以处理流程为骨架来学习方便依照框架的充实细节又不失概要(参考下图机器学习处理流程的一个实例<
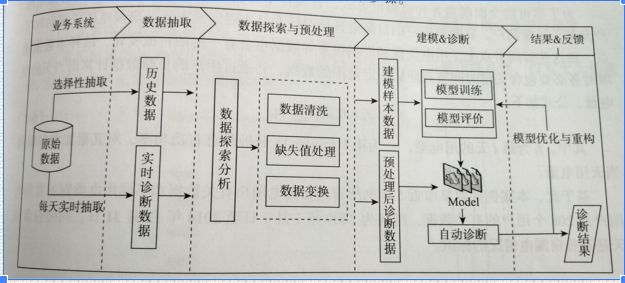
本"故事"以<
- 分析目标是基于用户每天的用电量为基本数据来预测用户是否窃漏电.
- 首先,通过数据分析总结得到三个指标,
- 然后,分别选用神经网络和决策树来训练得出预测模型。
- 之后,对训练数据的预测结果进行混淆矩阵(Confusion Matrix)运算
- 最后,对测试数据进行预测并进行ROC(Receiver Operating Characteristic)评估,看哪个更优.
三个指标和数据样例如下:
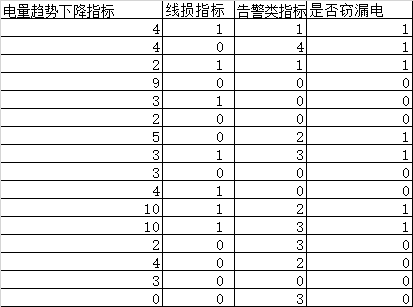 图-2-数据-model.xls样例数据
图-2-数据-model.xls样例数据
电量趋势下降指标: 如果电量趋势不断下降,则有窃电可能
线损指标:供电线路损失的比例,考虑前后几天的增长率如果大于1%则有窃电可能
告警指标:电表终端报警,如电压缺相,电压断相等的次数
顺便再次告诫自己:纸上得来浅,代码同行。以下代码用到了Python 的pandas(数据分析和处理), keras(神经网络), matplotlib(可视化),sklearn(机器学习)包,对<
1 导入数据
2 用训练数据建立决策树模型
3 对训练数据用混淆矩阵评估决策树模型的预测结果
4 用训练数据建立神经网络模型
5 对训练数据用混淆矩阵评估神经网络模型的预测结果
6 用学习得到的决策树模型和神经网络模型跑测试数据来预测
7 用ROC曲线评估,选出更优的一个模型
代码包括cm_plot.py 和model.py如下,代码环境主要包括( Ubuntu 14.04.2 LTS, python2.7, keras 2.0.4, tensorflow 1.0.0),测试代码时在引入keras时报错,后升级tensorflow,并指定其为keras的backend后跳出了坑:
# cm_plot.py 文件,包括了混淆矩阵可视化函数,
# 放置在python的site-packages 目录,供调用
# 例如:~/anaconda2/lib/python2.7/site-packages
#-*- coding: utf-8 -*-
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
#-*- coding: utf-8 -*-
# model.py构建并评估CART决策树和LM神经网络算法
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打散数据
datafile = 'model.xls' #数据(如图-2所示)
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签,'1'表示窃漏电,'0'表示没有窃漏电
data = data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
# 把数据的80%用来训练模型,20%做模型测试和评估,此处用到训练集-验证集二划分
p = 0.8 #设置训练数据比例,
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
#构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
treefile = 'tree.pkl' #模型输出名字
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3], train[:,3]) #训练得出决策树模型
#保存模型
from sklearn.externals import joblib
joblib.dump(tree, treefile)
#用混淆矩阵可视化函数画图
from cm_plot import * #导入混淆矩阵可视化函数
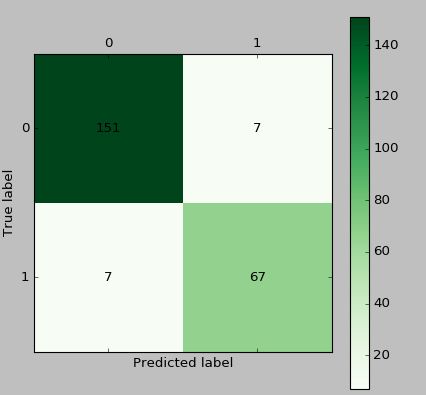
cm_plot(train[:,:3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果如下
#构建LM神经网络模型
import os
os.environ['KERAS_BACKEND']='tensorflow'#先设置keras 采用tensorflow 作为Backend
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = 'net.model' #构建的神经网络模型存储路径
net = Sequential() #建立神经网络
net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam', class_mode = "binary") #编译模型,使用adam方法求解
net.fit(train[:,:3], train[:,3], epochs=1000, batch_size=1) #训练模型,循环1000次
#保存模型
net.save_weights(netfile)
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形这里要提醒的是,keras用predict给出预测概率
#用混淆矩阵可视化函数画图
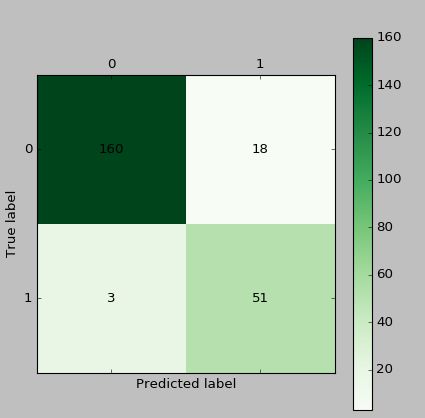
cm_plot(train[:,3], predict_result).show() #显示混淆矩阵可视化结果
# 用ROC曲线选取较优模型,曲线越贴近左上,模型越优.
from sklearn.metrics import roc_curve #导入ROC曲线函数
import matplotlib.pyplot as plt #导入可视化包
# 上面的图是决策树模型下用测试数据跑出的ROC曲线
plt.subplot(211)
fpr1, tpr1, thresholds1 = roc_curve(test[:,3], tree.predict_proba(test[:,:3])[:,1], pos_label=1)
plt.plot(fpr1, tpr1, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
# 下面的图是神经网络模型下用测试数据跑出的ROC曲线
predict_result = net.predict(test[:,:3]).reshape(len(test))
plt.subplot(212)
fpr2, tpr2, thresholds2 = roc_curve(test[:,3], predict_result, pos_label=1)
plt.plot(fpr2, tpr2, linewidth=2, label = 'ROC of LM',color='red') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
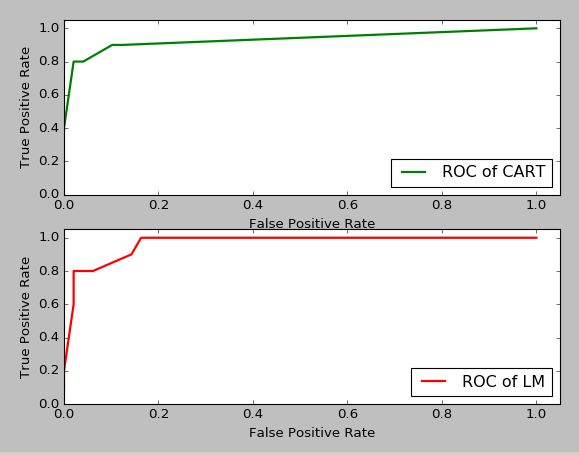
从图中比较LM神经网络较优,是骡子是马,还是拉出来溜溜,当然还要看在实际数据中的表现喽:-)通过例子咱们也总结一下,把相关的知识整理整理.
为什么要评估模型?
一句话,想找到最有效的模型.模型的应用是循环迭代的过程,只有通过持续调整和调优才能适应在线数据和业务目标.这跟我们买鞋子有一比,鞋子是模型,左挑右选,好吗,选了个合适的,可是这脚,它不断有变化,怎么办,持续调呗.
选用模型开始都是假设数据的分布是一定的,然而数据的分布会随着时间的移动而改变,这种现象称为分布漂移(Distribution Drift)。验证指标可以对模型在不断新生的数据集上进行性能跟踪。当性能开始下降时,说明该模型已经无法拟合当前的数据了,因此需要对模型进行重新训练了。 模型能够拟合新的数据称为模型的泛化能力。就像我们上面的例子,训练模型时用的是历史数据,可是数据是不停的产生跟新的,机器学习怎么学,请看下一个问题.
怎么检验和评估模型?
机器学习过程分为原型设计阶段(Prototyping)与应用阶段(Deployed), 其中有原型设计阶段(Prototyping)的离线评估与应用阶段(Deployed)的在线评估(online evaluation).
Prototyping阶段是使用历史数据训练一个适合解决目标任务的一个或多个机器学习模型,并对模型进行验证(Validation)与离线评估(Offline evaluation),然后通过评估指标选择一个较好的模型。我们上面的例子就是Prototyping.
Deployed阶段是当模型达到设定的指标值时便将模型上线,投入生产,使用新生成的在线数据来对该模型进行在线评估(Online evaluation),在线测试不同于离线测试,有着不同的测试方法以及评价指标。最常见的便是A/B testing,它是一种统计假设检验方法。
离线评估和在线评估采用不同的评估指标,在对模型进行离线评估时是采用偏经验误差的方法,在在线评估时会采用业务指标,如设备使用效率(OEE), 用户点击率等.
通过检验和评估可能选择单一模型,也能使用多个模型混合.那到底怎么选呢?
评估过程中如何调优?
找到合适的鞋子是一个复杂的过程,还好,现在很多算法都很好的打包成包依照不同的开发语言发布出来,我们上面的例子就是一个很好的说明,也有各类软件(SAS, SPSS, Rapidminer, Knime等),其实以上代码完全可以用词类工具实现.机器学习模型建立过程是一个参数学习与调优的过程。对模型进行训练,便是模型参数的学习更新过程,除了模型参数还有超参数(hyperparameters)。例如logistic回归中的特征系数为模型参数,需要使用多少个特征进行表征,特征的数目这个参数便是该模型的超参数。可以用格搜索(grid search)、随机搜索(random search)以及启发式搜索(smart search)等进行Hyperparameter tuning, 从超参数空间中寻找最优的值。
格搜索(grid search)
格搜索便是将超参数的取值范围划分成一个个格子,对每一个格子所对应的值进行评估,选择评估结果最好的格子所对应的超参数值。例如,对于决策树叶子节点个数这一超参数,可以将值划分为这些格子:10, 20, 30, …, 100, …;
随机搜索(random search)
它是格搜索的变种。相比于搜索整个格空间,随机搜索只对随机采样的那些格进行计算,然后在这中间选择一个最好的。因此随机搜索比格搜索的代价低。
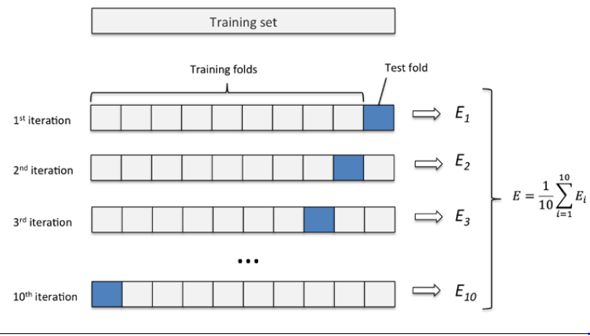
在离线评估阶段从历史数据据获取数据集校验模型的方法包括训练集-验证集二划分校验(Hold-out validation)、交叉校验(Cross-validation), 另一种方式是重采样技术,如bootstrapping与Jackknife,此类方法可以充分利用现有数据信息,一定程度减少过拟合。 ( 参考百度百科抽样数据方式)
交叉验证
评估指标 (Evaluation Matrics)是什么?
评估指标是把"尺子",用来评判模型优劣水平的算法,不同的机器学习模型有着不同的"尺子",同时同一种机器学习模型也可以用不同的尺子来评估,只是每个尺子的的着重点不同而已。对于分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、推荐(recommendation),很多指标可以对其进行评价,如精确率-召回率(precision-recall),可以用在分类、推荐、排序等中.以下是各类"尺子"的定义,用到时才看,仅供参考.
错误率,精度,误差的基本概念:
错误率(error rate)= a个样本分类错误/m个样本
精度(accuracy)= 1 -错误率
误差(error):学习器实际预测输出与样本的真是输出之间的差异。
训练误差(training error):即经验误差。学习器在训练集上的误差。
泛化误差(generalization error):学习器在新样本上的误差。
.
分类器评估指标
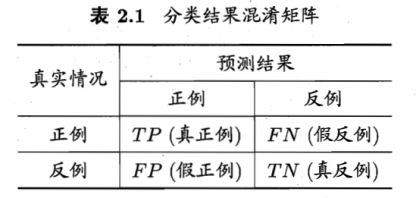
对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:
真正例(True Positive,TP):真实类别为正例,预测类别为正例。
假正例(False Positive,FP):真实类别为负例,预测类别为正例。
假负例(False Negative,FN):真实类别为正例,预测类别为负例。
真负例(True Negative,TN):真实类别为负例,预测类别为负例。
然后可以构建混淆矩阵(Confusion Matrix)如下表所示,就是我们例子中用到的。
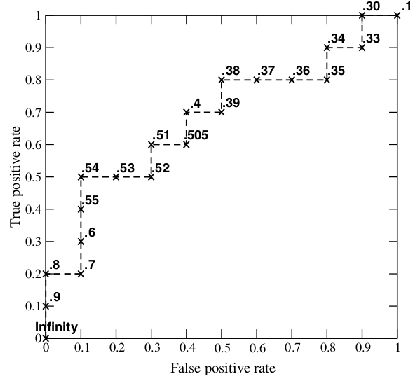
ROC AUC(Area Under ROC Curve): ROC 曲线和 AUC 常被用来评价一个二值分类器的优劣。若一个学习器的ROC曲线被另一个包住,后者的性能能优于前者;若交叉,判断ROC曲线下的面积,即AUC.
ROC: 纵轴:真正例率 TPR;横轴:假正例率FPR

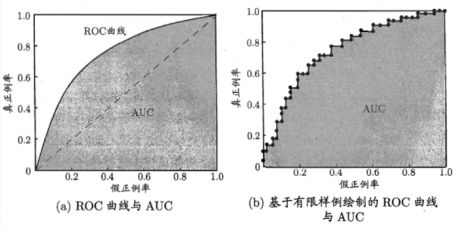
先看图中的四个点和对角线:
第一个点,(0,1),即 FPR=0, TPR=1,这意味着 FN(false negative)=0,并且FP(false positive)=0。这意味着分类器很完美,因为它将所有的样本都正确分类。
第二个点,(1,0),即 FPR=1,TPR=0,这个分类器是最糟糕的,因为它成功避开了所有的正确答案。
第三个点,(0,0),即 FPR=TPR=0,即 FP(false positive)=TP(true positive)=0,此时分类器将所有的样本都预测为负样本(negative)。
第四个点(1,1),分类器将所有的样本都预测为正样本。
对角线上的点表示分类器将一半的样本猜测为正样本,另外一半的样本猜测为负样本。因此,ROC 曲线越接近左上角,分类器的性能越好。
例如有如下 20 个样本数据,Class 为真实分类,Score 为分类器预测此样本为正例的概率。
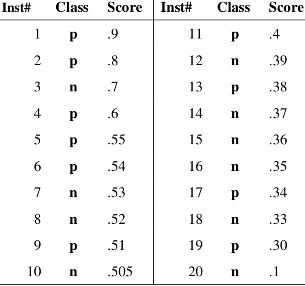
- 按 Score 从大到小排列依次将每个 Score 设定为阈值,
- 然后这 20 个样本的标签会变化,当它的 score 大于或等于当前阈值时,则为正样本,否则为负样本。
- 这样对每个阈值,可以计算一组 FPR 和 TPR,此例一共可以得到 20 组。
- 当阈值设置为 1 和 0 时, 可以得到 ROC 曲线上的 (0,0) 和 (1,1) 两个点。
AUC:
AUC考虑的是样本预测的排序质量,因此它与排序误差有紧密联系。给定
m+个正例,m-个反例,令D+和D-分别表示正、反例集合,则排序
”损失”定义为:
Lrank对应ROC曲线之上的面积:若一个正例在ROC曲线上标记为(x,y)
,则x恰是排序在期前的所有反例所占比例,即假正例,因此:
准确率,又称查准率(Precision,P):
召回率,又称查全率(Recall,R):
F1值:
F1的一般形式
Β>0度量了查全率对查准率的相对重要性;β=1退化为F1;β>1查全率有更大影响;β<1查准率有更大影响。
宏平均(macro-average)和微平均(micro-average)一般用在文本分类器, 如果只有一个二分类混淆矩阵,那么用以上的指标就可以进行评价,但是当我们在n个二分类混淆矩阵上要综合考察评价指标的时候就会用到宏平均和微平均。
宏平均(Macro-averaging): 是先对每一个类统计指标值,然后在对所有类求算术平均值。宏平均指标相对微平均指标而言受小类别的影响更大。
微平均(Micro-averaging):是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。
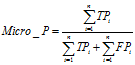
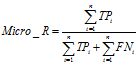
平均准确率(Average Per-class Accuracy):
为了应对每个类别下样本的个数不一样的情况,计算每个类别下的准确率,然后再计算它们的平均值。
对数损失函数(Log-loss):
在分类输出中,若输出不再是0-1,而是实数值,即属于每个类别的概率,那么可以使用Log-loss对分类结果进行评价。这个输出概率表示该记录所属的其对应的类别的置信度。比如如果样本本属于类别0,但是分类器则输出其属于类别1的概率为0.51,那么这种情况认为分类器出错了。该概率接近了分类器的分类的边界概率0.5。Log-loss是一个软的分类准确率度量方法,使用概率来表示其所属的类别的置信度。Log-loss具体的数学表达式为:

其中,yi是指第i个样本所属的真实类别0或者1,pi表示第i个样本属于类别1的概率,这样上式中的两个部分对于每个样本只会选择其一,因为有一个一定为0,当预测与实际类别完全匹配时,则两个部分都是0,其中假定0log0=0。其实,从数学上来看,Log-loss的表达式是非常漂亮的。我们仔细观察可以发现,其信息论中的交叉熵(Cross Entropy,即真实值与预测值的交叉熵),它与相对熵(Relative Entropy,也称为KL距离或KL散度, Kullback–Leibler divergence.)也非常像。信息熵是对事情的不确定性进行度量,不确定越大,熵越大。交叉熵包含了真实分布的熵加上假设与真实分布不同的分布的不确定性。因此,log-loss是对额外噪声(extra noise)的度量,这个噪声是由于预测值域实际值不同而产生的。因此最小化交叉熵,便是最大化分类器的准确率。
回归模型评估指标
回归是对连续的实数值进行预测,即输出值是连续的实数值,而分类中是离散值。对于回归模型的评价指标主要有以下几种:
RMSE(root mean square error,平方根误差),其又被称为RMSD(root mean square deviation),RMSE对异常点(outliers)较敏感,如果回归器对某个点的回归值很不理性,那么它的误差则较大,从而会对RMSE的值有较大影响,即平均值是非鲁棒的。其定义如下:
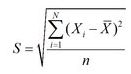
Quantiles of Errors 为了改进RMSE的缺点,提高评价指标的鲁棒性,使用误差的分位数来代替,如中位数来代替平均数。假设100个数,最大的数再怎么改变,中位数也不会变,因此其对异常点具有鲁棒性。
先到此,分享快乐!
参考:
[1] http://www.jianshu.com/p/42bfe1a79d12 "不会停的蜗牛-[什么是ROC ACU]"
[2] http://blog.csdn.net/heyongluoyao8/article/details/49408319 "我和我追逐的梦~~~-[机器学习模型评价(Evaluating Machine Learning Models)-主要概念与陷阱]"
[3] http://www.cnblogs.com/kuotian/p/6151541.html "koutian-[机器学习总结之第二章模型评估与选择]"
[4] http://blog.csdn.net/pipisorry/article/details/52574156 "皮皮blog-[机器学习模型的评价指标和方法]"
[5] http://scikit-learn.org/0.17/modules/model_evaluation.html#scoring-parameter "Python Scikit-Learn-[3.3. Model evaluation: quantifying the quality of predictions]"
[6] https://item.jd.com/11821937.html [<
[7] https://item.jd.com/11867803.html [<<机器学习>> 周志华]