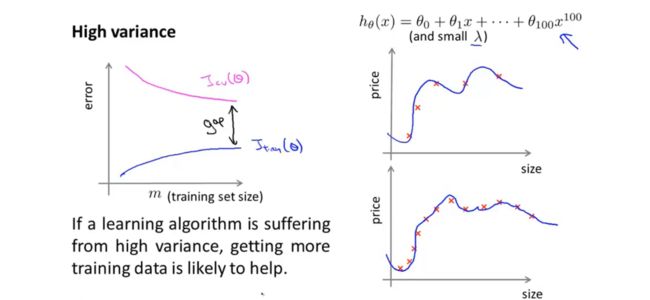
当存在高方差的时候,对于训练集来说,模型在数据较少的时候拟合效果较好,随着数据量的增多,模型较难拟合所有的数据,因此误差增大,但是总体来说误差较小;对于测试误差来说,由于过拟合,数据泛化能力差,验证误差较大,但随着样本量的增加,误差会下降。验证误差和训练误差存在较大的差距。随着样本量的增加,这种差距可能会减少,因此增加样本量对解决高方差问题来说可能会有效。 我们可以通过学习曲线来分析模型到底是存在偏差还是误差,据此寻找更好的提高模型表现的方法,在实际中,可能会存在很多噪音,形成的学习曲线不会是这样平滑的,但是对于判断模型问题来说,这还是比较有效的方法。
如何选择提高模型表现的方法

通过之前学习的判断模型好坏的一些方法,如学习曲线等,我们现在已经能够合理的选择改善模型的方法。如上图所示。
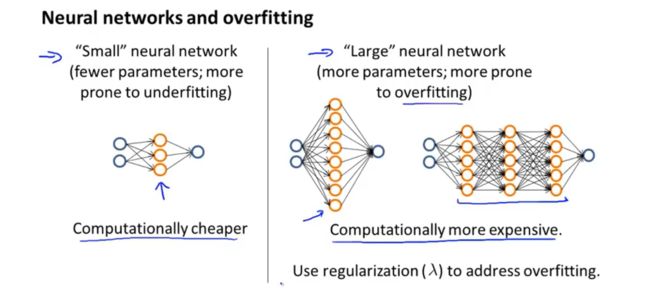
小的神经网络通常具有较少的参数,更容易欠拟合,但是计算相对简单;大规模的神经网络具有较多的参数,更容易陷入过拟合,较好的模式是选择一层隐含层,如果要多层隐含层的话,可以通过训练集,验证集,测试集来选择需要几层隐含层。