文章来源:https://github.com/laoyang360/deep_elasticsearch/blob/master/es_accumulate/201805_report.md
问题1、新的kafka集群监控系统使用golang开发
monitoringkafkaGolang
开源地址:https://github.com/kppotato/kafka_monitor
项目使用:golang开发,数据库:prometheus 图形:grafana
问题2、请教elasticsearch出现unassigned shards根本原因?
https://elasticsearch.cn/question/4136
medcl回复:
原因肯定是有很多啊,但是要看具体每一次是什么原因引起的,对照表格排查未免不太高效,怎么办?
es 早已帮你想好对策,使用 Cluster Allocation Explain
API,
会返回集群为什么不分配分片的详细原因,你对照返回的结果,就可以进行有针对性的解决了。
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/cluster-allocation-explain.html
铭毅天下实战:
GET /_cluster/allocation/explain
{
"index": "test",
"shard": 0,
"primary": false,
"current_state": "unassigned",
"unassigned_info": {
"reason": "CLUSTER_RECOVERED",
"at": "2018-05-04T14:54:40.950Z",
"last_allocation_status": "no_attempt"
},
"can_allocate": "no",
"allocate_explanation": "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions": [
{
"node_id": "ikKuXkFvRc-qFCqG99smGg",
"node_name": "test",
"transport_address": "127.0.0.1:9300",
"node_decision": "no",
"deciders": [
{
"decider": "same_shard",
"decision": "NO",
"explanation": "the shard cannot be allocated to the same node on which a copy of the shard already exists [[test][0], node[ikKuXkFvRc-qFCqG99smGg], [P], s[STARTED], a[id=bAWZVbRdQXCDfewvAbN85Q]]"
}
]
}
]
}
问题3:Elasticsearch写入速度越来越慢
https://elasticsearch.cn/question/4112
用sparkstreaming并行写入es,采用的是bulk接口,20s写入一次,当索引刚建立时速度挺快,耗时大概8到12s,而当大概运行半天后,写入速度下降很多,耗时变为18s以上,有时候甚至超过40s,有大哥哥知道是什么问题吗?
if(bulkRequest.numberOfActions()>0)
{
val bulkResponse = bulkRequest.get()
if (bulkResponse.hasFailures) {
println("failed processing bulk index requests " + bulkResponse.buildFailureMessage)
}
}
写入变慢的原因可能有
1.随着写入索引数据增多,单个shard数据量太大(超过50GB),导致写入速度变慢
2.随着数据写入,segment合并变得频繁,es节点负载变高
问题4:ES更新某个字段的值
POST supp_dev/discovery/type/_update
{
"script": "ctx._source.marked = count",
"params": {
"count": 0
}
}
问题5:es中有自动创建了很多索引,怎么禁止?安装了x-pack?
https://elasticsearch.cn/question/4097
方法1:安装了x-pack,这些watcher开头的索引是跟es里watcher监控插件有关。方法1是设置watcher索引保存时间
方法2:action.auto_create_index: false 关闭了自动创建索引。
方法3:禁用watcher功能就行了。
xpack.watcher.enabled: false
问题6:elasticsearch打开和关闭索引详细过程是是什么样子的?
https://elasticsearch.cn/question/4069
打开:
当你打开一个索引时,首先会发生的事情是将主碎片分配给特定节点上存在的最新版本。
Lucene索引将被打开(可能需要时间),并且将重播事务日志。
然后,副本(如果有的话)将被分配并与原分片同步(重复使用具有相同数据的现有节点)。
那么,开放一个指数的成本是多少? 主要的成本是打分片的索引文件(Lucene),并应用事务日志。
您无法真正改变打开Lucene索引所需的时间(除非索引较少的数据/字段),但是您可以在关闭索引之前将flush发送到索引,因此不需要重放事务日志。
关闭:
关闭索引时,除了磁盘大小外,它们不会在群集上占用任何资源。
他们的数据保留在节点上,但是它们不可用于搜索或索引,也没有资源(内存,文件句柄等)。
参考:http://t.cn/Ru3i3Fj
问题7:时间戳怎么在logstash里转为date并替换@timestamp
日志里有个字段 "createTime": "1526402356365" ,把这个转成时间替换到@timestamp,怎么写filter啊
实现:
date {
match =>["time_local","dd/MMM/yyyy:HH:mm:ss","ISO8601"]
target => "@timestamp"
}
time_local 原始日志中的日期时间;后面是你日期格式,可以查询官网
问题8:logstash向es里面导入mysql数据,表字段名称自动变成了小写
用logstash向es里面导入mysql数据的时候,表字段按照驼峰式命名,但是数据导进去之后,字段名称全都变成了小写。哪位大神知道这个是什么情况啊,es是5.5.0版本
es中索引名称不支持大写,包含#,以_开头。具体查看MetaDataCreateIndexService类的validateIndexName方法
public void validateIndexName(String index, ClusterState state) {
if (state.routingTable().hasIndex(index)) {
throw new IndexAlreadyExistsException(new Index(index));
}
if (state.metaData().hasIndex(index)) {
throw new IndexAlreadyExistsException(new Index(index));
}
if (!Strings.validFileName(index)) {
throw new InvalidIndexNameException(new Index(index), index, "must not contain the following characters " + Strings.INVALID_FILENAME_CHARS);
}
if (index.contains("#")) {
throw new InvalidIndexNameException(new Index(index), index, "must not contain '#'");
}
if (index.charAt(0) == '_') {
throw new InvalidIndexNameException(new Index(index), index, "must not start with '_'");
}
if (!index.toLowerCase(Locale.ROOT).equals(index)) {
throw new InvalidIndexNameException(new Index(index), index, "must be lowercase");
}
int byteCount = 0;
try {
byteCount = index.getBytes("UTF-8").length;
} catch (UnsupportedEncodingException e) {
// UTF-8 should always be supported, but rethrow this if it is not for some reason
throw new ElasticsearchException("Unable to determine length of index name", e);
}
if (byteCount > MAX_INDEX_NAME_BYTES) {
throw new InvalidIndexNameException(new Index(index), index,
"index name is too long, (" + byteCount +
" > " + MAX_INDEX_NAME_BYTES + ")");
}
if (state.metaData().hasAlias(index)) {
throw new InvalidIndexNameException(new Index(index), index, "already exists as alias");
}
if (index.equals(".") || index.equals("..")) {
throw new InvalidIndexNameException(new Index(index), index, "must not be '.' or '..'");
}
}
https://elasticsearch.cn/question/4138
感谢各位的热心帮助,找到了问题的原因,我是使用logstash同步mysql数据的,
因为在jdbc.conf里面没有添加 lowercase_column_names => "false"
这个属性,所以logstash默认把查询结果的列明改为了小写,同步进了es,所以就导致es里面看到的字段名称全是小写。
最后总结:es是支持大写字段名称的,问题出在logstash没用好,需要在同步配置中加上 lowercase_column_names => "false" 。
问题9:主节点的数据量,乘父节点数,小于总数据量?
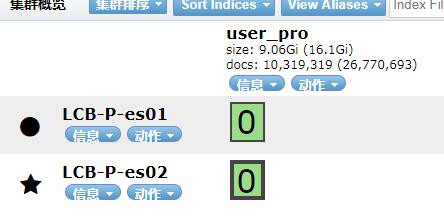
如图:当前索引为一个副本,一个节点。
当前节点为:1031多w,按理说总数据量为2062w数据,但为何总数据量显示为:2677多w,远远大于公式计算出来的数据?
回答:
你的索引里发生过文档删除,就可能会出现上面的情况。
比如你往一个索引里插入了6条记录,删除了其中的一条。那么使用/_count,你会得到结果5条。
其实ES删除文档时不是真正删除,而只是会做个标记marker。所以索引里实际还存在6个文档。
什么时候真正删除?
ES用的是Luncene 管理索引。Luncene 会在满足一定条件时进行merge操作,其中会把所有标记了delete的文档真正的删除并合并segment。
什么时候deleted不为0?
如果删除了文档,但是还没有merge,比如这个索引,主本5条记录,实际18条数据。
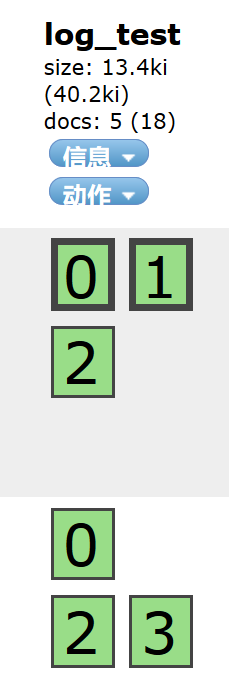
执行
curl -XGET '192.168.3.100:9200/log_test/_stats?total&pretty'
你会发现:
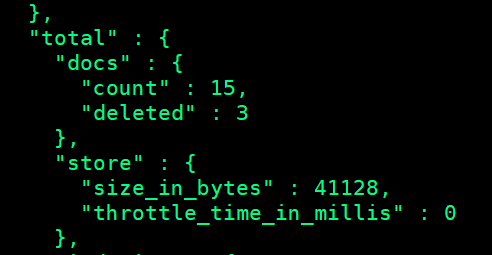
强制做merge,将文档真正删除
POST /log_test/_optimize?only_expunge_deletes=true&wait_for_completion=true
你会发现文档数就变成了
5/15
参考源码
public class DocsStats implements Streamable, ToXContent {
long count = 0;
long deleted = 0;
public DocsStats() {
}
public DocsStats(long count, long deleted) {
this.count = count;
this.deleted = deleted;
}
......
}
问题10:请问查询人与人之间合作度,这种聚合查询怎么写呢?
请问,我想查询出来,与 张三合作超过5本书的人 ,
我的数据结构是:
======================
{
"书名":“abc”
“authors”:[
{"作者":“张三”},
{"作者":“李四”},
{"作者":“王五”}
]
}
=====================
{
"书名":“def”
“authors”:[
{"作者":“张三”},
{"作者":“李四”}
]
}
{
"order": 10,
"template": "fetch_example*",
"settings": {
"index": {
"number_of_shards": "1"
}
},
"mappings": {
"type": {
"_all": {
"enabled": false
},
"properties": {
"书名":{
"type":"string",
"index": "not_analyzed"
},
"作者":{
"type":"string",
"index": "not_analyzed"
},
"authors":{
"type":"nested",
"properties":{
"作者":{ "type":"string",
"index": "not_analyzed"}
}
}
}
}
},
"aliases": {}
}
{
"size": 0,
"query": {
"nested": {
"path": "authors",
"query": {
"term": {
"authors.作者": {
"value": "张三"
}
}
}
}
},
"aggs": {
"1": {
"nested": {
"path": "authors"
},
"aggs": {
"2": {
"terms": {
"field": "authors.作者",
"size": 10
},
"aggs": {
"filter": {
"bucket_selector": {
"buckets_path": {
"the_doc_count": "_count"
},
"script": "the_doc_count > 2"
}
}
}
}
}
}
}
}
问题11:ES聚合如何实现SQL中的having语句
像SQL里面的HAVING语句来过滤聚合结果(例如根据color聚合avg price,要求avg price要大于4000)
采用post_filter好像实现不了
https://elasticsearch.cn/question/4214
回复:
post_filter 是对原始数据做过滤的,不会对聚合起作用,它存在的意义是先做全局的聚合,然后再过滤详细数据,比如一次性获取所有分类的聚合信息和某个分类下的详细数据。可以看官方的示例。
你的需求用 pipeline aggregation 中的 bucket selector 可以实现,看下官方的例子好了
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline-bucket-selector-aggregation.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_post_filter.html
GET cars/_search
{
"size": 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"bucket_filter": {
"bucket_selector": {
"buckets_path": {
"avgPrice": "avg_price"
},
"script": "params.avgPrice>4000"
}
}
}
}
}
}
问题12:用logstash读取kafka里的数据怎么能从头开始
https://elasticsearch.cn/question/4209
kafka {
bootstrap_servers => "localhost:9092"
topics => "test"
group_id => "logstash"
auto_offset_reset => "earliest"
}
我的配置是这样,我想要重新启动logstash的时候,能重新消费kafka,或者是能接着把没有消费完的数据进行消费,需要每次修改group_id吗
是的,offset commit 只有一次机会,一旦运行过了就记录了,此时你要重新从头消费的话,要么你手动去 zk 把 offset 改了,要么改 group,此时当然是改 group id方便了。
至于重启的时候继续消费,默认就是这样的运行方式,不需要再改 group。
问题13:logstash导入mysql上亿级别数据的效率问题
https://elasticsearch.cn/question/2891
请教各位:
当mysql表中数据存在上亿条时,使用logstash同步表中数据到ES,而且使用jdbc_paging_enabled分页时,其是直接将原sql语句作为子查询,拼接offset和limit来实现。当查询出的结果集较大时存在深度分页瓶颈。
可以看到一次查询花费几千秒。
当查询出的结果集较小时,比如几百万时,则只要花费几十秒。
请问各位,有什么好办法提高logstash在数据量较大情况下的查询效率吗,
现在测试表中生成了一亿条左右数据,但是当logstash从mysql中查询数据实在是太慢了,几千秒才能查出一次数据,请问有什么好的方式增加速度吗?
或者有没有大神做过类似场景的测试,请大神指教。
实现方法:
我也遇到你同样问题,可以这么解决:
1.给updated_ts时间字段加上索引。
2.分批处理原则
(1)你的SQL:每批处理100000个
SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000;
(2)logstash分页的时候每次处理50000个
SELECT * FROM (SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000) AS t1 LIMIT 50000 OFFSET 0;
SELECT * FROM (SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000) AS t1 LIMIT 50000 OFFSET 50000;
(3)处理两次就写一个最后一条记录的updated_ts时间到指定文件。下一个定时任务启动的时候进行循环处理就行,因为每批处理updated_ts都会改变
问题14 :Grok Debugger官网的在线调试地址:
http://grokdebug.herokuapp.com/
Grok Debugger中文站:
http://grok.qiexun.net/
自己本地搭建:
http://blog.51cto.com/fengwan/1758845
问题15 es查询结果数量在两个数之间切换
集群有三个节点,5个主分片1个副本分片。
同一个条件(或者直接match_all)连续两次查询出来hits['total']也就是总数不一样,在两个数之间切换
请问下有人知道是什么原因吗?
回复:
你 es 版本是?你用 preference 参数限制下主副分片,看下是否是主副分片问题。不过按理应该不会这样才对。
另外你 restart 一下集群,看是否会变正常。
6.0版本 用preference看了确实有一个值是主分片 另一个值是副本分片
问题16 ES数据不能实时更新
es 数据在被修改之后 再发起查询还是会查到未修改前的数据
es服务版本 5.3.3,
es pom版本2.1.0,jest版本2.3,
我使用的是jest httpclient方式,就是前端每次调一个修改数据的接口之后然后回调查询接口,结果就是会查到老数据(就是查到的那条数据是没有被修改的样子),后来尝试了在回调查询的时候增加了一点延时(500ms),效果提升了一点,可以成功查到修改后数据的样子了,但是不太稳定,时而成功时而失败,被这个问题困惑了好久,求解决!
回复:
1)refresh时间,默认1s
2)默认是1秒可见。如果你的需求一定要写完就可见,那在写的时候增加refresh参数,强制刷新即可。但强烈建议不这么干,因为这样会把整个集群拖垮。
问题17 elasticsearch如何查询所有index?
https://elasticsearch.cn/question/4263
GET _cat/indices
详细参考:
https://stackoverflow.com/questions/17426521/list-all-indexes-on-elasticsearch-server
curl 'localhost:9200/_cat/indices?v'
问题18:在6.2版本中提到了一个Bucket Script Aggregation 的功能:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline-bucket-selector-aggregation.html
用它实现了如下SQL
select company_id, count(1) from xxx_table where company_id between A and B group by company_id having count(1) > 1;
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"company_id": {
"gte": A,
"lte": B
}
}
}
}
},
"aggs": {
"count_by_company_id": {
"terms": {
"field": "company_id"
},
"aggs": {
"distinct_id": {
"cardinality": {
"field": "company_id"
}
},
"id_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"value": "distinct_id"
},
"script": "params.value> 1"
}
}
}
}
}
}
问题19:Filter中term和range不能同时用么?
{
"query": {
"bool": {
"filter": [
{
"term": {
"name": "kevin"
}
},
{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
]
}
}
}
问题20:跨集群数据同步方案讨论
https://elasticsearch.cn/question/4294
虽然ES本身就是一个分布式系统,但在生产实践中,往往还是让所有ES节点落在单机房内,各个数据中心之间,采用其他方式来同步数据。那么如何来做数据同步,以及如何确保数据一致性,就成了不得不面对的问题。现提出我知道的方案,供大家讨论,也希望大家伙能分享自己的方案~~~
方案一,双写
在数据写入ES时,通过MQ或者其他方式实现数据双写或者多写,目前很多MQ都有数据持久化功能,可以保障数据不丢;再结合ES各种状态码来处理数据重复问题,即可实现多中心数据的最终一致。
方案二,第三方数据同步
例如使用mysql的主从同步功能,在不同数据中心之间,从本机房的mysql同步数据到ES,依托mysql数据一致性来保障ES数据一致。datax,StreamSet均提供了类似功能。
方案三,基于ES translog同步
读取translog,同步并重放,类似于mysql binlog方式。看起来这种方式最干净利落,但涉及到ES底层代码修改,成本也较高,目前已有的实践:。[/url]
抛砖引玉~~~
关于方案1,有兴趣试试我的这个小工具么,目前支持多集群多写了,自带本地磁盘队列,支持扩展外部 MessageQueue,如 Kafka,RabbitMQ。地址: https://github.com/medcl/elasticsearch-proxy
方案2最复杂,需要从原始数据开始进行处理,需要从 MySQL 到 ES 的文档转换,MySQL 的数据表达方式往往不够直观,使用起来不是很方便。
方案3,目前 ES 的 Translog 不能直接读取,修改底层代码产生新的分支,不具实际可行性。
还有方案么,有的:
方案4,ES 正在实现新的 CCR,cross cluster replication, 基于底层 sequence id 机制,实现的 Changes API,一个集群可被另外一个集群或是本集群“订阅”,从而可以实现数据复制,进行同步,可以是跨数据中心集群也可以本地集群的数据同步。
问题21:logstash同步乱码
https://elasticsearch.cn/question/4325
mysql 中的数据 logstash-input-jdbc 导入es mysql列名是中文,导入es后,字段名成了乱码,求解
处理中文乱码问题
codec => plain { charset => "UTF-8"}
在input中 你加这个了么
问题22:Elasticsearch 使用IK分词,如何配置同义词?
参考链接:https://elasticsearch.cn/question/29
问题23:ElasticSearch如何先聚合后过滤?
https://elasticsearch.cn/question/656
场景:按日期纬度一个数据报表,字段有date_str, shop_code, new_user_count, active_count。字段分别含义:日期(精确到日)、车商id、 新增用户、活跃用户数;
先需先按照时间范围查询,车商id分组,new_user_count字段取sum。然后在聚合后过滤new_user_count字段sum结果>30的所有车商id,以及sum结果。
类似sql:select shop_code, sum(new_user_count) from A where date_str >= ? and date_str <= ? group by shop_code having sum(new_user_count) > 30;
ps:不知道es有没有实现先聚合然后过滤的功能。希望大神们能解惑,谢了。
在6.2版本中提到了一个Bucket Script Aggregation 的功能:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline-bucket-selector-aggregation.html
用它实现了如下SQL
select company_id, count(1) from xxx_table where company_id between A and B group by company_id having count(1) > 1;
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"company_id": {
"gte": A,
"lte": B
}
}
}
}
},
"aggs": {
"count_by_company_id": {
"terms": {
"field": "company_id"
},
"aggs": {
"distinct_id": {
"cardinality": {
"field": "company_id"
}
},
"id_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"value": "distinct_id"
},
"script": "params.value> 1"
}
}
}
}
}
}
问题24:es升级后分片不分配
https://elasticsearch.cn/question/4271
按照官网说的平滑升级,从5.3版本升级到5.4版本,升级之前禁用分片分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
升级好后打开了分片分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}
但是今天早上过来一看 发现今天的分片都没分配
请各位大佬帮忙解答下这是什么情况,我是参考着这篇文档来做的:
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/restart-upgrade.html
思路1:如果确认集群的allocation已经打开,可以用
GET /_cluster/allocation/explain
得到分片无法分配的原因,然后据此排查问题。
思路2:看一下集群的设置。 另外查一下master结点的日志,看看有报什么异常。
GET /_cluster/settings
根本原因:原来是因为我还没等到集群状态变成green就操作下一个节点了。
问题25:自动生成不同索引,不同索引不同配置参数
https://elasticsearch.cn/question/4330
需求:
1、es自动生成2个不同的索引:logstash-和fangzhen-,logstash-索引是logstash默认生成的,fangzhen-是logstash output elasticsearch配置index生成的。
2、2个不同的索引配置不同的参数。
问题:
请问各位es大神,这样可否实现?
目前想到的解决方案:
1、生成不同索引都以logstash开头,配置参数是template指定logstash-*
2、手动生成索引,并附带settings参数。
解决方案:用 template 匹配不同的 index,然后应用不同的配置
问题26:那一个分片下面一遍多少个文档合适呢?有没有好的计算方法!
参考实现:https://blog.csdn.net/laoyang360/article/details/78080602
问题27:ES节点都在,也是green状态,出现大量的pending_tasks,应该如何进行处理,有没有处理路程
https://elasticsearch.cn/question/4333
ES集群10多个节点,接连出现两次存在大量的pendin_tasks任务,任务等级为HIGH,导致不行新建索引,备份等操作
步骤1:
先要看看这些pending_tasks是什么才好进一步分析。
如果集群状态为green,没有数据shard在recovery,比较容易产生pending_tasks的是put_mappings这类操作。
特别是如果用了动态mapping的情况下,比较容易因为新字段的写入产生mapping更新任务。
步骤2:
动态mapping非常容易引起性能问题,特别是集群比较大的情况下,容易因为大量的mapping更新任务会导致master过载。
并且动态mapping也容易因为脏数据的写入产生错误的字段类型。 我们的做法是完全禁用动态mapping,在索引的mapping设置中增加"dynamic": "false" 这个选项即可。
集群的索引字段类型都需要预先设计好,数据必须严格按照设计的类型写入,否则会被reject。
注意:貌似 false 的话好像是不自动生成字段, strict 好像才会 reject
步骤3:
:去看ES服务端的日志,应该会显示put mapping是在哪个索引的哪个字段
其他方法:
GET /_cat/pending_tasks?v
查看一下究竟是哪些线程忙不过来,再进一步分析。
问题28 mysql 中的数据 logstash-input-jdbc 导入es mysql列名是中文,导入es后,字段名成了乱码,求解
处理中文乱码问题
codec => plain { charset => "UTF-8"}
在input中 你加这个了么?
问题29 “通过profile查看,发现耗时主要在status字段的build_scorer这个阶段” profile 是个什么工具啊。谢谢
https://elasticsearch.cn/article/573
不是什么外部工具,就是ES的Query DSL那你有一个可选的参数 "profile": true,
开启以后,查询结果会打印底层Luene查询执行的步骤和耗时。
问题30:在Elasticsearch 6.1.3版本中,发现translog文件过多导致异常?
Wood大叔回复:
我感觉这个bug和6.x引入的translog retention策略有关系。
为了加速热索引的recovery, 6.x开始对于translog不再是flush以后立即清除,而是保留一定的大小,由以下两个参数控制:
index.translog.retention.size #默认512mb
index.translog.retention.age #默认12h
保留一定量的translog的目的,是为了出现热索引recovery情况的时候,借助保留的translog和seqno (也是6.x引入的,记录已经提交到lucene的文档序列号), 可以免去跨结点的shard文件拷贝消耗,直接从translog快速恢复数据。
由于保留了一定时间的translog不清除,那么判断是否需要flush,以及flush的时候清除哪些文件的的条件就复杂了一些。需要比较哪些translog里的doc已经全部提交,哪些还未提交或者部分提交。 这些判断是通过比较translog里保留的seqno和local checkpoint记录的seqno来做出的。
但是这个特性实现上看起来有些bug,在一些极端场景造成了flush死循环。 官方尝试在6.1.3/6.2.0修复这个问题( pull/28350 ), 但问题并未真正解决。
在用户报告问题以后,官方又发布了6.2.4 (pull/29125), 经过我们生产集群的验证,升级到6.2.4以后再未遇到类似的问题。
问题31:求教 如何在indea中调试elasticsearch源码
这几天想自己调试一些es,看看大概工作流程,请教一下如何调试 es版本为6.2
https://elasticsearch.cn/question/4354
- IDEA里建好ES的工程,成功编译和打包。
- 创建一个remote target
- 将 jdwp的参数拷贝到ES的启动命令里,重启ES
- IDEA里设好断点,启动remote target
问题32:如何同时根据 销量和浏览人数进行相关度提升
https://elasticsearch.cn/question/4345
针对商品,例如有
销量 浏览人数
A 10 10
B 20 20
C 30 30
想要有一个提升相关度的计算,同时针对销量和浏览人数
例如oldScore*(销量+浏览人数)
field_value_factor好像只能支持单个field
求大神解答
function_score 评分查询支持多个函数,同时针对销量和浏览人数可以很简单的实现,结构类是:
{
"query": {
"function_score": {
"query": {},
"functions": [] //这里支持多个函数
}
}
}
最终:使用script score解决了问题
问题33 logstash-filter-elasticsearch的简易安装
https://elasticsearch.cn/article/643
不同版本的logstash集成的插件不一样,在5.6版本就未集成logstash-filter-elasticsearch插件,所以需要自己安装。
官方提供的方法因为需要联网,并且需要调整插件管理源,比较麻烦,针对logstash-filter-elasticsearch插件,使用下面这种方式安装。
logstash-filter-elasticsearch插件安装
1、在git上下载logstash-filter-elasticsearch压缩包,logstash-filter-elasticsearch.zip,
2、在logstash的目录下新建plugins目录,解压logstash-filter-elasticsearch.zip到此目录下。
3、在logstash目录下的Gemfile中添加一行:
gem "logstash-filter-elasticsearch", :path => "./plugins/logstash-filter-elasticsearch"
4、重启logstash即可。
此方法适用logstash-filter-elasticsearch,但不适用全部logstash插件。
问题34:elasticsearch如何保证成功
https://elasticsearch.cn/question/4365
如何保证一个正确的插入文档请求
一定成功
在主分片上面执行请求。如果成功了,它将请求并行转发到其他节点的副本分片上。
一旦所有的副本分片都报告成功, 主分片所在的节点将向协调节点报告成功,协调节点向客户端报告成功。
es数据写入采用的是同步方式。官网写的很清楚
官网的原话:
The index operation only returns after all active shards within the replication group have indexed the document (sync replication).
问题35:某个节点线程池爆了,导致整个服务响应很慢
https://elasticsearch.cn/question/4350
如标题:
我们有个节点的search线程池爆了,导致整个搜索服务响应很慢,不知道大家有没碰到过这种情况:有个疑问是:
1,这种情况下,集群不会把这台机器给剔除掉么?或者有什么自动恢复机制么?
2,对应用层面,能做哪些优化么?
回复:
1不挂的话应该不会走剔除
2线程池和队列大小做下配置优化。
顺着楼上大牛的思路,现有业务场景下,评估一下你的线程池模型是否合理
举个例子:
一个节点假设配置search线程池为16,队列长度为1000, 一个线程处理一个搜索请求处理耗时是20ms,那么一个线程一秒可以处理50个请求。
那么理论上16个线程一秒可以处理900个请求,1000+16的线程队列大小是能够容纳qps为900的业务的(当然这是理论上,没有考虑的线程上下文切换,网络原因,内存GC导致stw等等,所以实际值肯定比这个低)。
线程数我觉得就核数两倍好了,最多2.5倍,太多了cpu上来反而影响效率(这个看实际情况,假设写少读多可以适当平衡这些线程数)
我认为可以参照如下公式得出
queueSize < thread(1s1000/cost)
然后我提出我的思考方式,我觉得你应该优化一下你的查询。是不是存在耗时很高的查询请求。
如上面分析的,假设你一个查询耗时200ms,那么你16个线程的处理能力瞬间变成 < 90 req/s,如果还有耗时更高的耗时呢,
可以先优化线程模型,顺便捕捉下慢查询。
问题36:elasticsearch安装x-pack之后,filebeat直接传数据到es,报错,提示链接不上,请问这个怎么解决?
6.2版本
https://elasticsearch.cn/question/4397
已经找到解决办法了,
创建一个角色
POST _xpack/security/role/filebeat_writer{ "cluster": ["manage_index_templates", "monitor"], "indices": [ { "names": [ "filebeat-*" ], "privileges": ["write","create_index"] } ]}
创建一个用户
POST /_xpack/security/user/filebeat_internal{ "password" : "x-pack-test-password", "roles" : [ "filebeat_writer"], "full_name" : "Internal Filebeat User"}
filebeat中添加对应的配置
output.elasticsearch: hosts: ["localhost:9200"] index: "filebeat" username: "filebeat_internal" password: "x-pack-test-password"

加入知识星球,更短时间更快习得更多干货!