今天我要利用request库和正则表达式抓取猫眼电影Top100榜单。
运行平台: Windows
Python版本: Python3.6
IDE: Sublime Text
其他工具:Chrome浏览器
1. 抓取单页内容
浏览器打开猫眼电影首页,点击“榜单”,然后再点击"TOP100榜",就能看到想要的了。
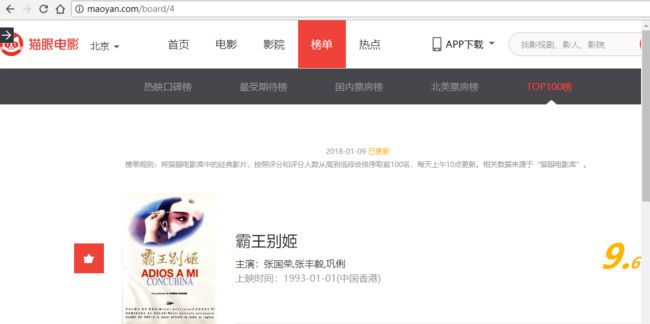
1猫眼电影榜单页
接下来通过代码来获取网页的HTML代码。
# 如果电脑里没有安装requests,使用:pip install requests 进行安装
import requests
from requests.exceptions import RequestException
def get_one_page(url):
'''
获取网页html内容并返回
'''
try:
# 获取网页html内容
response = requests.get(url)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()
运行结果如下:
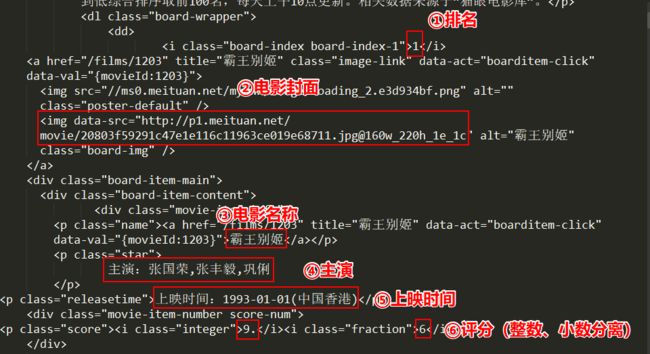
2抓取内容截图
2. 正则表达式提取有用信息
在上图中,已经标注出我们将要提取的内容,下面用代码实现:
import re
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">'
+ '(.*?).*?"star">(.*?).*?releasetime">(.*?)'
+ '.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
# 修改main()函数
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
运行结果如下:
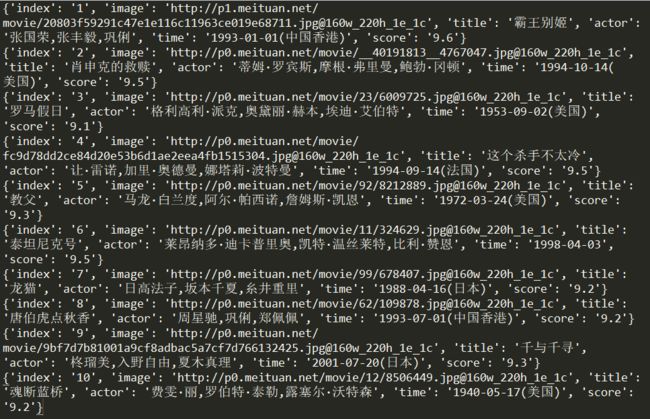
3获取网页信息结果
3. 保存信息
获取电影信息之后,要保存起来留用。要保存的有文本信息和电影封面。
import os
def write_to_file(content):
'''
将文本信息写入文件
'''
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def save_image_file(url, path):
'''
保存电影封面
'''
ir = requests.get(url)
if ir.status_code == 200:
with open(path, 'wb') as f:
f.write(ir.content)
f.close()
# 修改main()函数
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
# 封面文件夹不存在则创建
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'], 'covers/' + '%03d'%int(item['index']) + item['title'] + '.jpg')
下面为保存结果:

4文本保存结果
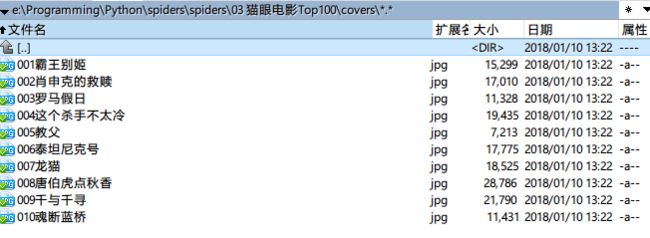
5封面保存结果
4.下载TOP100所有电影信息
通过点击标签页发现只是URL变化了:
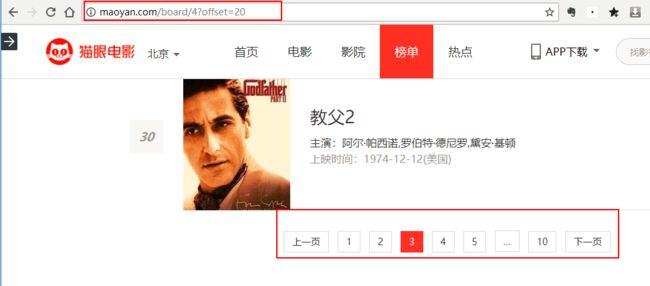
6不同页面点击效果
修改main函数以动态改变URL:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
# 封面文件夹不存在则创建
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'], 'covers/' + '%03d'%int(item['index']) + item['title'] + '.jpg')
if __name__ == '__main__':
for i in rang(10):
main(i * 10)
到此我们已经将TOP100的电影信息和封面全部得到了。
5.多线程抓取
此次抓取的数据不算多,但是为了学习,使用多进程进行抓取,以应对以后大量的数据抓取。
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool()
pool.map(main, [i*10 for i in range(10)])
下面为普通抓取和多进程抓取的时间对比:

7多进程速度对比
以下为完整代码:
#-*- coding: utf-8 -*-
import re
import os
import json
import requests
from multiprocessing import Pool
from requests.exceptions import RequestException
def get_one_page(url):
'''
获取网页html内容并返回
'''
try:
# 获取网页html内容
response = requests.get(url)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">'
+ '(.*?).*?"star">(.*?).*?releasetime">(.*?)'
+ '.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
'''
将文本信息写入文件
'''
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def save_image_file(url, path):
'''
保存电影封面
'''
ir = requests.get(url)
if ir.status_code == 200:
with open(path, 'wb') as f:
f.write(ir.content)
f.close()
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
# 封面文件夹不存在则创建
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'], 'covers/' + '%03d'%int(item['index']) + item['title'] + '.jpg')
if __name__ == '__main__':
# 使用多进程提高效率
pool = Pool()
pool.map(main, [i*10 for i in range(10)])

微信公众号