原文| http://t.cn/RQXs2wL
作者| Alex Rogozhnikov
机器之心翻译出品(http://t.cn/R8yJqkB)
对于数据科学开发者而言,如何将已有项目从 Python 2 转向 Python 3 成为了正在面临的重大问题。来自莫斯科大学的 Alex Rogozhnikov 博士为我们整理了一份代码迁移指南。
目前,Python 科学栈中的所有主要项目都同时支持 Python 3.x 和 Python 2.7,不过,这种情况很快即将结束。去年 11 月,Numpy 团队的一份声明引发了数据科学社区的关注:这一科学计算库即将放弃对于 Python 2.7 的支持,全面转向 Python 3。Numpy 并不是唯一宣称即将放弃 Python 旧版本支持的工具,pandas 与 Jupyter notebook 等很多产品也在即将放弃支持的名单之中。对于数据科学开发者而言,如何将已有项目从 Python 2 转向 Python 3 成为了正在面临的重大问题。来自莫斯科大学的 Alex Rogozhnikov 博士为我们整理了一份代码迁移指南。
Python 3 功能简介
Python 是机器学习和其他科学领域中的主流语言,我们通常需要使用它处理大量的数据。Python 兼容多种深度学习框架,且具备很多优秀的工具来执行数据预处理和可视化。
但是,Python 2 和 Python 3 长期共存于 Python 生态系统中,很多数据科学家仍然使用 Python 2。2019 年底,Numpy 等很多科学计算工具都将停止支持 Python 2,而 2018 年后 Numpy 的所有新功能版本将只支持 Python 3。
为了使 Python 2 向 Python 3 的转换更加轻松,我收集了一些 Python 3 的功能,希望对大家有用。

使用 pathlib 更好地处理路径
pathlib 是 Python 3 的默认模块,帮助避免使用大量的 os.path.joins:

Python 2 总是试图使用字符串级联(准确,但不好),现在有了 pathlib,代码安全、准确、可读性强。
此外,pathlib.Path 具备大量方法,这样 Python 新用户就不用每个方法都去搜索了:

pathlib 会节约大量时间,详见:
文档:https://docs.python.org/3/library/pathlib.html;
参考信息:https://pymotw.com/3/pathlib/。
类型提示(Type hinting)成为语言的一部分
PyCharm 中的类型提示示例:
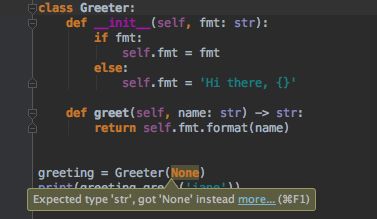
Python 不只是适合脚本的语言,现在的数据流程还包括大量步骤,每一步都包括不同的框架(有时也包括不同的逻辑)。
类型提示被引入 Python,以帮助处理越来越复杂的项目,使机器可以更好地进行代码验证。而之前需要不同的模块使用自定义方式在文档字符串中指定类型(注意:PyCharm 可以将旧的文档字符串转换成新的类型提示)。
下列代码是一个简单示例,可以处理不同类型的数据(这就是我们喜欢 Python 数据栈之处)。

上述代码适用于 numpy.array(包括多维)、astropy.Table 和 astropy.Column、bcolz、cupy、mxnet.ndarray 等。
该代码同样可用于 pandas.Series,但是方式是错误的:
这是一个两行代码。想象一下复杂系统的行为多么难预测,有时一个函数就可能导致错误的行为。明确了解哪些类型方法适合大型系统很有帮助,它会在函数未得到此类参数时给出提醒。
如果你有一个很棒的代码库,类型提示工具如 MyPy 可能成为集成流程中的一部分。不幸的是,提示没有强大到足以为 ndarrays/tensors 提供细粒度类型,但是或许我们很快就可以拥有这样的提示工具了,这将是 DS 的伟大功能。
类型提示 → 运行时的类型检查
默认情况下,函数注释不会影响代码的运行,不过它也只能帮你指出代码的意图。
但是,你可以在运行时中使用 enforce 等工具强制进行类型检查,这可以帮助你调试代码(很多情况下类型提示不起作用)。
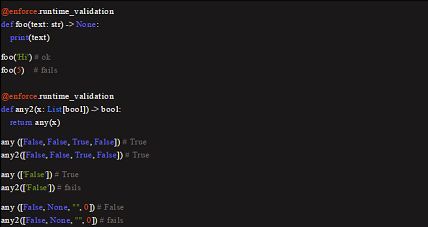
函数注释的其他用处
如前所述,注释不会影响代码执行,而且会提供一些元信息,你可以随意使用。
例如,计量单位是科学界的一个普遍难题,astropy 包提供一个简单的装饰器(Decorator)来控制输入量的计量单位,并将输出转换成所需单位。

如果你拥有 Python 表格式科学数据(不必要太多),你应该尝试一下 astropy。你还可以定义针对某个应用的装饰器,用同样的方式来控制/转换输入和输出。
通过 @ 实现矩阵乘法
下面,我们实现一个最简单的机器学习模型,即带 L2 正则化的线性回归:

下面 Python 3 带有 @ 作为矩阵乘法的符号更具有可读性,且更容易在深度学习框架中转译:因为一些如 X @ W + b[None, :] 的代码在 numpy、cupy、pytorch 和 tensorflow 等不同库下都表示单层感知机。
使用 ** 作为通配符
递归文件夹的通配符在 Python2 中并不是很方便,因此才存在定制的 glob2 模块来克服这个问题。递归 flag 在 Python 3.6 中得到了支持。

python3 中更好的选择是使用 pathlib:
Print 在 Python3 中是函数
Python 3 中使用 Print 需要加上麻烦的圆括弧,但它还是有一些优点。
使用文件描述符的简单句法:
在不使用 str.join 下输出 tab-aligned 表格:
修改与重新定义 print 函数的输出:

在 Jupyter 中,非常好的一点是记录每一个输出到独立的文档,并在出现错误的时候追踪出现问题的文档,所以我们现在可以重写 print 函数了。
在下面的代码中,我们可以使用上下文管理器暂时重写 print 函数的行为:

上面并不是一个推荐的方法,因为它会引起系统的不稳定。
print 函数可以加入列表解析和其它语言构建结构。
f-strings 可作为简单和可靠的格式化
默认的格式化系统提供了一些灵活性,且在数据实验中不是必须的。但这样的代码对于任何修改要么太冗长,要么就会变得很零碎。而代表性的数据科学需要以固定的格式迭代地输出一些日志信息,通常需要使用的代码如下:
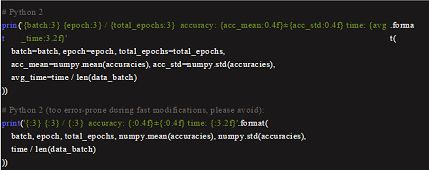
样本输出:
f-strings 即格式化字符串在 Python 3.6 中被引入:
另外,写查询语句时非常方便:
「true division」和「integer division」之间的明显区别
对于数据科学来说这种改变带来了便利(但我相信对于系统编程来说不是)。
Python 2 中的结果依赖于『时间』和『距离』(例如,以米和秒为单位)是否被保存为整数。
在 Python 3 中,结果的表示都是精确的,因为除法的结果是浮点数。
另一个案例是整数除法,现在已经作为明确的运算:
注意:该运算可以应用到内建类型和由数据包(例如,numpy 或 pandas)提供的自定义类型。
严格排序
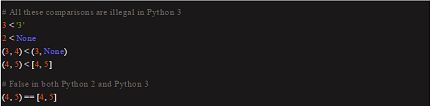
防止不同类型实例的偶然性的排序。
在处理原始数据时帮助发现存在的问题。
旁注:对 None 的合适检查是(两个版本的 Python 都适用):

自然语言处理的 Unicode
输出:
Python 2: 6\n��
Python 3: 2\n 您好.
Python 2 在此失败了,而 Python 3 可以如期工作(因为我在字符串中使用了俄文字母)。
在 Python 3 中 strs 是 Unicode 字符串,对非英语文本的 NLP 处理更加方便。
还有其它有趣的方面,例如:
Python 2:
Counter({'\xc3': 2, 'b': 1, 'e': 1, 'c': 1, 'k': 1, 'M': 1, 'l': 1, 's': 1, 't': 1, '\xb6': 1, '\xbc': 1})Python 3:
Counter({'M': 1, 'ö': 1, 'b': 1, 'e': 1, 'l': 1, 's': 1, 't': 1, 'ü': 1, 'c': 1, 'k': 1})
这些在 Python 2 里也能正确地工作,但 Python 3 更为友好。
保留词典和**kwargs 的顺序
在 CPython 3.6+ 版本中,字典的默认行为类似于 OrderedDict(在 3.7+版本中已得到保证)。这在字典理解(和其他操作如 json 序列化/反序列化期间)保持顺序。

它同样适用于**kwargs(在 Python 3.6+版本中):它们的顺序就像参数中显示的那样。当设计数据流程时,顺序至关重要,以前,我们必须以这样繁琐的方式来编写:
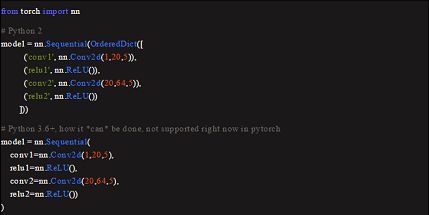
注意到了吗?名称的唯一性也会被自动检查。
迭代地拆封

默认的 pickle 引擎为数组提供更好的压缩
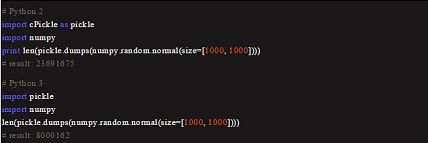
节省 3 倍空间,而且速度更快。实际上,类似的压缩(不过与速度无关)可以通过 protocol=2 参数来实现,但是用户通常会忽略这个选项(或者根本不知道)。
更安全的解析

关于 super()
Python 2 的 super(...)是代码错误中的常见原因。
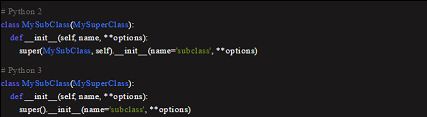
关于 super 和方法解析顺序的更多内容,参见 stackoverflow:https://stackoverflow.com/questions/576169/understanding-python-super-with-init-methods
更好的 IDE 会给出变量注释
在使用 Java、C# 等语言编程的过程中最令人享受的事情是 IDE 可以提供非常好的建议,因为在执行代码之前,所有标识符的类型都是已知的。
而在 Python 中这很难实现,但是注释可以帮助你:
以清晰的形式写下你的期望
从 IDE 获取良好的建议
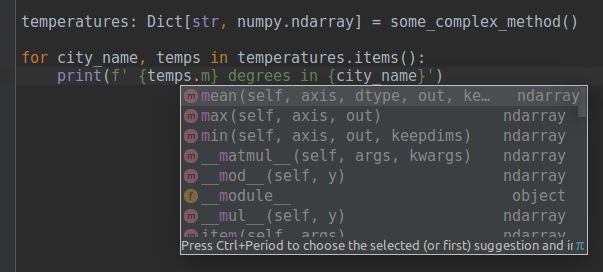
这是一个带变量注释的 PyCharm 示例。即使你使用的函数不带注释(例如,由于向后兼容性),它也能工作。
多种拆封(unpacking)
在 Python3 中融合两个字典的代码示例:

可以在这个链接中查看 Python2 中的代码对比:https://stackoverflow.com/questions/38987/how-to-merge-two-dictionaries-in-a-single-expression
aame 方法对于列表(list)、元组(tuple)和集合(set)都是有效的(a、b、c 是任意的可迭代对象):

对于*args 和 **kwargs,函数也支持额外的 unpacking:

只带关键字参数的 API
我们考虑这个代码片段:
很明显,代码的作者还没熟悉 Python 的代码风格(很可能刚从 cpp 和 rust 跳到 Python)。不幸的是,这不仅仅是个人偏好的问题,因为在 SVC 中改变参数的顺序(adding/deleting)会使得代码无效。特别是,sklearn 经常会重排序或重命名大量的算法参数以提供一致的 API。每次重构都可能使代码失效。
在 Python3,库的编写者可能需要使用*以明确地命名参数:
现在,用户需要明确规定参数 sklearn.svm.SVC(C=2, kernel='poly', degree=2, gamma=4, coef0=0.5) 的命名。
这种机制使得 API 同时具备了可靠性和灵活性。
小调:math 模块中的常量
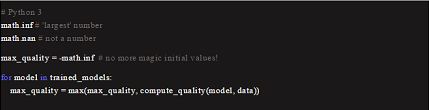
小调:单精度整数类型
Python 2 提供了两个基本的整数类型,即 int(64 位符号整数)和用于长时间计算的 long(在 C++变的相当莫名其妙)。
Python 3 有一个单精度类型的 int,它包含了长时间的运算。
下面是查看值是否是整数的方法:

其他
Enums 有理论价值,但是字符串输入已广泛应用在 python 数据栈中。Enums 似乎不与 numpy 交互,并且不一定来自 pandas。
协同程序也非常有希望用于数据流程,但还没有出现大规模应用。
Python 3 有稳定的 ABI
Python 3 支持 unicode(因此ω = Δφ / Δt 也 okay),但你最好使用好的旧的 ASCII 名称
一些库比如 jupyterhub(jupyter in cloud)、django 和新版 ipython 只支持 Python 3,因此对你来讲没用的功能对于你可能只想使用一次的库很有用。
数据科学特有的代码迁移问题(以及如何解决它们)
停止对嵌套参数的支持:
然而,它依然完美适用于不同的理解:
通常,理解在 Python 2 和 3 之间可以更好地「翻译」。
map(), .keys(), .values(), .items(), 等等返回迭代器,而不是列表。迭代器的主要问题有:没有琐碎的分割和无法迭代两次。将结果转化为列表几乎可以解决所有问题。
遇到问题请参见 Python 问答:我如何移植到 Python 3?(https://eev.ee/blog/2016/07/31/python-faq-how-do-i-port-to-python-3/)
用 python 教机器学习和数据科学的主要问题
课程作者应该首先花时间解释什么是迭代器,为什么它不能像字符串那样被分片/级联/相乘/迭代两次(以及如何处理它)。
我相信大多数课程作者很高兴避开这些细节,但是现在几乎不可能。
结论
Python 2 与 Python 3 共存了近 10 年,时至今日,我们必须要说:是时候转向 Python 3 了。
研究和生产代码应该更短,更易读取,并且在迁移到 Python 3 代码库之后明显更加的安全。
现在大多数库同时支持 2.x 和 3.x 两个版本。但我们不应等到流行工具包开始停止支持 Python 2 才开始行动,提前享受新语言的功能吧。
迁移过后,我敢保证程序会更加顺畅:「我们不会再做向后不兼容的事情了(https://snarky.ca/why-python-3-exists/)」。