Python程序员说,人生苦短,我用Python;Ruby程序员不说话,向你扔过来世界上最好的语言;PHP程序员大喊,PHP才是最好的语言。
当然,对于我来说,Ruby最大的特点,就是优雅。顺便八卦一句,的代码就是Ruby写的。
最近学习Ruby的时候,有倾向性的向两个方面努力,一个是自动化测试,一个是金融数据分析。这两个课题都比较大,但只要脚踏实地的开始去做,就没有到达不了的目的地。Ruby虽然很优雅很酷,可是在中国起步相对较晚,而且更多的是大牛们在掌握,在Ruby中国能找到入门的资料很少,找个示例代码都很困难,只能一遍遍的自己去尝试去调试。这样的缺点是非常累,逼着自己去查阅英文社区的资料,好处是自己进步比较快,理解的比较深刻。等有了一定的Ruby基础,再去看那些琳琅满目的Python代码,反而觉得不用急躁,终有一天都会掌握。
经过近一个月的自学,我完成了《笨办法学Ruby》课本上的期中测验,自我感觉良好的我决定写一段更复杂的代码。我在Ruby中国找到了一套面向新手的测试题,其中一项让我感兴趣:做一个实时股票查询程序。于是,就下手了。
先上代码:
# -*- coding: UTF-8 -*-
require 'rubygems'
require 'hpricot'
require 'open-uri'
x = 1
while x <= 2906
puts "轮询中:"
stock_lines = IO.readlines("d:/rb/stock/stock.txt");
s_code = stock_lines[x]
scode = s_code.chomp # chomp用来删除文本里带过来的换行符
puts "-----------------------"
doc = Hpricot(open('http://hq.sinajs.cn/list=' + "#{scode}"))
#puts doc
out_file = open('d:/rb/stock/temp.txt', 'w')
out_file.write(doc)
out_file.close
str = IO.read("d:/rb/stock/temp.txt");
#puts str.length;
#puts str[0,30]
str.split(/,/)
arr = str.split(/,/)
s_name = arr[0]
s_open_today = arr[1]
s_prev_close = arr[2]
s_latest_price = arr[3]
s_high_price = arr[4]
s_low_price = arr[5]
s_sum = arr[9]
s_buy_1 = arr[10]
s_buy_1_price = arr[11]
s_buy_2 = arr[12]
s_buy_2_price = arr[13]
s_buy_3 = arr[14]
s_buy_3_price = arr[15]
s_buy_4 = arr[16]
s_buy_4_price = arr[17]
s_buy_5 = arr[18]
s_buy_5_price = arr[19]
s_sale_1 = arr[20]
s_sale_1_price = arr[21]
s_sale_2 = arr[22]
s_sale_2_price = arr[23]
s_sale_3 = arr[24]
s_sale_3_price = arr[25]
s_sale_4 = arr[26]
s_sale_4_price = arr[27]
s_sale_5 = arr[28]
s_sale_5_price = arr[29]
s_date = arr[30]
s_time = arr[31]
puts "当前时间: " + s_date + " " + s_time
puts "Name: " + s_name[-14,8] + s_name[-4,10]
puts "今日开盘: " + s_open_today
puts "成交金额: " + s_sum
puts "昨日收盘: " + s_prev_close
puts "当前价格: " + s_latest_price
puts "今日最高: " + s_high_price
puts "今日最低: " + s_low_price
puts "------------------------"
puts "买一股数/报价:" + s_buy_1 + "/" +s_buy_1_price
puts "买二股数/报价:" + s_buy_2 + "/" +s_buy_2_price
puts "买三股数/报价:" + s_buy_3 + "/" +s_buy_3_price
puts "买四股数/报价:" + s_buy_4 + "/" +s_buy_4_price
puts "买五股数/报价:" + s_buy_5 + "/" +s_buy_5_price
puts "------------------------"
puts "卖一股数/报价:" + s_sale_1 + "/" +s_sale_1_price
puts "卖二股数/报价:" + s_sale_2 + "/" +s_sale_2_price
puts "卖三股数/报价:" + s_sale_3 + "/" +s_sale_3_price
puts "卖四股数/报价:" + s_sale_4 + "/" +s_sale_4_price
puts "卖五股数/报价:" + s_sale_5 + "/" +s_sale_5_price
x = x + 1
end
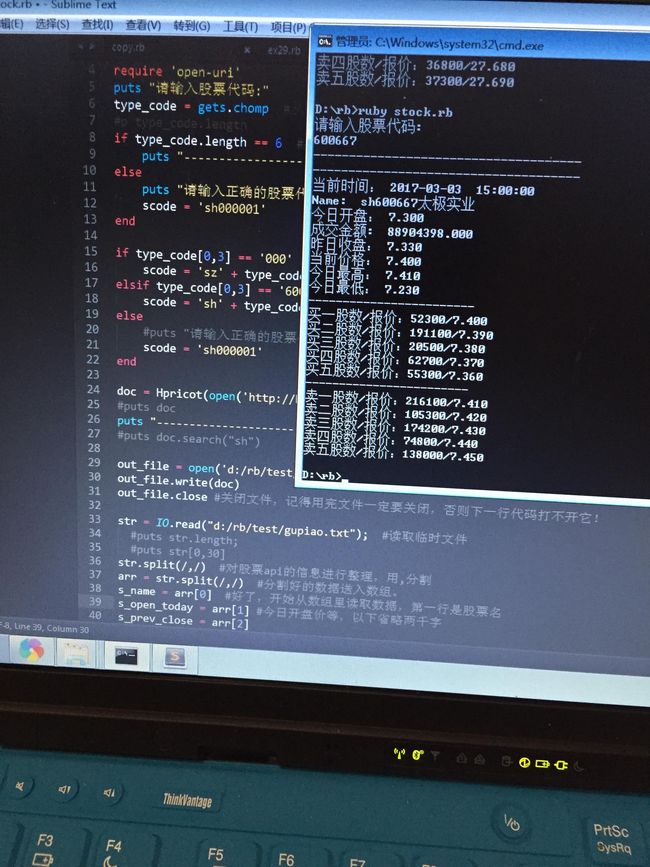
其实这段代码实现起来比我最初预想的简单得多,我做了两个版本,一个是单支股票查询,一个是全部股票轮询。第一版很快就跑通了,但是第二版跑通却用了差不多三天的时间,主要是处理一些意想不到的细节。
1、股市接口。
我使用了新浪股票接口,实测基本是实时数据,可能会有几十秒的缓存时间。这个接口简单又强大,提供了30个字段,我不炒股,不知道这些数据够不够用(接口还提供了各种分时图,因为获取比较简单,暂时没有写到代码里)。
2、字符集。
因为调试代码过程中被中文字符折腾的头大,所以强制使用UTF-8字符集。然并卵... ...
3、接收接口数据。
我使用了require 'hpricot' 来打开并接收URL的数据,这个库可以将网页里的数据传递给程序。因为不断报错,在这里我学会了如何安装gem,顺便学会了升级Ruby的gem版本。
我本来放进了数组,但是在数组里重新处理的时候,我自觉能力有限,只好临时存到temp.txt里。强化了对文件进行处理的能力。
4、获取股票代码。
这是我耗时最多的地方。为了偷懒,我从网上下载了最新的股票代码Excel,转存成stock.txt进行读取。没想到的是,我弄了三天才能让程序顺畅的读取。因为txt文件里有看不到的换行符,程序把换行符读到了URL里,导致报错,但报错的时候也不显示换行符,我手工敲入一模一样的代码就可以跑通,但程序从txt里读取就跑不通,让我一脸懵逼。最后才恍然大悟,用s_code.chomp删掉换行符。
为了保证股票代码自动更新,下个版本准备采用遍历的方式,自动从新浪接口读取股票代码再保存。这需要对沪市深市的编码规则有一些了解。还要掌握文本类型的数字加法问题,目前还没想清楚用Ruby对“000001+1”怎么处理,视同数字会处理成2,没有一串0,视同文本会处理成0000011----嗯,刚才看到了一段php的遍历股票代码,大致明白怎么处理了,可以先把0去掉处理数字,处理完了转成文本,再根据数字长度补0,程序员们的脑洞就是大啊。
5、获取新浪股票接口数据。
doc = Hpricot(open('http://hq.sinajs.cn/list=' + "#{scode}"))
这行代码可以按照股票编码传递新浪股票接口数据,并把数据存储到doc里,然后我把doc存到临时文件里,再分割后传递到数组里。
out_file = open('d:/rb/stock/temp.txt', 'w')
out_file.write(doc)
out_file.close
写文件要使用'w'标记,否则默认是只读。
打开文件用完了一定要记得关闭,这是一种最基本的礼貌... ...否则下次打开会报错。
str = IO.read("d:/rb/stock/temp.txt");
str.split(/,/)
arr = str.split(/,/)
split的作用是根据分隔符分隔文本,新浪股票接口用英文“,”隔开数据,然后传送到数组里。
6、剩下的就简单了,把股票接口里的数据分别读出来并puts一下。
7、循环。
在Ruby里,while表示循环,我定义x为股票代码文件的行数,一直到2906行(我下载的股票代码数)为止,这样这段程序可以对这些股票的全部信息进行查询。
8、这段代码的意义?
我不炒股,目前看这段代码没什么意义,你可以在任何一个股票软件里查到这些数据。不过,我可以把从接口拿到的所有数据使用任意的运算规则进行运算,再进行预警。毕竟这些数据是基本实时的,但也没有太大意义,很多商业版炒股软件也都有预警功能。看起来很low是吧?嗯,等我想起来还能做什么的时候,我再改一下这段代码。毕竟火车刚发明的时候,也是跑不过马车的。
9、后记。
上文完成后,我又用了两个小时的时间,研究了中国的股票编码规则,然后写了个遍历的小程序,可以在两分钟左右的时间获取全部股票代码----由于不是每天都会有新股,所以这个效率也可以接受。据我观察,中国股市逻辑如下:
1、沪市,600开头,601开头,603开头。遍历规则可以试试 600001-601999,603001-603999
2、深市,000开头,其中002是中小板,遍历规则试试 000001-002999
3、创业板,深市,300开头,目前到 300628,遍历规则可以试试 300001-300999
#生成最新股票代码清单
# -*- coding: UTF-8 -*-
require 'rubygems'
require 'hpricot'
require 'open-uri'
#判断股票清单是否存在,存在的话删除重新生成
if File::exists?( "d:/rb/stock/stock.txt" )
puts "股票清单已经存在,如无新股发行,本清单无需更新。3秒后更新清单。"
sleep 3
File.delete( "d:/rb/stock/stock.txt" )
end
#生成股票代码清单----沪市
puts "-------------沪市遍历中--------------"
s_temp_code = 600001
while s_temp_code <= 603999
s_doc = Hpricot(open('http://hq.sinajs.cn/list=' + 'sh' + "#{s_temp_code}"))
#puts doc
s_out_file = open('d:/rb/stock/s_temp.txt', 'w')
s_out_file.write(s_doc)
s_out_file.close
s_str = IO.read("d:/rb/stock/s_temp.txt");
s_temp_name = s_str[11,8]
puts "获取沪市股票数据:" + s_temp_name
if s_str.length > 30
s_file = open('d:/rb/stock/stock.txt', 'a')
s_file.write("#{s_temp_name}" + "\n") #追加换行符
s_file.close
end
s_temp_code = s_temp_code + 1
end
#生成股票代码清单----深市
puts "-------------深市遍历中--------------"
s_sz_code = 1
#p "#{s_sz_code}".length
while s_sz_code <= 2999
if "#{s_sz_code}".length == 1
s_sz_temp_code = '00000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 2
s_sz_temp_code = '0000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 3
s_sz_temp_code = '000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 4
s_sz_temp_code = '00' + "#{s_sz_code}"
end
s_sz_doc = Hpricot(open('http://hq.sinajs.cn/list=' + 'sz' + "#{s_sz_temp_code}"))
#puts doc
s_sz_out_file = open('d:/rb/stock/s_temp.txt', 'w')
s_sz_out_file.write(s_sz_doc)
s_sz_out_file.close
s_sz_str = IO.read("d:/rb/stock/s_temp.txt");
s_sz_temp_name = s_sz_str[11,8]
puts "获取深市股票数据:" + s_sz_temp_name
if s_sz_str.length > 30
s_sz_file = open('d:/rb/stock/stock.txt', 'a')
s_sz_file.write("#{s_sz_temp_name}" + "\n")
s_sz_file.close
end
s_sz_code = s_sz_code + 1
end
#生成深市创业板数据
puts "-------------深市创业板遍历中--------------"
s_cy_code = 300001
while s_cy_code <= 300999
s_cy_doc = Hpricot(open('http://hq.sinajs.cn/list=' + 'sz' + "#{s_cy_code}"))
#puts doc
s_cy_out_file = open('d:/rb/stock/s_temp.txt', 'w')
s_cy_out_file.write(s_cy_doc)
s_cy_out_file.close
s_cy_str = IO.read("d:/rb/stock/s_temp.txt");
s_cy_temp_name = s_str[11,8]
puts "获取创业板股票数据:" + s_cy_temp_name
if s_cy_str.length > 30
s_cy_file = open('d:/rb/stock/stock.txt', 'a')
s_cy_file.write("#{s_cy_temp_name}" + "\n") #追加换行符
s_cy_file.close
end
s_cy_code = s_cy_code + 1
end
1和3的逻辑基本相同,Ruby对数字和字符的加减乘除比较简单,甚至不需要转换就可以四则运算----真是良心啊~~
但是2的逻辑就稍微复杂,于是参照看到的一段php代码的逻辑,写了Ruby的一段代码。
s_sz_code = 1
#p "#{s_sz_code}".length
while s_sz_code <= 2999
if "#{s_sz_code}".length == 1
s_sz_temp_code = '00000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 2
s_sz_temp_code = '0000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 3
s_sz_temp_code = '000' + "#{s_sz_code}"
elsif "#{s_sz_code}".length == 4
s_sz_temp_code = '00' + "#{s_sz_code}"
end
这段代码的思路就是不足六位的在前面补零,变量进行字符串处理的时候需要通过#{}来操作。
需要注意的是,在处理stock.txt文件的时候,我才用的是“a”参数,这是追加模式。每次循环读出的股票代码,追加到文件中。同时使用“\n”增加换行符:
s_cy_file = open('d:/rb/stock/stock.txt', 'a')
s_cy_file.write("#{s_cy_temp_name}" + "\n") #追加换行符
s_cy_file.close