写在前面
网上有非常多非常好的文章,比如这篇:机器学习(一)——K-近邻(KNN)算法
再深一点,还有822成员开心同学的这篇:用KNN解决非线性回归问题
不过我在学习的时候,概念读得很快,但是没有直接认识,不理解,这时候就要借助读代码去直接体悟。但是往往,入门如我,语言学的又不是很好,就很想代码后面注释的详细一点。其实详细点也不用,最好是直接把数据怎么流动的展示给我,我先不读代码,我想先知道这个KNN是怎么工作的。那我的这篇文章可能做的就是这样一个工作。
什么是KNN
KNN就是K邻近,什么是K邻近呢,就是离我要预测的这个数据最近的K个数据中大部分都是什么标签,那么我这个数据就是这个标签(不懂去戳第一个链接)。注意,不是我离谁最近我就是谁,而是在我指定的一个范围内,谁最多我是谁。KNN就是小众里的随大流。
一个例子
我本来有[10, 8], [12, 13], [3, 4], [4, 5]这样四个点,标签分别是B、A、A、B,这是已知的。现在又来了一个点[0, 1],我问你,这个点是A还是B?KNN就可以来解决这样的问题。我们从图上来看一下:
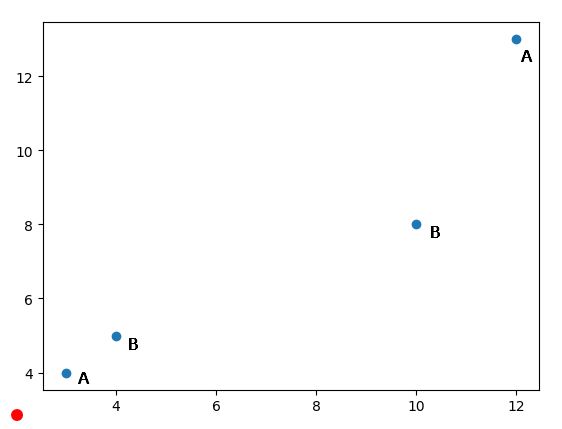
红色的点就是[0, 1],直观上来看,一看它离A最近,你可能会说它是A,不是这样的。我们说KNN算法是一个范围内的,谁最多我是谁,所以你应该先问:范围是多少。这个范围,就是K。比如,K是2,那意思就是离它最近的2个点,在这个例子里是左下角的两个点,一个A,一个B,那我们取最近的那个,就是A。如果K是3,那就是最近的3个点,一个A,两个B,随大流,那[0, 1]这个的标签就是B,尽管它离A最近。
好了,这样一个简单的要求,怎么落实到程序上?我们来看代码:
代码
不用说,我们得先有这四个点,而且还得有对应的标签:
# -*- coding: utf-8 -*-
from numpy import *
import operator
import matplotlib.pyplot as plt
# 创建数据集和标签,Python可以返回两个值
def createDataSet():
group = array([[10, 8], [12, 13], [3, 4], [4, 5]])
labels = ['B', 'A', 'A', 'B']
return group, labels
group, labels = createDataSet()
group长这个样子:
[[10 8]
[12 13]
[ 3 4]
[ 4 5]]
labels是这样的:
['B', 'A', 'A', 'B']
注意它俩的类型是不一样的,group的类型是:numpy.ndarray,而labels是list。
现在我们要求新进来的这个点[0, 1]分别到四个点的距离,你首先想到的一定是写个for循环挨个算一遍,但是这里我们用一个很巧妙的方法去算。我们把[0, 1]也写成一个矩阵,让两个矩阵做欧氏距离,这里不科普什么是欧氏距离,示意图如下:

但是最后得出的这个矩阵不好排序,所以我们让它成为一个numpy.ndarray,这样就可以方便的排序。代码这里是一个非常迷惑人的点,你可以翻下面的代码,这句是这么写的:sortedDistIndicies = distance.argsort() 。而这个 sortedDistIndicies 长这样:[2 3 0 1]。它是什么意思呢?意思就是,最大的数是之前array中的第2个,第二大的数是之前array中的第3个,第三大的数是之前array中的第0个,第四大的数是之前array中第1个。
这样的好处就是,如果你的K值取3,就是要挑4个数据的前3个数据,那么你只要找sortedDistIndicies 中前三个数值,按照这三个数值告诉你的位置回到标签集里找对应标签,看看A多还是B多就行了。
代码如下:
# K-近邻算法
def classify0(inX, dataSet, labels, k): # 参数k表示用于选择最近邻居的数目
dataSetSize = dataSet.shape[0] # 返回数据集的行数
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# print 'diffMat: ', diffMat
sqDiffMat = diffMat ** 2 # ** 代表n此方
sqDistance = sqDiffMat.sum(axis=1)
distance = sqDistance ** 0.5
sortedDistIndicies = distance.argsort() # 排序
print "sortedDistIndicies: ", sortedDistIndicies
classCount = {} # 注意,这是一个字典
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1),
reverse=True) # 排序,此处的排序为逆序,即按照从最大到最小次序排序
return sortedClassCount[0][0]
最后为什么要返回 sortedClassCount[0][0] ?假设,你K取3,最近的三个点里有2个B、1个A,它在sortedClassCount中是这样显示的: [('B', 2), ('A', 1)]。sortedClassCount[0] 是 ('B', 2),sortedClassCount[0][0]就是‘B’了。
把代码复制粘贴到你的编译环境里,最后加一行打印试一试吧:
print classify0([0, 1], group, labels, 3)
我们的822,我们的青春
欢迎所有热爱知识热爱生活的朋友和822实验室一起成长,吃喝玩乐,享受知识。