EFK介绍
搭建EFK
配置Consul
查看日志
上节课我们学习了BFF的思想,并针对mst-user-service、mst-order-service、mst-goods-service三个服务搭建了一套BFF架构。但到目前为止,我们每个服务的日志依旧分散,这对于日志的收集、管理、检索十分不便。因此,本节课将采用EFK这套日志数据管理解决方案来集中化管理服务日志。
本节课主要内容:
- 介绍EFK是什么
- 如何配置consul
- 如何在Kibana查看日志
#EFK介绍
EFK由ElasticSearch、Fluentd和Kiabana三个开源工具组成。其中Elasticsearch是一款分布式搜索引擎,能够用于日志的检索,Fluentd是一个实时开源的数据收集器,而Kibana 是一款能够为Elasticsearch 提供分析和可视化的 Web 平台。这三款开源工具的组合为日志数据提供了分布式的实时搜集与分析的监控系统。
而在此之前,业界是采用ELK(Elasticsearch + Logstash + Kibana)来管理日志。Logstash是一个具有实时渠道能力的数据收集引擎,但和fluentd相比,它在效能上表现略逊一筹,故而逐渐被fluentd取代,ELK也随之变成EFK。
ELK架构
为了更好的了解EFK的架构,首先,我们先理解下ELK架构。在此之前,
我们需要清楚如下几个概念:
- Log Source:日志来源。在微服务中,我们的日志主要来源于日志文件和Docker容器,日志文件包括服务器log,例如Nginx access log(记录了哪些用户,哪些页面以及用户浏览器、ip和其他的访问信息), error log(记录服务器错误日志)等。
- Logstash:数据收集处理引擎,可用于传输docker各个容器中的日志给EK。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
- Filebeat:和Logstash一样属于日志收集处理工具,基于原先 Logstash-fowarder 的源码改造出来的。与Logstash相比,filebeat更加轻量,占用资源更少
- ElasticSearch:日志搜索引擎
- Kibana:用于日志展示的可视化工具
- Grafana:类似Kibana,可对后端的数据进行实时展示
下图是ELK架构,采用ElasticSearch、Kibana、Grafana、Filebeat来管理Docker容器日志。

由图可知,当我们在Docker中运行应用(application)时,filebeat收集容器中的日志。ElasticSearch收到日志对日志进行实时存储、搜索与分析。我们可在Kibana和Grafana这两个可视化工具中查看日志的操作结果。
EFK架构
Fluentd是一个开源的数据收集器,专为处理数据流设计,使用JSON作为数据格式。它采用了插件式的架构,具有高可扩展性高可用性,同时还实现了高可靠的信息转发。
因此,我们加入Fluentd来收集日志。加入后的EFK架构如图所示。

在这个图中,上下两个框分别表示使用Fluentd前后的日志收集。在第二个框中,Consul能够使用灵活的key/value仓库去存储动态配置。而confd能够使用从consul来的模版管理本地配置。
搭建EFK
1.参考fluentd的官方文档,我们创建EFK项目,项目目录结构如下:

2.配置docker-compose.yml文件
version: '2'
services:
elasticsearch:
image: elasticsearch:5-alpine
volumes:
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro
ports:
- 9200:9200
- 9300:9300
kibana:
image: bitnami/kibana:5-master
volumes:
- ./kibana/config/:/usr/share/kibana/config:ro
depends_on:
- elasticsearch
ports:
- 5601:5601
filebeat:
image: prima/filebeat:5.6
volumes:
- ./filebeat/app.log:/var/log/app.log
- ./filebeat/config/filebeat.yml:/filebeat.yml
depends_on:
- elasticsearch
nginx:
image: nginx:1.12-alpine
volumes:
- ./nginx/nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- 8080:80
logging:
driver: fluentd
options:
fluentd-address: localhost:5140
fluentd-async-connect: 'true'
tag: nginx.backend
fluent:
image: demo/fluentd:v0.14
environment:
FLUENTD_CONF: fluent.conf
ports:
- 5140:5140
- 5044:5044
stdin_open: true
tty: true
depends_on:
- elasticsearch
3.下载docker镜像
docker pull elasticsearch:5-alpine
docker pull bitnami/kibana:5-master
docker pull prima/filebeat:5.6
docker pull nginx:1.12-alpine
docker build -t demo/fluentd:v0.14 .
配置Consul
1.启动consul代理
consul agent -dev -node=consul -data-dir=/tmp/consul
启动完成登录http://localhost:8500/
2.在Consul中创建Key/Value
-
fluentd/source:source可定义日志来源。每一个来源配置必须包含类型(type),比如tcp数据输入,或者json类型输入。
@type forward
port 5140
@type beats
metadata_as_tag
@type json
-
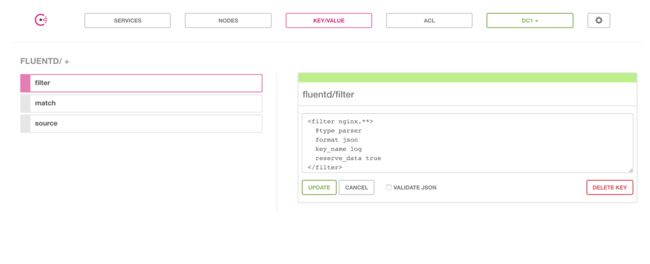
fluentd/filter:filter就是过滤规则,当source.tag复合filter的规则时,就执行这个filter进行过滤行为。我们将数据格式化为json,并过滤出key的名字为log的数据。
@type parser
format json
key_name log
reserve_data true
-
fluentd/match:match是fluentd收到数据后的处理, @type elasticsearch表示把数据输入到elasticsearch上面。
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix nginx
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix app
创建完成如图所示:
4.启动fluentd_workshop,mst-user-service、mst-order-service、mst-goods-service。
查看日志
1.打开http://localhost:5601,进入kibana。
2.创建索引,索引即 Elasticsearch 中的索引。我们需要手动配置。在 Index Pattern 下边的输入框中输入 nginx-*,它是 Elasticsearch 中的一个索引名称开头。
Kibana 会自动检测在 Elasticsearch 中是否存在该索引名称,如果有,则下边出现 “Create” 按钮,如图所示

3.点击左侧 “Discovery” 菜单,同时用postman给mst-user-service发请求,此时,在kibana中可以查看所收集的有关nginx到日志。

Kibana功能众多,例如在“Visualize” 菜单界面可以将查询出的数据进行可视化展示,“Dev Tools” 菜单界面可以让户方便地通过浏览器直接与 Elasticsearch 进行交互,发送 RESTFUL对 Elasticsearch 数据进行增删改查。如果你想要详细的了解它,可以参考它的中文文档http://www.code123.cc/docs/kibana-logstash/v3/panels/trends.html