作者:Rockelbel,两年互联网PM,AI转型学习中,偏好NLP方向
上一篇文章介绍了机器学习和神经网络等一系列概念,这篇文章将主要对AI的关键技术及应用层面的内容做个简单的总结。考虑到篇幅可能过长,本文仅介绍计算机视觉相关技术,其他如自然语言处理、专家系统、知识图谱等技术会在下一篇文章中补充。
一、AI产业结构
本来打算把产业结构放在最后一部分,后来考虑了一秒钟,这篇文章会更加偏实际应用,对人工智能产业链有一个宏观的认识可能更有帮助。下图是一张关于人工智能产业生态的图谱,很多机构都做过类似的图,大同小异。技术层和应用层是本文的主要内容,这里先对基础层的内容做个简单介绍。
基础层包括提供算力的高性能芯片、底层开源框架、传感器等,作为人工智能技术的底层支持。我们经常听到这样一种说法,这次人工智能的热潮很大程度是基于三个领域的突破:大数据支持、算力的提升、算法的突破。这些都属于基础层的范畴。
1、高性能处理器
高性能处理器:CPU、GPU、FPGA(半定制化的可编程电路)、TPU(一种ASIC,谷歌专门为机器学习打造的处理器)。这部分的内容尽管去百度,找不到算我输。
下图展示了CPU和GPU的结构差别,绿色区域是计算单元,橙色区域是储存单元,“相对CPU而言,为什么GPU更适合用于机器学习”这个问题大家应该能比较直观的理解了。

2、云服务
云服务:Amazon ML、Google Cloud ML、Microsoft Azure ML、Databricks、Haven OnDemand、IBM Watson 和 Predictive Analytics、阿里云 ML、腾讯TML、百度BML
很多大厂都提供了各自的机器学习云平台服务,国外像Google/Amazon/Microsoft都是布局人工智能比较早的企业,提供的服务相对更加成熟
相关阅读:不可错过的精彩回顾:6种云机器学习服务
3、开源库或计算框架
开源库或计算框架:TensorFlow(大名鼎鼎)、Torch(基于Lua语言)、Caffe(Facebook,基于C++)、MXNET(Amazon,很强大)、Keras(易于使用,黑箱子,适合新手)、PaddlePaddle(百度)、Theano、sclikt-learn、Deeplearning4j(基于java语言)、Deepmat、Lasagne、Neon、Pylearn、Chainer、Turicreate(Apple2017年推出)、PyTorch(Facebook)、CNTK (Microsoft)......
专用领域的开源库:OpenCV、OpenFace(人脸识别)、DarkNet-YOLO(物体检测)......
各种开源框架数不胜数,这里列举了一些比较知名和用户比较广泛的框架,实际的项目也并不一定使用单一的框架。
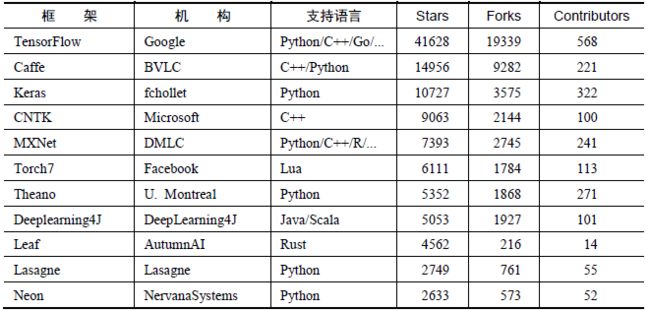
相关阅读:主流深度学习框架对比
基础层的内容就介绍(搬运)到这里,其他还有如Decker容器、机器学习中的可视化解决方案等等概念感兴趣的可以去了解一下。
二、关键技术及应用领域
人工智能的研究领域包括计算机视觉、自然语言处理、机器人、专家系统等,。根据AI应用范围或发展层次可以分为专用人工智能(ANI)、通用人工智能(AGI)、超级人工智能(ASI)三种,目前的AI还停留在专用人工智能的阶段,这阶段主要是通过感知和记忆存储来实现特定领域或特定功能,如计算机视觉、语音识别、智能推荐等等,目前这些领域有较为成熟的成果。
通用人工智能,一般指Agent基于认知学习和决策执行的能力,有一定的自我意识,能够真正理解人类的情绪语言,实现多个领域的综合智能。
超级人工智能,定义为具有完整的自我意识,独立的价值观世界观,能够自我创新,甚至超过人类。这种AI层次仅停留在想象中。
“可以预见的是,在由专业领域向通用领域过度的过程中,自然语言处理与计算机视觉两个方向将会成为人工智能通用应用最大的两个突破口。”(极客公园)
目前深度学习在自然语言处理和计算机规觉领域已取得重大的进展,其中语音识别、 图像识别已达到商业化的成都。在各类比赛中,图像识别和语音识别错误率达到甚至超过人类水平。
1、计算机视觉领域(Computer Vision)
首先对区分这三个概念:计算机视觉、机器视觉、图像处理
计算机视觉:指对图像进行数据采集后提取出图像的特征,一般处理的图像的数据量很大,偏软件层;
机器视觉:处理的图像一般不大,采集图像数据后仅进行较低数据流的计算,偏硬件层,多用于工业机器人、工业检测等;
图像处理:对图像数据进行转换变形,方式包括降噪、、傅利叶变换、小波分析等,图像处理技术的主要内容包括图像压缩,增强和复原,匹配、描述和识别3个部分。
计算机视觉是指利用计算机来模拟人的视觉,是人工智能中的“看”。从技术流程上来说,分为目标检测、目标识别、行为识别三个部分。根据识别的目标种类可以分为图像识别、物体识别、人脸识别、文字识别等。在智能机器人领域,计算机视觉可以对静态图片或动态视频中的物体进行特征提取、识别和分析,从而为后续的动作和行为提供关键的信息。
近年来,基于计算机视觉的智能视频监控和身份识别等市场逐渐成熟扩大,计算机视觉的技术和应用趋于成熟,广泛应用于制造、 安检、图像检索、医疗影像分析、人机交互等领域。
下图展示了计算机视觉的技术分类,基本上可以分为静态内容识别和动态内容识别两大类,实际上在国内计算机视觉领域,动静态图像识别和人脸识别是主要研究和应用方向。当然很多应用需要计算机视觉和其他关键AI技术相结合,比如AR/VR的主要技术是人机交互和计算机视觉。
常用技术分类
1.1图像特征提取与描述
特征提取是很多CV技术的前置操作,比如判断两幅头像是否是同一个人,计算机根据图像的某些局部特征,如边缘和线条的特征。
1图像特征种类
图像的颜色特征、纹理特征、形状特征、空间关系特征(应用于机器人的姿态识别问题,确定一个三维物体的方位等)、局部特征
图像特征描述
图像特征描述的一个核心就是鲁棒性(robust,这个词大家肯定听过吧,出场率极高)和可区分性,而这两点常常是矛盾的。
鲁棒性是指一个特征应该适用于不同的图像变换情况,这就要求这个特征比较“粗糙”,例如一个茶杯从上方看和从侧面看都应该是同一个茶杯。可区分性是指,能够区分一些比较相似的局部特征,显然其鲁棒性往往比较低。
相关阅读:局部图像特征描述总结
1.2图像分类
大家在新闻上肯定看到过这些比赛——ImageNet(李飞飞创立)、Kaggle、MSCOCC、阿里天池等等(以及ILSVRC、PASCAL VOC 2012),这些比赛的常设项目一般为不同领域下的图像识别分类与场景分类,此外还有一些物体探测追踪之类的。(这些比赛一般使用【top-5错误率】的高低来衡量算法的优异,有兴趣的可以去了解一下)
常用算法:卷积神经网络CNN
常用神经网络模型:AlexNet、 VGG、 GoogLeNet、 ResNet)
1.2.1图像分类(Image Classification)
根据图像正反映出的不同特征,依照特征把图片分类。显然分类技术有基于色彩的、基于纹理的、基于形状的、基于空间关系的。
举个栗子,锤子手机的有个桌面整理的功能,把颜色相似的图片分类到一屏,这里应用了基于颜色的图像分类技术。
1.2.2场景分类(Scene Classification)
场景分类:基于对象(根据场景中出现的对象区分,例如出现床可能是卧室)、基于区域、基于上下文、基于Gist特征
推荐一篇相关文章:基于深度学习的场景分类算法
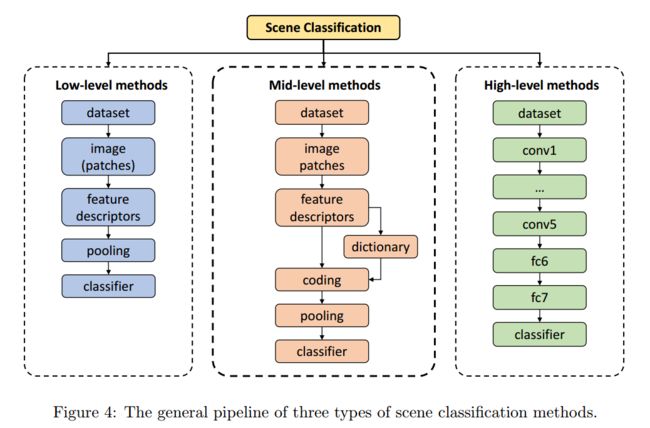
从上面这张图可以大概了解场景分类大概的流程,当然前提得了解pooling、feature descriptors这些词的含义(在后续介绍CNN/RNN的文章里会详细描述)。上图来源文章:场景分类摘录
1.3图像检测(Image Detection)
图像检测是通过获取和分析图像特征,从图像中定位出预设的目标,并准确判断目标物体的类别,最后给出目标的边界,边界一般是矩形,不过也有圆形的情况,下图是一个人脸检测的示例。
常用算法:区域卷积神经网络/R-CNN
常用神经网络模型:SPPnet、Fast R-CNN、Faster R-CNN、R-FCN
图像检测应用领域:人脸识别、医学影像、智能视频监控、机器人导航、基于内容的图像检索、基于图像的绘制技术、图像编辑和增强现实等领域。(百度百科)
1.3.1物体检测(Object Detection & Localization)
物件检测分为静态物体检测和动态物体检测,并且其一般和物体分类算法结合,多应用于安防领域(行人检测、智能视频分析、行人跟踪)、交通领域(交通场景的物体识别、车辆计数、逆行检测、车牌检测和识别)、互联网领域(图像检测、相册自动归类)。
下图展示了当前物体检测技术的一些应用难点,包括图片的复杂光照情况、非刚性物体形变(人、动物的各种姿势)、低分辨率、图片模糊(商汤科技对此有比较好的处理技术)等

这篇文章较为系统的介绍了一些检查算法的实现原理,推荐阅读:干货 | 物体检测算法全概述:从传统检测方法到深度神经网络框架
1.3.2行人检测(Pedestrian Detection)
行人检测,顾名思义就是将图片中的行人检测出来,并输出目标边界,并且检测的常常是多个行人目标。将一个视频流中的行人的轨迹关联起来,就是行人跟踪,多个目标即多人跟踪。另外一个应用称为行人检索,或行人再识别,即给定一个待检索行人,从图集或视频中找到。(城市里处处摄像头,天网恢恢啊)
行人检测应用领域:人工智能系统、车辆辅助驾驶系统、智能机器人、智能视频监控、人体行为分析、智能交通等领域。(百度百科)
相关阅读:行人检测(Pedestrian Detection)资源、行人检测(看了一圈,还是百科说得最清楚)
1.3.3人脸检测&人脸识别(Face Detection &Recognition)
人脸检测是人脸识别中的一个关键环节,人脸检测指对于一副给定的图像,采用一定的策略对其分析搜索确定其中是否含有人脸,若有人脸则返回人脸边界,以及大小、姿态等信息。
应用领域:身份认证与安全防护(很多app有实人认证)、媒体娱乐(火过一阵子的小偶app)、图像搜索等。
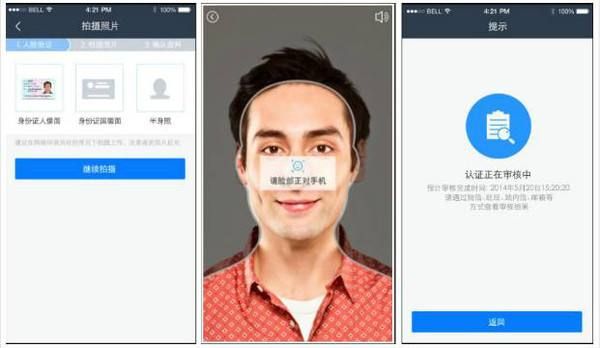

人脸检测是图像检测中的一种,方法基本类似,主要分为六个步骤:预处理、窗口滑动、特征提取、特征选择、特征分类和后处理(挖个坑,这部分后续会详细介绍)
这里插播一句题外话,去年的十月份,CNN的创始人发了一篇关于Capsule Networks(胶囊网络)的论文,大有取代CNN之势。而目前为止,CNNs仍是图像检测分类领域最先进的方法,不过有时候也会出现一些不可描述的问题,比如下图:

不用细说,大家应该也大概知道是什么情况了。可以这样(不严谨的)理解,CNN是由多层的神经网络组成,每一层的神经网络负责识别一类特征,比如目标是识别人脸,可能一层负责识别眼睛的特征,一层负责识别嘴巴的特征,多层神经网络累加起来就会形成一个整体的特征,但是CNN对多个特征之间的空间关系并不能很好的识别,因此就有了上图这样的例子。(关于识别特征这块,有一个分类器的概念,感兴趣的可以去了解一下Haar特征、VJ模型和adaboost分类器)
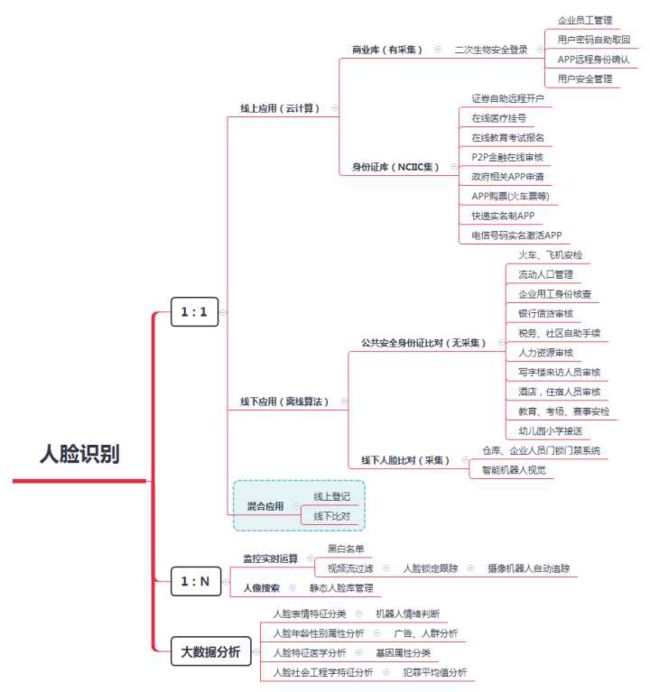
人脸识别应该是目前计算机视觉领域商业化应用落地比较成熟的例子,下面是我搜集到的一张关于人脸识别的一些应用领域情况脑图,需要的可以收藏。图不太清楚,找不到来源网站,如果有知道的朋友可以评论留言我再加上。
1.4图像分割(Image Segmentation)
图像分割指把图像分成若干个特定的、居右独特性质的的区域并提出感兴趣目标的技术。现有的图像分割技术主要分为以下几类:基于阈值、基于区域、基于边缘和基于特定理论的分割方法。图像分割是将数字图像划分为几个互不相交的区域,也是一种标注的过程,即把属于同一区域的像素给与相同的标签。(百度百科)
这么说可能难以理解,下图是自动驾驶领域的一个应用示例,自动驾驶系统需要从场景中识别出各类物体,并根据先验知识,即预设好的条件进行判断,如应该在road区域行驶、遇到Pedestrian和Vehicle区域应该减速或停车、识别Traffic Light区域的含义等等。
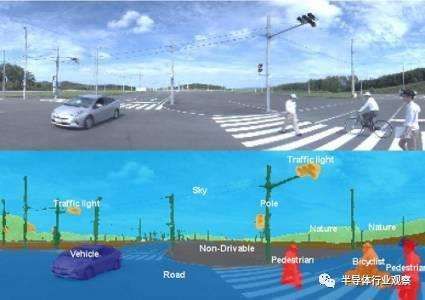
图像分割技术下有三个比较常见的分支——视觉显著性检测、物体分割、语义分割。
1.4.1视觉显著性检测(Visual Saliency Detection)
视觉显著性检测指通过算法模拟人的视觉特点,提取图像中可能是人类感兴趣的区域,及显著区域。
这里涉及到另一个概念,视觉注意机制(Visual Attention Mechanism),即面对一个场景时,人类自动对感兴趣区域进行处理而自动忽略不显著的区域。

人的视觉注意有两种策略机制:
自下而上、基于数据驱动的注意机制:收感知数据驱动,将人的视觉重点引导至场景中的显著区域,这些区域通常与周围有较强的对比度或与周围有明显的区别,包括颜色、形状、亮度等特征。比如一副黑色图片中的一个白点,视觉自然而然的会被引导至白点。
自上而下、基于任务驱动的、基于目标的注意机制:有根据先验知识、预期和当前的目标来计算图像的显著性区域。在视频中找到人,就是一个任务驱动的行为。
关于认知注意模型等内容,参考这篇文章:视觉显著性检测
关于注意力流等内容,可以去关注张江博士,他的书《科学的极致:漫谈人工智能》中有几章对注意力机制的描述,比较直观易懂。
1.4.2物体分割(Object Segmentation)
物体分割一般是用于把单张图片中的一个或多个物体分割出来,物体分割常常和物体识别共同使用。相比于物体检测只能返回一个矩形边界,物体分割算法可以精确的描绘出所有物体的轮廓,从像素成眠上把各个物体分割出来。
常用算法:Mask R-CNN
下图展示了物体分割的输出效果,基本上可以实现把图片中的物体的轮廓描绘出来。(设计师再也不用辛苦的抠图了...)
1.4.3语义分割/Semantic Segmentation
图像语义分割,也成为语义标注,简单而言就是给定一张图片,对图片上的每一个像素点分类,不区分物体,尽关心像素。
那么它与物体分割有什么不同呢?语义分割重在语义,即图像中同一个类别的物体将会被划分至同一个区域,如下右图有两只牛,其都被划分至cow区域;而上图中可以看到,多个人或摩托车都被单独的区分开来。
1.5图像描述(Image Captioning)
(图说)图像描述也称为Dense Captioning,其目标是在给定一张图像的情况下,得到图像中各个部分的自然语言描述。图像描述问题融合了计算机视觉和自然语言处理两大方向,是AI解决多模式跨领域问题的典型技术。与英文相比,中文的描述常常在句法词法的组合上更加灵活,算法的挑战也更大。
假设我们有一个很大的数据库,每条记录是图像以及它对应的语句描述。每条语句的词汇片段其实对应了一些特定的但是未知的图像区域。我们的方法是推断出这些词汇片段和图像区域的对应关系,然后使用他们来生成一个泛化的语言描述模型。
常用算法:Vanilla-RNN、LSTM、GRU
相关阅读:【图像理解】自动生成图像的文本描述
1.5.1图像标注
图像标注是从根据一幅图自动生成一段描述性的文字,小时候的“看图说话”。图像描述需要把图像中各个物体均生成描述,而图像标注只对图片整体进行描述。
图像标注技术一般分为典型的图像标注和基于注意力的图像标注。
相关阅读:看图说话的AI小朋友——图像标注趣谈(上)、「Show and Tell」——图像标注(Image Caption)任务技术综述
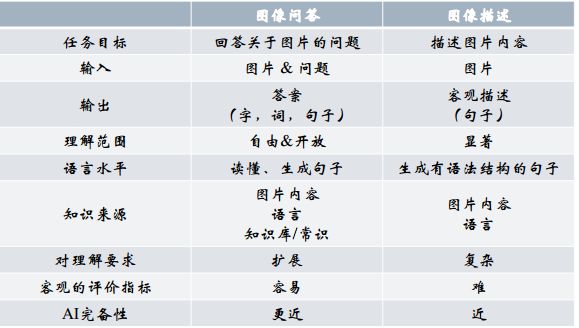
1.6图像问答(Image Question Answering)
图像问答即回答与图片内容相关的问题,输入图片及问题,系统输出答案。15年的时候有一个新闻不知道大家知不知道,李彦宏首次向世界展示百度最新Image QA图文问答技术,也就是下图。新闻链接

图像问答结合了注意力机制及外部知识库后,识别能力能够有显著的提升。
与图像描述类似,图像问答同样是结合计算机视觉与自然语言处理技术的一种应用,下图展示了两者之间的差异。
1.7图像生成(Image Generation)
这大概是这篇文章最好理解的概念了,图像生成——根据一定的条件生成图像。比如上篇文章提到的prisma,根据预设的风格和图片生成一张全新的图片,这中间就是应用了图像生成的技术。
使用GAN(对抗生成网络)来做图像生成,目前是最流行也是最热门的领域。当然,也可以使用MRF(马尔科夫随机场)、CNN来进行图像生成。
GAN也可以用于根据一段文本描述来生成图像,或根据一段简笔画来生成图像等等。
相关阅读:GAN之根据文本描述生成图像、【实战】GAN网络图像翻译机:图像复原、模糊变清晰、素描变彩图
注意啦!!!推荐大家一个好玩的网站(Demo),大家可以体验一下,通过一副简笔画来生成一幅完整的图像。

模糊图像复原也是图像生成领域的重要应用,对于各种原因造成的模糊,均有较好的恢复效果,如运动模糊、抖动模糊等。

1.8图像检索(Content-based Image Retrieval)
图像检索大概也是大家用得很多的功能吧,google、百度这些搜索引擎基本都支持以图搜图。图像检索的研究始于上世纪70年代,当时主要是基于文本的图像检索技术(Text-based Image Retrieval),而目前则是基于内容检索(Content-based Retrieval)。
在检索原理上,无论是基于文本的图像检索还是基于内容的图像检索,主要包括三方面:一方面对用户需求的分析和转化,形成可以检索索引数据库的提问;另一方面,收集和加工图像资源,提取特征,分析并进行标引,建立图像的索引数据库;最后一方面是根据相似度算法,计算用户提问与索引数据库中记录的相似度大小,提取出满足阈值的记录作为结果,按照相似度降序的方式输出。(百度百科)
特别说明:本章节中部分示例图片摘选自coldyan的博客