原文标题:《Lessons learned from reading postmortems》
原文链接:http://danluu.com/postmortem-lessons
作者:Dan Luu
翻译:Fanny
我喜欢阅读故障报告,因为它们很具有指导性,而且读起来不像大多数技术文档那么枯燥。我在Google和微软工作的时候,曾经花过大量的时间去阅读里面的故障报告,虽然我(暂时还)没有对里面的重大故障所反映的共性原因做一些正儿八经的分析,不过里面有好一些经典的案例是在我的阅读过程中反复出现的。
异常处理
适当的异常处理其实很难做。隐藏在异常处理的代码中的bug是大问题的主要来源。未被正确处理的异常通常会持续不断地出现,这种情况出现的概率绝对要高于几个不相干的异常出现概率的简单乘积,而持续大量的系统异常往往会导致严重的服务中断。“异常处理很难做好”这个观点在某种意义上其实并不新鲜。当我跟其他人谈起的时候,他们也会表示有相当多的重大故障都是由于未处理好的异常大量产生所导致。可是,虽然道理大家都懂,却没有多少人会重视对异常处理相关的代码做好充分的测试和静态分析工作。
有一篇名为《Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems(简单的测试可以规避大多数的严重故障:对分布式数据集中型系统的生产故障的分析)》的论文(作者:Ding Yuan 等)对此问题有更详细的探讨。这篇论文的观点大致就如其标题所述,在文中作者把“严重故障”的标准定义为:可以导致一个集群崩溃或者导致数据损坏。作者搜集了来自Cassandra、HBase、HDFS、MapReduce以及Redis的数百个bug,并从中筛选出了48个严重错误,然后他们再去分析这些错误产生的原因,发现有92%的的严重错误实际上都是由于没有做好正确的异常处理而引起的。
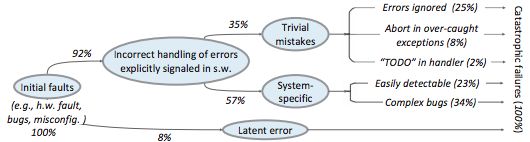
对错误原因做更进一步细化的话,25%的bug是由于忽视了错误的产生,8%是由于捕获了错误的异常,2%是由于虽然捕获了异常但只留了个TODO就什么都没干,另外还有23%的bug是“可以被简单发现的(Easily detectable)”——此处的定义是,任何语句覆盖率检查或者开发者之间的更细致的代码审查都能够发现的、异常处理相关代码中的逻辑错误。另外说个题外话,大家普遍诟病Go语言风格的错误处理,因为它会侵入主代码逻辑,但我却不介意,因为如果你真的想构建一个鲁棒性强的系统,错误检查逻辑本身就是主逻辑的一部分!
那篇论文里面还有很多我没有提到的亮点。比如说,他们使用Jepsen框架带来的匪夷所思的效率提升(98%的严重故障都可以在只有3个节点的集群上重现),另外,他们还深入挖掘分析了非确定性错误的占比(在他们的样例中占比26%)以及这些错误的产生原因,并构建了一个可以发现很多常见故障错误的静态分析工具。
配置
我所见到的大部分严重不可用故障(really bad outages)都是由于配置错误导致的,而不是代码Bug。当我查看可以公开获取的不可用故障报告时,搜索“global outage postmortem”,发现50%的不可用故障都是因为配置改动造成的。虽然这些公开报告并不能代表所有情况,但是我所抽样的公司内部故障报告数据也反映出“配置变动导致了相当一部分不可用故障”这个结论。虽然和异常处理(指本文的第一节Error Handling)一样,配置变更也很容易出问题,但是大多数公司在进行配置变更的时候并不会像发布代码变更一样进行测试以及预发布验证。
除了异常紧急的情况,代码变更一般都不会同时发布到所有的机器上,因为这可能导致全范围的服务不可用。但是每家公司似乎都发生过因为配置变更而导致的全公司范围的服务不可用的故障,而这些配置变更看起来根本没啥问题。比如,发生于2014年11月的Azure宕机故障。我并不是在刻意针对微软,他们最大的竞争对手也发生过类似的事情,他们后来都通过严格执行规范流程来避免类似的事情再次发生。
我也不是刻意针对大公司,如果有什么不一样的话,绝大多数初创公司的情况只是更差,即便是一些不错的初创公司。我所知道的大多数独角兽企业根本就没有用于测试和预发布的环境让开发工程师测试高风险的配置变更。原因很简单,搭建一个和生产环境一样能进行配置变更验证的QA环境太难了。和不系安全带开车一样,绝大多数时间都不会出问题。但是如果开车前还是自己去制作一根安全带,那我肯定也会不系安全带开车了。因此,即便不经QA环境验证就进行配置变更和不系安全带开车一样危险,我还是这么做。
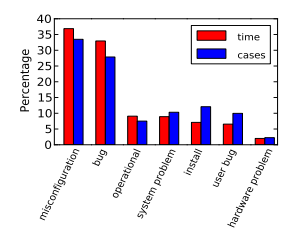
实际上,早在1985年的时候,Jim Gray观察到“运维操作、系统配置,系统维护导致了42%的故障”。之后,也有相当多研究都反映出同样的结果。例如,Rabkin和Katz就总结了如下造成故障的原因:
硬件
简单来说,机器的每一个部分都有可能发生故障。很多组件的故障都能导致数据损坏,而且故障概率通常都比其对外宣传的要高得多。比如,Schroeder, Pinherio和Weber等三人研究了DRAM的故障率后发现,其故障率的实际值要比声称的高一个数量级,静默错误的数量惊人地多,而这实际上也在Google转用ECC RAM之前引发过一些问题。硬件层面的错误检测也可能会出问题,比如网卡的校验和计算(checksums)就不是绝对可靠的,我亲眼见过有问题的数据包被当做合法包给校验通过了。如果你希望通过硬件检查去发现数据损坏错误,在大规模的情况下,你能碰到比想象中要多的问题。
硬件的故障切换也可能会出问题。AWS的故障就是一个典型例子。尽管他们对发电机的故障切换过程有一整套听起来很靠谱的监控和定期检查方案,但当美国东部机房因为风暴造成断电时,其中有一组备用发电机就没有正常启动,导致了AWS的东部地区服务中的相当一部分发生宕机。
人为失误
其实这一部分应该叫做流程失误而非人为失误,因为我觉得把人放在一个有可能一不小心就导致灾难性故障的位置,这种流程本身就是个bug。众所周知,当系统规模变大之后,你必须让这个系统对机器故障有足够的容错性,因为如果你计算一下机器挂掉的频率,你就会发现对这种故障容错性不强的系统有多么的不靠谱。但人类出错的概率比机器挂掉的概率要多得多——请不要误会,我还是喜欢与人打交道的——但如果你不断地把人放在一个他们有可能造成灾难性故障的位置,那他们终究是会引发这个故障的。然而,以下这种情况还是很常见:
“这个操作是有风险的!OK,那我们就找一个非常认真仔细的人来执行这个操作。卧槽!我们现在所有的服务都挂了!”
“因为这是一个高风险的操作,所以我们按照某某某高风险操作指南来执行”——以这种语句开头的故障报告比比皆是,这让我不禁觉得,为了减少人为失误而增加额外的人工检查操作,是一种典型的运维思路。一些常规的运维操作指南会要求好几个人来监控或确认这些操作的执行,或者要求运维人员随时待命以防万一。诚然这些要求是合理的,而且在某种程度上也降低了风险,但是更多的故障报告表明,自动化能把风险降到更低的程度、甚至能完全杜绝风险。例如在一些案例中,操作人员本应该滴水不漏地执行一系列的指令,但偏偏就出错了,而其实这些恰恰是程序所擅长的事情!另外还有一些情况是,操作人员会被要求进行人工的错误检查,这种做法有时候会比较难以自动化、甚至人工还稍微更有优势些(因为人工有可能会察觉程序无法检查出来的错误)。不过,在我所知道的大多数情况下,自动化仍然是相对更划算的选择。
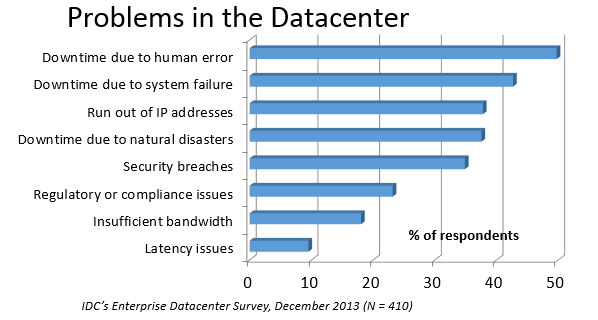
在一份关于数据中心问题起因的IDC调查中,人为失误得到了最高票。
我还发现一个很有趣的现象,就是在公开的故障报告中来看,人为失误的因素其实是很少的。而据我所知,Google和微软的自动化程度比其他大部分公司都要高得多,所以我本以为在他们的故障报告中能找到的人为失误因素应该会更少,但事实却正好相反。我猜可能其他公司不太会在公开的报告中描述由于人为失误造成的故障吧,另一种潜在的可能性是,先进的技术提高了人为因素导致的问题的比重,这种情况在一些行业(比如飞行行业)中确实是存在的。不过我觉得后者的可能性不大,因为在很多公司里手动操作的流程肯定是非常的多。不过我这里也只能是猜测,因为我看不到那些公司内部的故障报告资料库。如果有公司想开展这种类似的分析(匿名的也可以),请与我联系。
监控与告警
缺乏合理的监控永远都不会是产生问题的唯一原因,但往往会是一个重要的因素。跟人为失误因素一样,它们在公开的故障报告中并不具备什么代表性。不过当我与其他公司的一些同行谈及他们近期发生的最严重的事故时,有蛮大一部分人都说是由于没有事先设定正确的告警。当一个严重到足以要写入公开报告的故障发生的时候,他们通常都是靠英勇的运维人员来解决的,但这种英雄主义终究不是长久之计。
有些时候,那些几近灾难的故障是由一些细小的代码bug引起的,这其实也是可以理解的,更多的情况下是因为流程本身存在问题,比如没有一个清晰的告警分配机制,把问题分给了一个不相干的团队debug了半天也没搞好;再比如说,缺少oncall备份机制,如果系统发生了数据丢失或损坏的问题但oncall人员没有注意到(这种情况是不可避免的),这个问题可能会持续好几个小时都没人发现。
2003年的美加大停电就是一个很好的例子。一开始可能只是一小范围的电力中断或者服务降级,但由于缺乏一系列的告警机制(当然还有其他原因)最终酿成大祸。
并非结论
我并不想在这里下什么结论或者号召大家做点什么,因为我还想再做一些更严谨的数据分析。我还应该查找哪些资料?还有什么常见的故障类型我需要考虑?我是真的不知道,希望有人能告诉我还有些什么我是没有考虑到的,请在推特上联系我(@danluu)。另外这里是我正在搜集的一些可公开的故障报告。
后面我会再抽出时间来做一次全面、正规的分析。虽然这数千份的故障报告我还没分析完,但我也会从现在开始做一些改变。我会在code review的时候花相对更多的精力在异常处理的部分,而非正常的逻辑部分,另外我还会花更多的时间去检查流程问题并说服大家去修正这些问题。
有个事情我觉得挺奇怪的,当我跟别人谈论上述的这些点时,总是有人告诉我这些道理大家都懂,但依然还是有很多故障是由这些“大家都懂”的事情引起的。比如有一次就有个人告诉我,他们公司刚发生了一起故障,导致一个价值好几十亿美金的服务中断,而故障的起因恰恰就是如我所述。有时候大家都懂的事情并不代表大家都能做到。
其他
Richard Cook写的How Complex Systems Fail提供了更通用的方法论,《The Checklist Manifesto》就是受此启发而来,这本书挽回过人命的损失。
Allspaw与Robbin的Web Operations: Keeping the Data on Time在web app的场景中谈论了同样的话题,Allspaw还有一篇很不错的关于其他领域的相关文章值得一看.
在我更熟悉的一些领域,研究故障原因的历史更是由来已久,其中一些比较重要的如:Jim Gray写的Why Do Computers Stop and What Can Be Done About It?(1985),Oppenheimer 等人写的Why Do Internet Services Fail, and What Can Be Done About It?(2003),Nagaraja等人写的Understanding and Dealing with Operator Mistakes in Internet Services(2004),Barroso 等人写的The Datacenter as a Computer(2009),Rabkin与Katz写的How Hadoop Clusters Break(2013),Xu等人写的Do Not Blame Users for Misconfigurations.
另外,在飞行器可靠性方面也有相当多的研究,这篇关于这数十年来的生产过程的演进的文章写得非常精彩,不过我不确定它是否具备通用的指导意义。
说个题外话,我发现一个有趣的事情,就是提高系统的运行时间(uptime)和可靠性是有多么的困难。在1974年,Ritchie和Thompson写道一个系统“仅依靠40000美元”就能维持98%的运行时间,10年之后,Jim Gray把99.6%定义为一个合理的标准。当然现在我们可以做得更好,但这里面的复杂度依然是非常的高。
鸣谢
感谢Leah Hanson, 佚名, Marek Majkowski, Nat Welch, Joe Wilder, Julia Hansbrough对本文的初稿提供了意见,其中佚名的那位,如果你希望实名的话,请通过Zulip联系一下我。其余5位人士中,有3名来自Google,1名来自Cloudflare。我向来都是欢迎评论或批评的,不过这次我特别希望能听到来自小公司的同行的评价,本文的这些观点是否对你们具备通用性?
感谢gwern和Dan Reif对本文的指正。
声明:
本译文仅供个人研习、欣赏语言之用,谢绝任何转载及用于任何商业用途。本译文所涉法律后果均由本人承担。本人同意平台在接获有关著作权人的通知后,删除文章。