声明:以下是学习《集体编程智慧》的笔记,代码使用python编写。
需要有python自定义函数的知识,以及事先了解皮尔森相关系数的公式
网上总是有人吐槽:“XX的算法很可笑,老是给我推荐我不想要的东西”。作为非计算机专业的普通人,一直不太明白何谓“算法”。比如豆瓣是怎么给我推荐我喜欢的电影的。就目前我的理解,就是通过某些数学公式,把我的兴趣跟别人的兴趣作比较,得出一个关联度。而书中讲述了如何用代码实现。
一个例子
书中给到一个很简单的例子,大概是说每个用户,对每部电影的评分,构成一个字典,即由“用户——电影名——评分”构成的字典。
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
所以我们对其建立一个名为recommendations.py的文件,执行:
from recommendations import critics
critics['Lisa Rose']['Lady in the Water']
就会得到2.5的结果。(跟翻字典一样,找到声母、韵母就会得出对应的字)
如何考察两个人的口味?这里就要把文字描述落地到图表了:
寻找相近的用户1——欧几里得距离评价
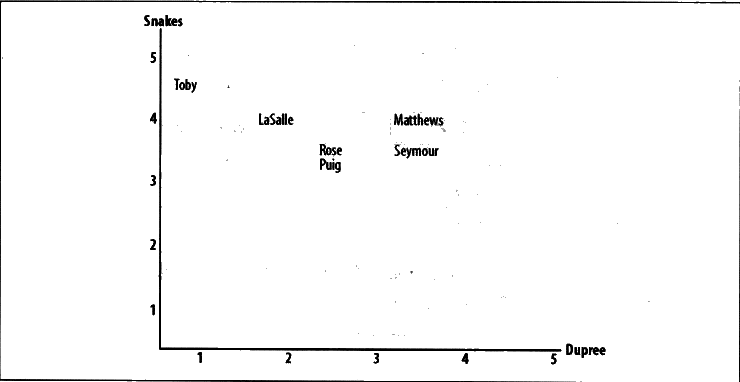
上图简单展示了如何判断两个人的相似度——Toby和LaSalle的相似度就比和Seymour的相似度更大(坐标距离可见),计算距离我们用各自横竖坐标差值平方和的开方(好拗口)表示:
from math import sqrt
sqrt(pow(4.5-4,2)+pow(1-2,2))
结果为1.118033988749895
当然,数字越小,距离越近,相关度越大。
但为了好记忆,我们希望数字越大,相关度越大,就这么处理:
1/(1+sqrt(pow(4.5-4,2)+pow(1-2,2)))
分母加1是为了避免距离为零的时候出现错误。
寻找相近的用户2——皮尔森相关度评价
(此段需要皮尔森相关函数的知识)
原因:皮尔森相关度评价的出现是源于对数据不规范时的考虑——如果影评者对影片的评论总是相对于平均水平偏离很大时(比如苛刻的影评者普遍给低分)——依然能给出合理的相关度评论。
方法:判断两组数据与某一直线的拟合程度
注意:皮尔森相关度是基于对物品距离的计算
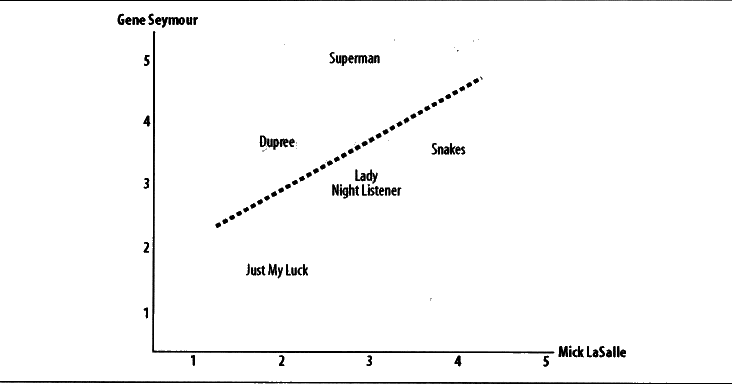
上图是相关度不尽相同的情况,而下图是相关度趋于一致的情况
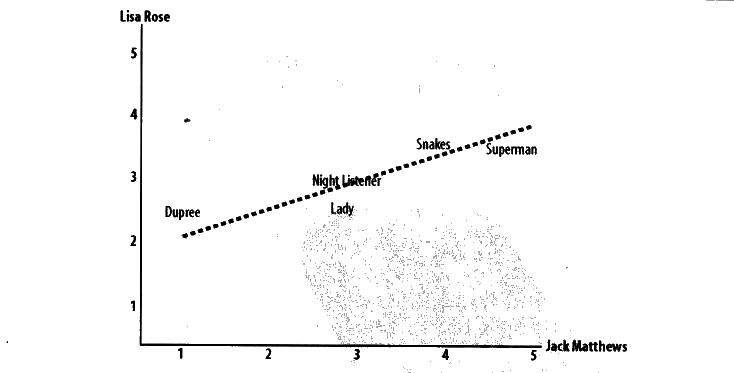
这里Jack总是倾向比Lisa给出更高分值,但不影响我们判断他俩有相似偏好(因为他们有趋同性)
在recommendations.py文件下def sim_pearson,用于 判断俩人的相似度
def sim_distance(prefs,person1,person2):
# 得到shared_items的列表
si={}
for item in prefs[person1]:
if item in prefs[person2]: si[item]=1
# 如果两者没有共同之处,则返回0
if len(si)==0: return 0
# 计算所有差值的平方和
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2)
for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sum_of_squares)
执行
print recommendations.sim_pearson(recommendations.critics,'Lisa Rose','Gene Seymour')
得到0.396059017191
推荐相似的人
而我们日常更常出现的需求是:知道一个人的爱好,向其推荐有共同喜好的人或可能会喜好的物。
在recommendations.py文件下def topMatches,用于给待推荐的人打分
# 从反映偏好的字典中返回最为匹配者
# 返回结果的个数和相似度函数均为可选参数
def topMatches(prefs,person,n=5,similarity=sim_pearson):
scores=[(similarity(prefs,person,other),other)
for other in prefs if other!=person]
scores.sort()
scores.reverse()
return scores[0:n]
# 利用所有他人评价值的加权平均,为某人提供建议
# of every other user's rankings
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
# 不和自己做比较
if other==person: continue
sim=similarity(prefs,person,other)
# 忽略评价值为零或小于零的情况
if sim<=0: continue
for item in prefs[other]:
#只对自己还未曾看过的影片进行评价
if item not in prefs[person] or prefs[person][item]==0:
# 相似度*评价值
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
# 建立规范化列表
rankings=[(total/simSums[item],item) for item,total in totals.items()]
# 返回经过排序的列表
rankings.sort()
rankings.reverse()
return rankings
这里,以找出跟Toby最接近的三个人为例:
import recommendations
recommendations.topMatches(recommendations.critics,'Toby',n=3)
得出
(0.9244734516419049, 'Mick LaSalle'),
(0.8934051474415647, 'Claudia Puig')]```
***
####推荐物品
书中用了一个表格来展示这个过程:

比如要为Toby推荐电影,得从他没看过的电影里找,对这些没看过的电影,用欧几里得距离得出其他人跟Toby的相似度(加权),分别乘以他们对这些电影的评价,得出电影的得分(S.x列),再进行加总。
然而有个情况是某个人没看过某电影,(如Puig没看过Lady),那Lady的总评分不是相对少了吗。
所以我们还要做一个动作是:用总计除以有评论的人的相似度之和(Sim.Sum)(相当于减权),就会得到相对公正的结果。
在recommendations.py文件下是这么实现的
利用所有他人评价值的加权平均,为某人提供建议
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
# 不和自己做比较
if other==person: continue
sim=similarity(prefs,person,other)
# 忽略评价值为零或小于零的情况
if sim<=0: continue
for item in prefs[other]:
#只对自己还未曾看过的影片进行评价
if item not in prefs[person] or prefs[person][item]==0:
# 相似度*评价值
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
建立规范化列表
rankings=[(total/simSums[item],item) for item,total in totals.items()]
返回经过排序的列表
rankings.sort()
rankings.reverse()
return rankings
执行
recommendations.getRecommendations(recommendations.critics,'Toby')
得到
```[(3.3477895267131013, 'The Night Listener'),
(2.8325499182641614, 'Lady in the Water'),
(2.5309807037655645, 'Just My Luck')]```
嗯,Toby可能更喜欢'The Night Listener'
以上是基于“人”的推荐,如果我们想知道哪些商品有相似性呢?
***
####相似商品推荐
只需将人和物进行对调:
把```{'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5}} ```
变成```{'Lady in the Water':{'Lisa Rose':2.5,'Gene Seymour':3.0}, 'Snakes on a Plane':{'Lisa Rose':3.5,'Gene Seymour': 3.5} etc}```
在recommendations.py文件下
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
# 将物品和人员对调
result[item][person]=prefs[person][item]
return result
试试:
movies=recommendations.transformPrefs(recommendations.critics)
recommendations.topMatches(movies,'Superman Returns')
得到:
```[(0.6579516949597695, 'You, Me and Dupree'),
(0.4879500364742689, 'Lady in the Water'),
(0.11180339887498941, 'Snakes on a Plane'),
(-0.1798471947990544, 'The Night Listener'),
(-0.42289003161103106, 'Just My Luck')]```
也可以基于电影得出“喜欢它的人”
recommendations.getRecommendations(movies,'Just My Luck')
```[(4.0, 'Michael Phillips'), (3.0, 'Jack Matthews')]```
>学到哪儿,写到哪儿。暂告一段落。
>本人最近在求职,坐标北京,数据分析相关,行业不限,希望看到的简友帮忙推荐,当然也希望HR能看到
.