线性回归模型尽管是最简单的模型,但它却有不少假设前提,其中最重要的一条就是响应变量和解释变量之间的确存在着线性关系,否则建立线性模型就是白搭。然而现实中的数据往往线性关系比较弱,甚至本来就不存在着线性关系,机器学习中有不少非线性模型,这里主要讲由线性模型扩展至非线性模型的多项式回归。
多项式回归
多项式回归就是把一次特征转换成高次特征的线性组合多项式,举例来说,对于一元线性回归模型:
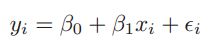
一元线性回归模型
扩展成一元多项式回归模型就是:
一元多项式回归模型
这个最高次d应取合适的值,如果太大,模型会很复杂,容易过拟合。
这里以Wage数据集为例,只研究wage与单变量age的关系。
> library(ISLR)
> attach(Wage)
> plot(age,wage) # 首先散点图可视化,描述两个变量的关系
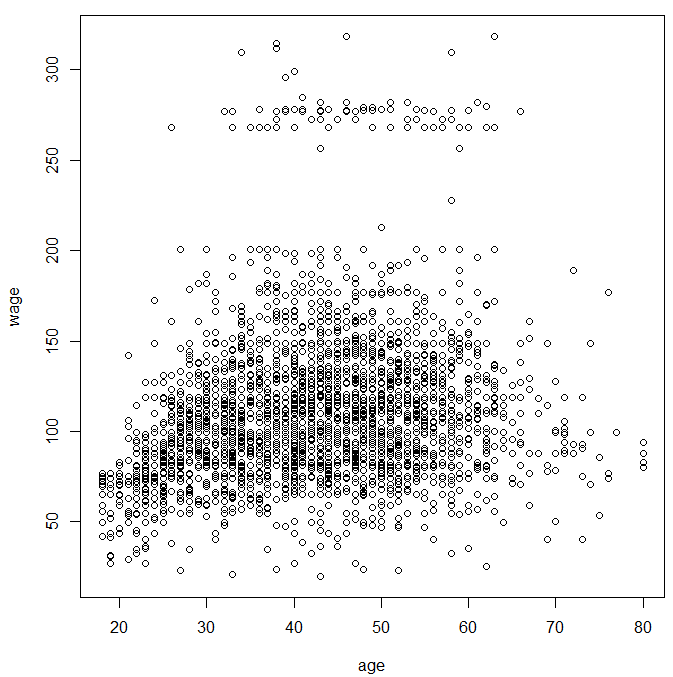
age vs wage
可见这两条变量之间根本不存在线性关系,最好是拟合一条曲线使散点均匀地分布在曲线两侧。于是尝试构建多项式回归模型。
> fit = lm(wage~poly(age,4),data = Wage) # 构建age的4次多项式模型
>
> # 构造一组age值用来预测
> agelims = range(age)
> age.grid = seq(from=agelims[1],to=agelims[2])
> preds = predict(fit,newdata = list(age=age.grid),se=T)
> se.bands = cbind(preds$fit+2*preds$se.fit,preds$fit-2*preds$se.fit) # 构建预测值的置信区间
>
> plot(age,wage,xlim=agelims,cex=0.5,col="darkgrey")
> title("Degree-4 Polynomial",outer = T)
> lines(age.grid,preds$fit,lwd=2,col="blue") # 多项式回归预测曲线
> matlines(age.grid,se.bands,lwd=2,col = "red",lty=3) # 置信区间曲线
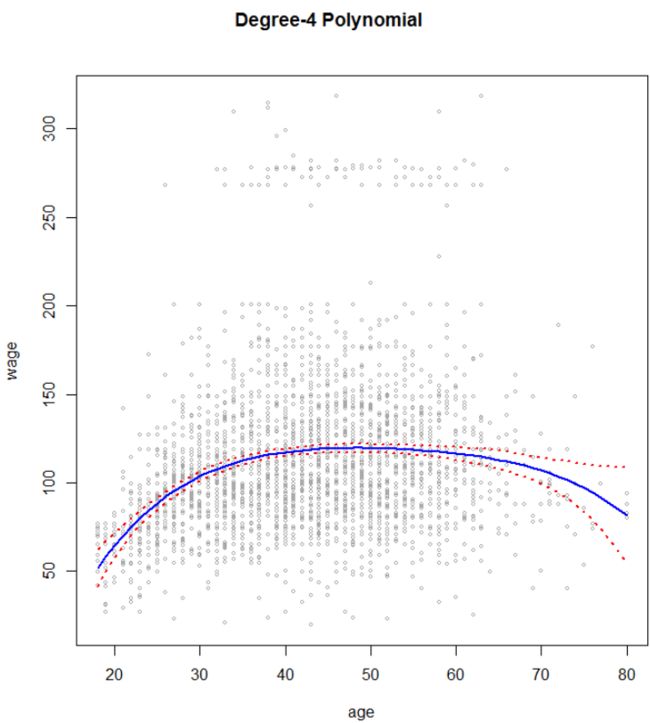
4次多项式回归模型
从图中可见,采用4次多项式回归效果还不错。那么多项式回归的次数具体该如何确定?
在足以解释自变量和因变量关系的前提下,次数应该是越低越好。方差分析(ANOVA)也可用于模型间的检验,比较模型M1是否比一个更复杂的模型M2更好地解释了数据,但前提是M1和M2必须要有包含关系,即:M1的预测变量必须是M2的预测变量的子集。
> fit.1 = lm(wage~age,data = Wage)
> fit.2 = lm(wage~poly(age,2),data = Wage)
> fit.3 = lm(wage~poly(age,3),data = Wage)
> fit.4 = lm(wage~poly(age,4),data = Wage)
> fit.5 = lm(wage~poly(age,5),data = Wage)
> anova(fit.1,fit.2,fit.3,fit.4,fit.5)
Analysis of Variance Table
Model 1: wage ~ age
Model 2: wage ~ poly(age, 2)
Model 3: wage ~ poly(age, 3)
Model 4: wage ~ poly(age, 4)
Model 5: wage ~ poly(age, 5)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 2998 5022216
2 2997 4793430 1 228786 143.5931 < 2.2e-16 ***
3 2996 4777674 1 15756 9.8888 0.001679 **
4 2995 4771604 1 6070 3.8098 0.051046 .
5 2994 4770322 1 1283 0.8050 0.369682
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
可见1-3次模型p值过小,与其他模型有显著差异,说明拟合得不够。4-5次较为合适,也不必更大了。
如果这个方法不好理解,我们依然可以用万能的交叉验证法来选择最合适的次数。
> nrow(Wage)
[1] 3000
> train = sample(1:3000,2000)
> cv.err = vector("numeric",5)
> for(i in 1:5){
+ fit = lm(wage~poly(age,i),data = Wage,subset = train)
+ pred = predict(fit,newdata=Wage[-train,])
+ cv.err[i] = mean((pred-wage[-train])^2)
+ }
> cv.err
[1] 1901.318 1788.861 1782.721 1778.744 1777.856
> plot(1:5,cv.err,type="l")
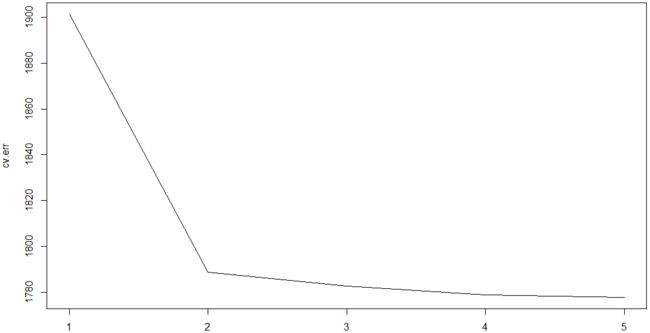
不同次数的测试均方差
可见4是最合适的次数。
既然线性模型可扩展至非线性模型,那么由线性回归模型延伸的逻辑回归模型一样可以扩展至非线性模型。
由上面的散点图可以看出,250是wage的一个分界线,因此可以以wage是否大于250作为二分类问题。
fit = glm(I(wage>250)~poly(age,4),data = Wage,family = binomial) # 以250为界构建二分类逻辑回归模型
agelims = range(age)
age.grid = seq(from=agelims[1],to=agelims[2])
preds = predict(fit,newdata = list(age=age.grid),se=T)
# 将线性项映射到逻辑回归指数项
pfit = exp(preds$fit)/(1+exp(preds$fit))
se.bands.logit = cbind(preds$fit+2*preds$se.fit,preds$fit-2*preds$se.fit)
se.bands = exp(se.bands.logit)/(1+exp(se.bands.logit))
plot(age,I(wage>250),xlim=agelims,type="n")
points(jitter(age),I((wage/250)),cex=.5,pch="|",col="darkgrey")
lines(age.grid,pfit,lwd=2,col="blue")
matlines(age.grid,se.bands,lwd=2,col = "red",lty=3)
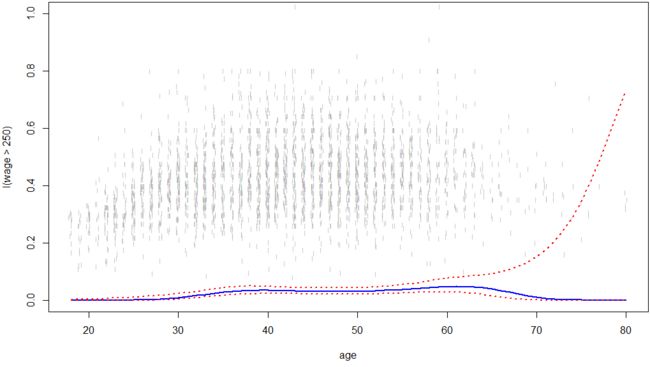
多项式逻辑回归概率曲线
因为样本本身极不均衡,所以置信区间曲线跨度也较大。